







Task2——梯度消失、梯度爆炸

5.1 梯度消失与梯度爆炸的概念
深度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘操作,因此如果网络过深。
- 那么如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.
- 那么如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸。
5.2 梯度消失与梯度爆炸的后果
- 梯度消失会导致我们的神经网络中前面层的网络权重无法得到更新,也就停止了学习。
- 梯度爆炸会使得学习不稳定, 参数变化太大导致无法获取最优参数。
- 在深度多层感知机网络中,梯度爆炸会导致网络不稳定,最好的结果是无法从训练数据中学习,最坏的结果是由于权重值为NaN而无法更新权重。
- 在循环神经网络(RNN)中,梯度爆炸会导致网络不稳定,使得网络无法从训练数据中得到很好的学习,最好的结果是网络不能在长输入数据序列上学习。
5.3 梯度消失与梯度爆炸的原因
我们在这以一个例子来说明:

如上图,是一个每层只有一个神经元的神经网络,且每一层的激活函数为sigmoid,则有:
y
i
=
σ
(
z
i
)
=
σ
(
w
i
x
i
+
b
i
)
y_{i}=\sigma\left(z_{i}\right)=\sigma\left(w_{i} x_{i}+b_{i}\right)
yi=σ(zi)=σ(wixi+bi)
σ
\sigma
σ是sigmoid函数。
根据反向传播算法有:
δ
C
δ
b
1
=
δ
C
δ
y
4
δ
y
4
δ
z
4
δ
z
4
δ
x
4
δ
x
4
δ
z
3
δ
z
3
δ
x
3
δ
x
3
δ
z
2
δ
z
2
δ
x
2
δ
x
2
δ
z
1
δ
z
1
δ
b
1
\frac{\delta C}{\delta b_{1}}=\frac{\delta C}{\delta y_{4}} \frac{\delta y_{4}}{\delta z_{4}} \frac{\delta z_{4}}{\delta x_{4}} \frac{\delta x_{4}}{\delta z_{3}} \frac{\delta z_{3}}{\delta x_{3}} \frac{\delta x_{3}}{\delta z_{2}} \frac{\delta z_{2}}{\delta x_{2}} \frac{\delta x_{2}}{\delta z_{1}} \frac{\delta z_{1}}{\delta b_{1}}
δb1δC=δy4δCδz4δy4δx4δz4δz3δx4δx3δz3δz2δx3δx2δz2δz1δx2δb1δz1
=
δ
C
δ
y
4
(
σ
′
(
z
4
)
w
4
)
(
σ
′
(
z
3
)
w
3
)
(
σ
′
(
z
2
)
w
2
)
(
σ
′
(
z
1
)
)
=\frac{\delta C}{\delta y_{4}}\left(\sigma^{\prime}\left(z_{4}\right) w_{4}\right) \quad\left(\sigma^{\prime}\left(z_{3}\right) w_{3}\right) \quad\left(\sigma^{\prime}\left(z_{2}\right) w_{2}\right) \quad\left(\sigma^{\prime}\left(z_{1}\right)\right)
=δy4δC(σ′(z4)w4)(σ′(z3)w3)(σ′(z2)w2)(σ′(z1))
而sigmoid函数的导数公式为:
S
′
(
x
)
=
e
−
x
(
1
+
e
−
x
)
2
=
S
(
x
)
(
1
−
S
(
x
)
)
S^{\prime}(x)=\frac{e^{-x}}{\left(1+e^{-x}\right)^{2}}=S(x)(1-S(x))
S′(x)=(1+e−x)2e−x=S(x)(1−S(x))sigmoid函数及其它的图形曲线为:

sigmoid函数图像如上图

sigmoid函数导数图像如上图
由上可见,sigmoid函数的导数 σ ′ ( x ) \sigma^{\prime}(x) σ′(x)的最大值为 1 4 \frac{1}{4} 41 ,通常我们会将权重初始值 ∣ w ∣ |w| ∣w∣ 初始化为为小于1的随机值,因此我们可以得到 ∣ σ ′ ( z 4 ) w 4 ∣ < 1 4 \left|\sigma^{\prime}\left(z_{4}\right) w_{4}\right|<\frac{1}{4} ∣σ′(z4)w4∣<41,随着层数的增多,那么求导结果 δ C δ b 1 \frac{\delta C}{\delta b_{1}} δb1δC越小,这也就导致了梯度消失问题。
那么如果我们设置初始权重 ∣ w ∣ |w| ∣w∣较大,那么会有 ∣ σ ′ ( z 4 ) w 4 ∣ > 1 \left|\sigma^{\prime}\left(z_{4}\right) w_{4}\right|>1 ∣σ′(z4)w4∣>1 ,造成梯度太大(也就是下降的步伐太大),这也是造成梯度爆炸的原因。
总之,无论是梯度消失还是梯度爆炸,都是源于网络结构太深,造成网络权重不稳定,从本质上来讲是因为梯度反向传播中的连乘效应。
5.4 解决方法
5.4.1 换用Relu、LeakyRelu、Elu等激活函数
-
ReLu:让激活函数的导数为1
-
LeakyReLu:包含了ReLu的几乎所有有点,同时解决了ReLu中0区间带来的影响
-
ELU:和LeakyReLu一样,都是为了解决0区间问题,相对于来,elu计算更耗时一些
5.4.2 Batch Normalization
Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
具体的batchnorm原理非常复杂,在这里不做详细展开,此部分大概讲一下batchnorm解决梯度的问题上。具体来说就是反向传播中,经过每一层的梯度会乘以该层的权重,举个简单例子:
正向传播中
f
2
=
f
1
(
w
T
∗
x
+
b
)
f_{2}=f_{1}\left(w^{T} * x+b\right)
f2=f1(wT∗x+b),那么反向传播中,
∂
f
2
∂
x
=
∂
f
2
∂
f
1
x
\frac{\partial f_{2}}{\partial x}=\frac{\partial f_{2}}{\partial f_{1}} x
∂x∂f2=∂f1∂f2x,反向传播式子中有
x
x
x的存在,所以
x
x
x的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了
x
x
x带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
5.4.3 ResNet残差结构
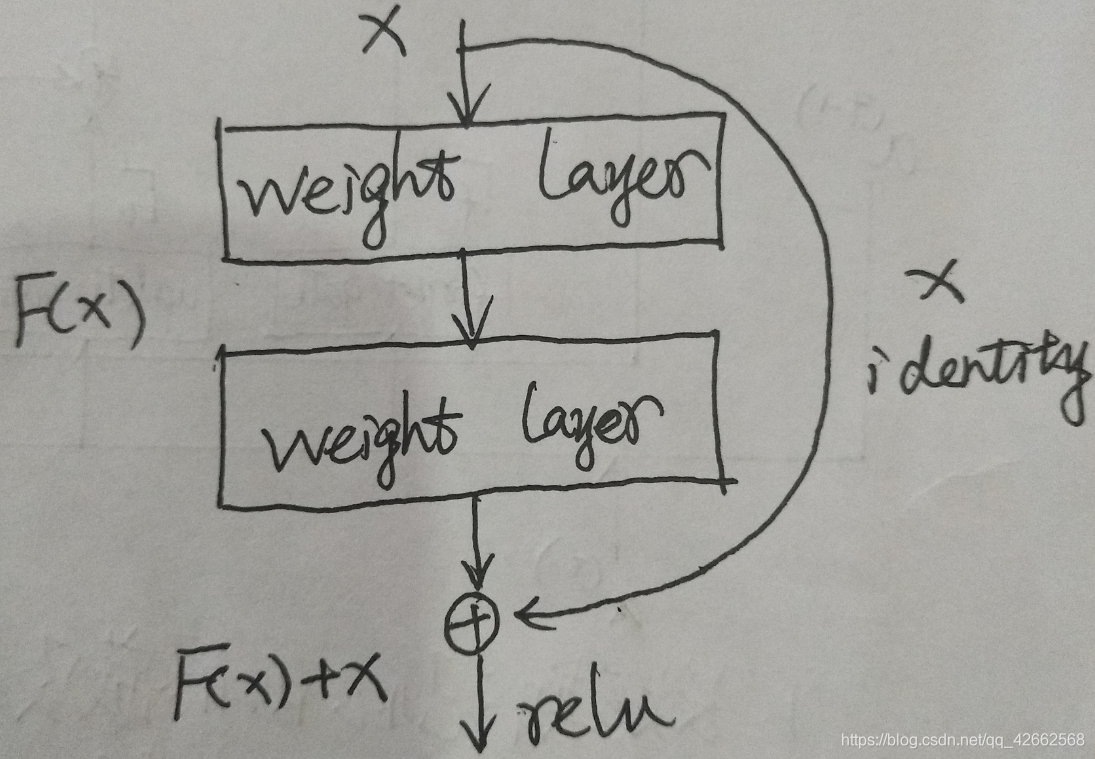
具体理解见此文
总的来说,Resnet的核心思想就是更改了网络结构的学习目的,原本学习的是直接通过卷积得到的图像特征H(X),现在学习的是图像与特征的残差H(X)-X,这样更改的原因是因为残差学习相比原始特征的直接学习更加容易。以下进行一个简单的证明。
ResNet代码实现:
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
trained (bool): If True, returns a model pre-trained on ImageNet
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
5.4.4 LSTM结构
5.4.5 预训练加finetunning
此方法来自Hinton在06年发表的论文上,其基本思想是每次训练一层隐藏层节点,将上一层隐藏层的输出作为输入,而本层的输出作为下一层的输入,这就是逐层预训练。
训练完成后,再对整个网络进行“微调(fine-tunning)”。
此方法相当于是找全局最优,然后整合起来寻找全局最优,但是现在基本都是直接拿imagenet的预训练模型直接进行finetunning。
5.4.6 梯度剪切、正则
这个方案主要是针对梯度爆炸提出的,其思想是设值一个剪切阈值,如果更新梯度时,梯度超过了这个阈值,那么就将其强制限制在这个范围之内。这样可以防止梯度爆炸。
另一种防止梯度爆炸的手段是采用权重正则化,正则化主要是通过对网络权重做正则来限制过拟合,但是根据正则项在损失函数中的形式:
可以看出,如果发生梯度爆炸,那么权值的范数就会变的非常大,反过来,通过限制正则化项的大小,也可以在一定程度上限制梯度爆炸的发生。
end
[参考文档]
[1] https://www.jianshu.com/p/3f35e555d5ba
[2] https://www.cnblogs.com/pigbreeder/p/8051442.html
[3] https://www.cnblogs.com/pinking/p/9418280.html
[4] https://www.jianshu.com/p/ec0967460d08
[5] https://zhuanlan.zhihu.com/p/38537439















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









