






文献阅读笔记: End-to-End Learning of Geometry and Context for Deep Stereo Regression
本文提出一种新颖的深度学习体系结构,用于从矫正的立体图像对中回归视差。利用问题的几何知识来形成一个使用深度特征表示的成本量。学习在这个体积上使用三维卷积来整合上下文信息。使用提出的可微分soft argmin操作从成本量中回归视差值,这能够在不需要任何额外的后处理或正则化的情况下,从端到端地训练我们的方法到亚像素的精度。在 Scene Flow 和KITTI数据集上评估我们的方法。
1.网络结构
通过开发代表传统立体匹配过程中每个主要组件的可微分层来形成我们的模型,这使我们能够同时利用我们对立体问题的几何知识端到端地学习整个模型。
网络结构GC-Net(几何和上下文网络) 如图1所示:

2.逐层定义
下表总结端到端深度立体回归架构,GC-Net。
table 1 :每个二维或三维卷积层代表一个卷积块、批处理归一化和ReLU(除非另有说明)。

2.1 Unary Features(理解为特征提取就可)
在模型中,通过一些二维卷积运算来学习深度表示法。每个卷积层之后是一个批处理归一化层和一个矫正的线性非线性。为了减少计算需求,首先应用一个步长为2的5×5卷积滤波器对输入进行子采样。在这一层之后,添加了8个残差块,每个块由两个3×3卷积滤波器串联而成。我们最终的模型架构如表1所示。通过将左右立体图像通过这些层来形成一元特征,共享左右塔之间的参数,以更有效地学习相应的特征。
看 “2逐层定义” table1中 Unary Features部分描述的意思是:
- 首先对输入的左右图(H×W×C) 在layer 1应用步长为2的5×5卷积滤波器对输入进行子采样(也包括批处理归一化和ReLU激活函数),再经过layers 2,3应用串联的3×3卷积滤波器(也包括批处理归一化和ReLU激活函数) ~~ ps:下文不注明,每个卷积层都应用批处理归一化和ReLU激活函数
- 将layer 1 和 经过 layers 2,3 后的Tensor 进行残差连接
- 继续重复 应用layers2,3后进行残差连接(仍是layer1和此时的layer 3)7次
- 最后 应用3×3 conv (no Relu or BN)
输出Tensor维度为1/2H×1/2W×F (F=32特征维度,可看作输出通道数为32,也就是table1中的features)
2.2 Cost Volume
利用深度特征形成一个代价量来计算立体匹配代价。虽然方法可能只是简单地连接左和右的特征地图,形成一个cost volume允许我们以一种保留我们的立体视觉几何知识的方式约束模型。对于每一张立体图像,我们形成一个维度 高度×宽度×(最大视差+ 1)×特征尺寸的cost volume。我们通过在每个视差级别上将来自相反立体图像的每个特征与它们对应的一元连接起来,并将它们打包到4D体积中来实现此目的。
通过这种操作保留了特征尺寸,不像以前的工作那样使用点积式操作来抽取特征尺寸。这使我们能够学习合并能够操作特征一元的上下文。
在table1中表示为 1/2D × 1/2H × 1/2W × 2F
2.3 Learning Context
给定这种视差cost volume,我们现在想学习一个正则化函数,该函数可以考虑该量中的上下文并优化我们的视差估计。在像素强度均匀的区域(例如天空),基于固定的局部环境,任何要素的成本曲线都是平坦的。因此,我们希望学习去调整和改善这一volume。
使用三维卷积运算来过滤和细化这种表示。三维卷积能够从高度、宽度和视差维度学习特征表示。因为我们计算每个unary feature的成本曲线,所以我们可以从这个表示中学习卷积滤波器。
我们用四个层次的子采样来形成我们的三维正则化网络。使用编码器-解码器的思想进行下采样和上采样。
这里还是看上文table 1 中具体的描述:
输入分辨率 cost volume 1/2D × 1/2H × 1/2W × 2F
- 每次应用三维卷积层 步长为2 的3×3×3 卷积操作(也包括批处理归一化和ReLU激活函数,下文不指明,如是) 四次使分辨率为初始输入的1/32
- 并为每个编码器级别应用两个3×3×3的串联卷积,后也用来做残差连接(residual connection)
- 为了在原始输入分辨率下进行密集预测,采用三维转置卷积(反卷积)来对解码器中的volume进行上采样 ,并对应分辨率进行残差连接。此时输出分辨率1/2D × 1/2H × 1/2W × F
- 最后,3×3×3, trans conv, 1 feature (no ReLu or BN) D×H×W×1
2.4 Differentiable ArgMin
可微分的ArgMin
立体算法从匹配的成本生最终的成本量。从这个量,我们可以通过在成本量视差维度上执行argmin运算来估计视差。但是,该操作有两个问题:
- 它是离散的,无法产生亚像素视差估计
- 不可微分,因此无法使用反向传播进行训练
为了克服这些限制,我们定义了一个soft argmin,它是完全可微的,并且能够回归平滑的视差估计。首先,我们通过取每个值的负值,将预测成本Cd(对于每个差异,d)从成本量转换为概率量。我们使用软最大操作σ()对视差维度上的概率体积进行归一化。然后我们取每个视差的和,d,用它的归一化概率加权。图2显示了一个图解,并在中进行了数学定义 ,如下:

然而,与argmin操作相比,它的输出受所有值的影响。这使得它容易受到多模态分布的影响,因为输出不会采取最有可能的。相反,它将估算所有模式的加权平均值。为了克服这个限制,我们依靠网络的正则化来产生主要是单峰的视差概率分布。网络还可以预先调整匹配成本,以控制归一化 post-softmax概率的峰值。
下图2 为soft argmin操作的图形描述:

它可以沿着视差变化绘制一条成本曲线,并通过将每个视差的softmax概率与其视差指数的乘积相加来输出参数的估计值。
(a)证明当曲线为单峰时,这非常准确地捕获了真实的argmin。
(b)当数据是具有一个峰值和一个平坦区域的双模态数据时,Soft argmin虚线与True argmin虚线相差较大,误差较大,有视差估计错误情况。
©表明,如果网络学会预先调整成本曲线,这种错误是可以避免的,因为软最大概率往往更极端,产生单一模式的结果。
2.5 Loss
通过监督学习来训练模型,用正确标注后的数据集,比如KITTI 数据集。
损失函数如下:

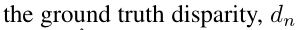 ,
, 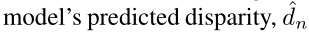
3 Conclusions
续更…
…先写到这里8,打算看看代码实现来着,所以先留着…
找到了代码参考:
- https://github.com/LinHungShi/GCNetwork ,(tensorflow, keras)
- https://github.com/gpcv-luochong/gc-net,(pytorch)
pytorch版本来自这个博客(点我)















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









