







代码,但这个代码表示论文源码,在2080TI上边运行总出现显存不足,这个问题留待以后解决。
1. 研究问题
使用深度卷积网络学习从图像对到视差图的端到端映射。
2. 研究方法
GCNet提出利用几何知识,使用深度特征的连接来构建 4D 成本量,然后通过使用3D convolutions对成本量进行正则化,学习上下文信息,最后使用可微的soft argmin从4D 成本量中回归亚像素视差。
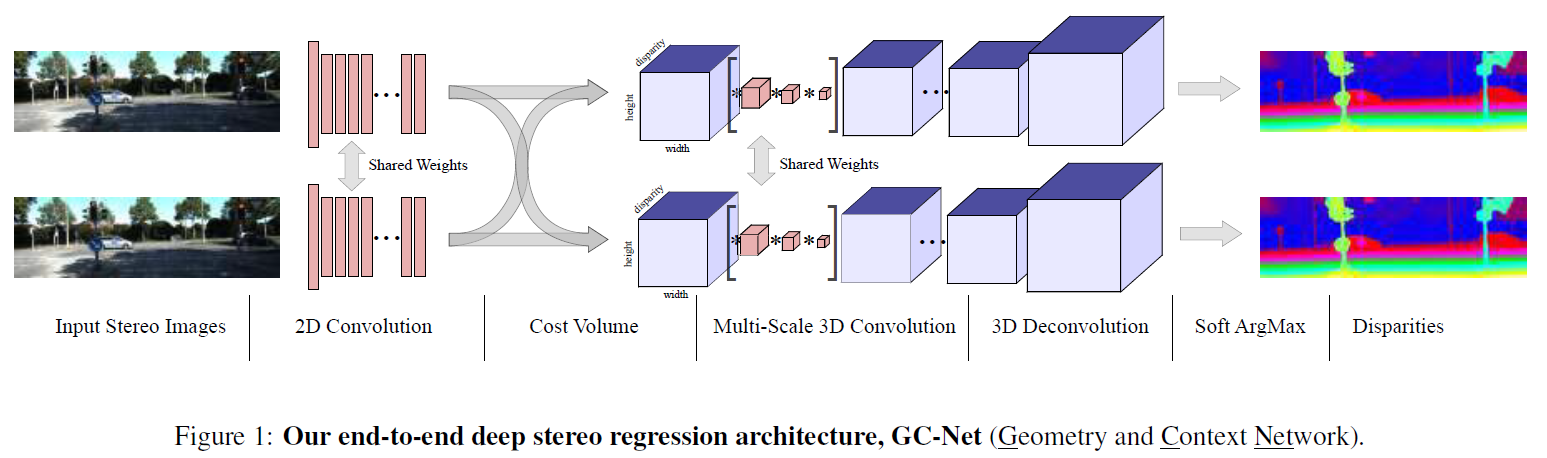


2.1 Unary Features
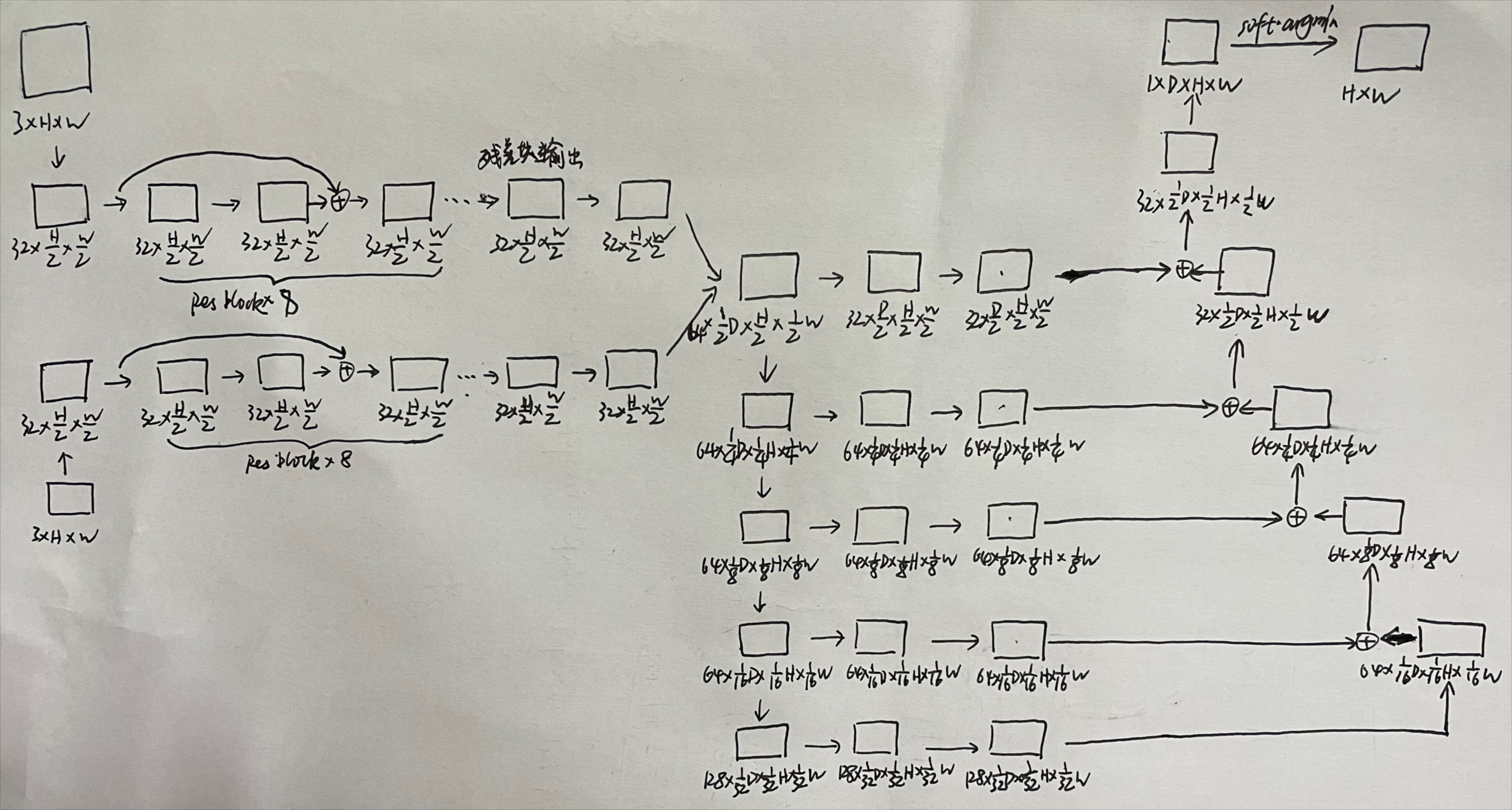
通过一系列的卷积层和残差块来学习左右图像的一元特征。这里的一元特征其实就是特征向量,只是换了一个说法而已。这部分没什么亮点。
2.2 Cost Volume
这里不同于以往的基于特征相减或距离度量(dot multiply)来构建代价空间,本文的方法是提出直接将左右特征进行连接,实验证明这样做提高了性能。代价空间的大小为 H ∗ W ∗ ( D + 1 ) ∗ F H*W*(D+1)*F H∗W∗(D+1)∗F。可能的原因是连接特征可以学习一个特征的绝对表示,使得网络可以学习到语义信息。比如,对于一个汽车挡风玻璃这样的反光表面,如果立体匹配算法只依靠这一反光表面的局部表现来计算几何特征很可能会出错。然而,如果理解了这一表面的语义信息(这是属于汽车的一部分),再去推断局部的几何特征就很有优势了。
具体的做法是:将左图每个一元特征与其在右图对应位置的一元特征进行连接,形成4D cost volumn。
2.3 Learning Context
对初始的成本量正则化,能够学习得到上下文信息,这样能够克服一些具有挑战性的场景,比如重复纹理,弱纹理区域等。
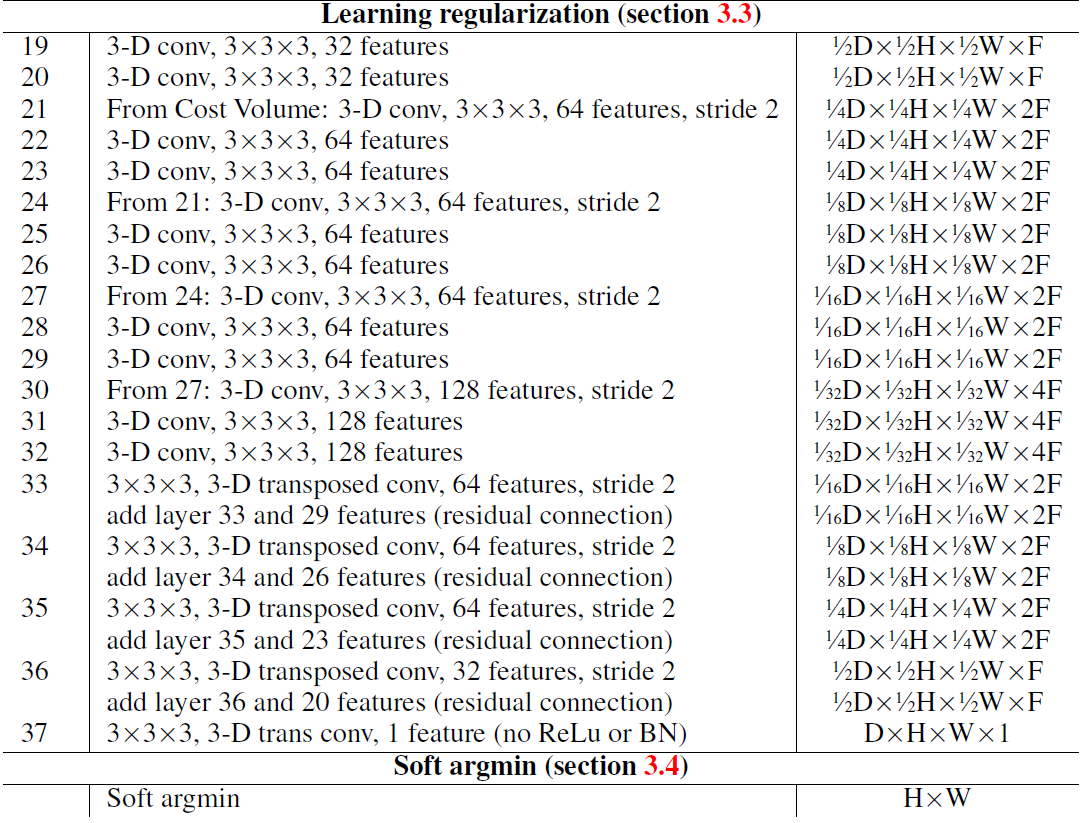
提出使用3D convolutions,沿着高、宽、视差三个维度进行卷积,学习上下文信息。
但3D convolutions 会导致庞大的计算量,因此,文章使用四级编码器-解码器架构。首先,下采样有助于增加每个特征的感受野,同时减少计算量。 然而,它也会通过分辨率的损失降低空间精度和细粒度的细节。 出于这个原因,在上采样之前通过跳跃连接添加了在下采样中同样分辨率的特征图,形成残差结构。 这些残差层的好处是可以保留更完整的信息,而上采样的特征提供了具有更大空间分辨率的特征图,最后输出一个原始分辨率( H ∗ W ∗ D H*W*D H∗W∗D)的细化的代价空间。
2.4 Differentiable ArgMin
传统的立体匹配方法采用argmin来选择离散的视差,并通过后处理来获得连续的视差。或者像DispNet那样直接采用卷积层估计视差。
argmin存在两个问题:
- 离散,无法产生亚像素精度的视差
- 不可微,不能反向传播
本文的方法与传统方法结合更加密切,提出了使用soft argmin 来回归亚像素视差,满足完全可微(可反向传播),无需任何后处理过程。
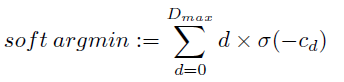
可以看出soft argmin是所有视差的加权平均,但这样就容易引入误差,而正则化就是通过调整代价空间以控制归一化后softmax概率的峰值,使视差呈现一个单峰概率分布为了产生单峰的视差概率分布。在正则化的最后一层省去了BN就是为了让网络自动学习一个单峰的视差概率分布。
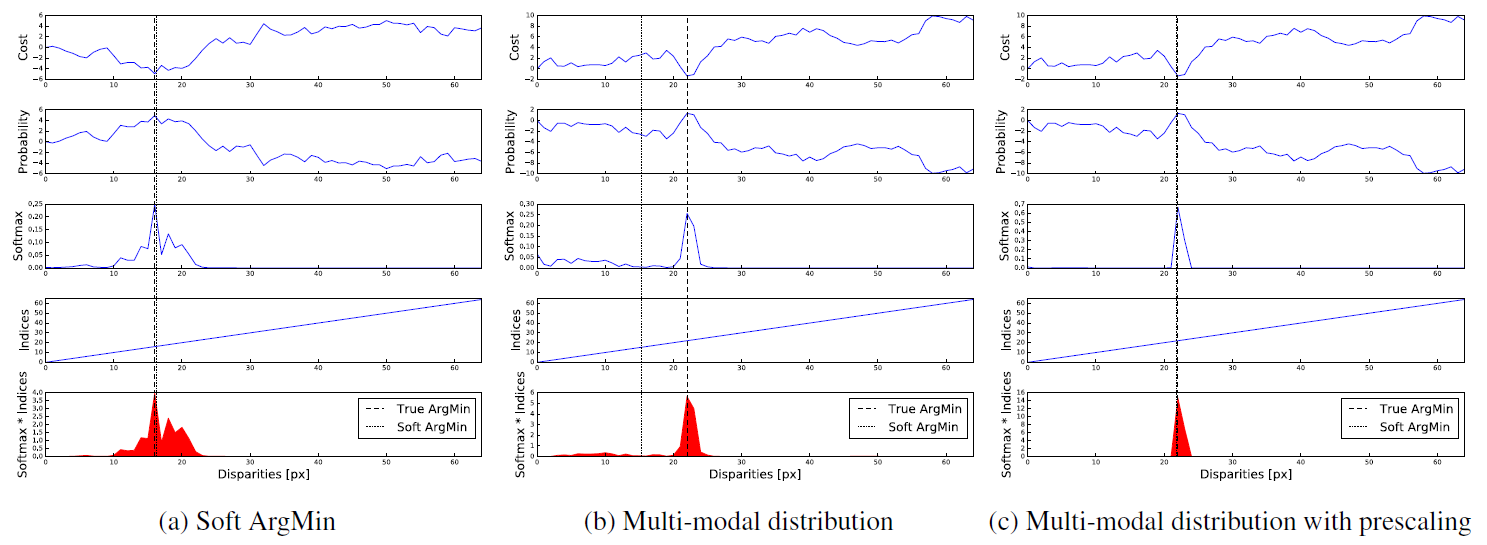
2.5 Loss
由于直接是回归亚像素精度的视差,所以这里简单的采用绝对误差损失函数。
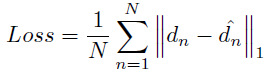
总结:本文的核心部分是2.3和2.4小节。
3. 实验结果
训练:
- 用RMSProp优化器,采用恒定的学习率 0.001 0.001 0.001。
- batchsize=1,对输入图像进行 256 ∗ 512 256*512 256∗512的随机裁剪。
- 将图像像素值归一化到 [ − 1 , 1 ] [-1,1] [−1,1]。
- 使用一块GPU,在Scene Flow上训练大概 150k 次迭代,大约花费两天的时间。
- 在KITTI上进行微调,训练50k次。
- 对于Scene Flow,设置F=32,H=540,W=960,D=192;对于KITTI,设置F=32,H=388,W=1240,D=192。
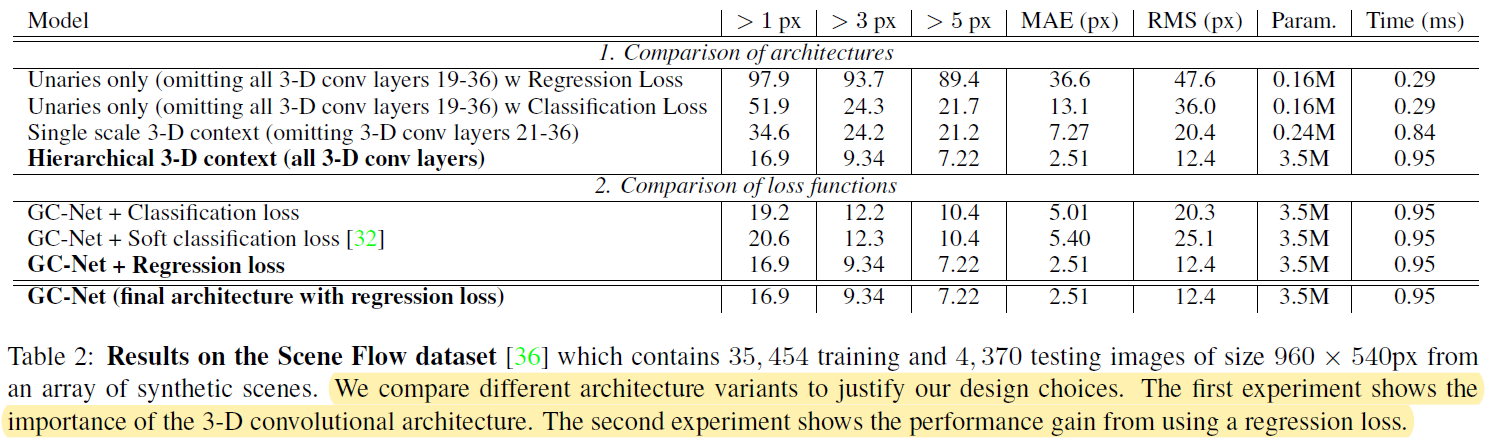
3.1 SceneFlow 消融实验
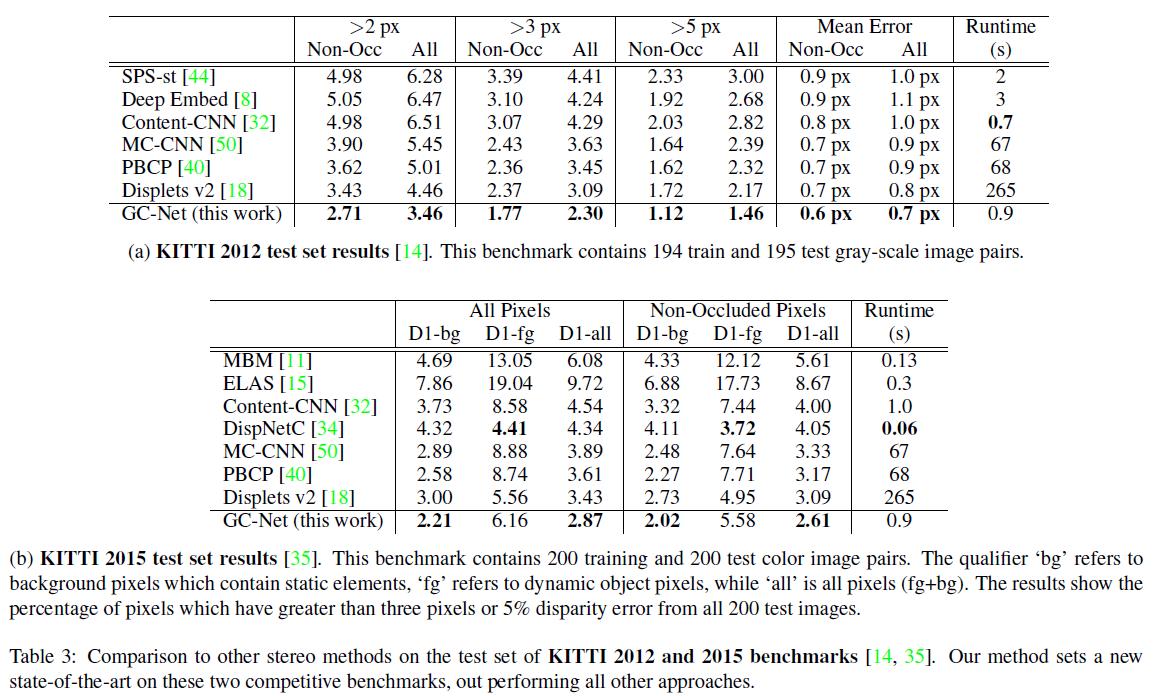
3.2 KITTI Benchmark
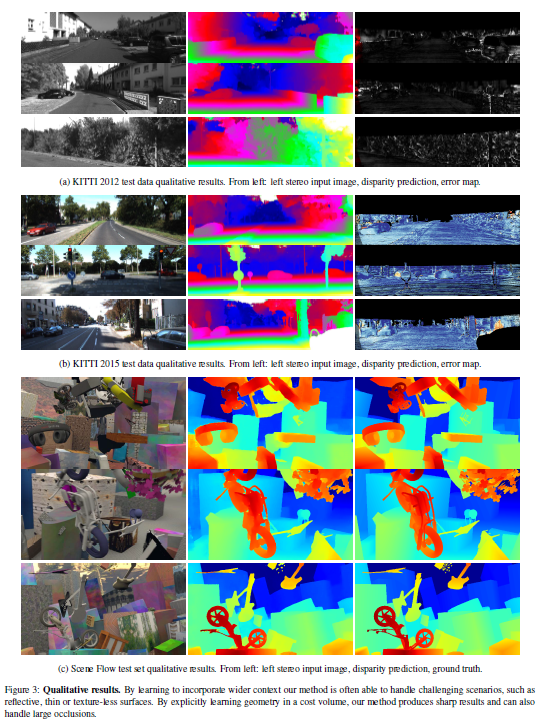
3.3 定性实验
4. 结论
(1)GCNet的性能与最先进的方法相当,是一个接近实时的方法,大概1 fps,相比于MC-CNN快将近70倍。
(2)使用了soft argmin来回归亚像素精度,而无需任何后处理。
(3)通过3D convolutions 可以学习更多的上下文。
5. 局限性
(1)薄结构,物体边缘不够清晰,可能是由于重复的下采样和上采样的过程损失了一些重要的细节信息。
(2)将左右特征描述符在各个视差值下直接连接构造代价空间,会造成在后续的推理中消耗巨大的内存。
参考文献
[3] Segnet: A deep convolutional encoder-decoder architecture for image segmentation.















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









