






摘
本文模型就是CNN+CRF。CNN提取特征,这些特征用在计算CRF的成本上。本文采用dual block descent 算法来计算图片近似最小化。虽然用的浅层CNN并且对于CRF的输出也没用后处理,依旧抵挡不住本文算法的牛叉。
1.介
多层的深度结构利用局部匹配信息形成一个整体。然而,深度CNN模型需要很多后处理,还需要一系列的滤波器和优化启发式的算法才能产生一个能看的结果。
本文结合CNN和立体匹配中的离散优化模型。这就让复杂的局部匹配成本和参数集合在全局优化的方法中结合到了一起,同时由数据端到端的学习。即使模型中包含CNN,这仍旧是比较容易去操作的。这就让我们把精力放在网络的表现上。以CRF的公式代替了之前很多人工的部分。
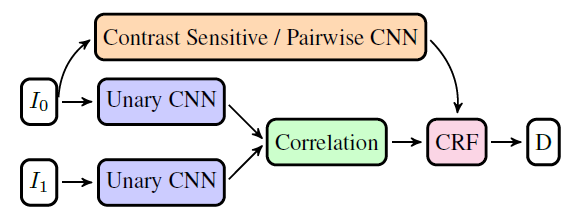
网络结构:用unary-cnn来学习两幅图片的特征。再用Correlation 层来计算特征。匹配之后得到的cost volume成为CRF的unary cost,而CRF的pairwise cost则会由边缘权重来参数化定义。一般边缘权重要么由sentitive model或者由Pairwise-CNN估计得到。Pairwise-CNN能够额外估计constrast-sensitive pairwise cost 为了鼓励或者阻断标签的跳跃。CRF尝试在4领域中找到一种联合优化算法来统一优化所有学习到的unary和paiewise成本。unary-CNN代表了人为设计的匹配成本,比如基于色彩差异,样本变化,local binary patterns。Pairwise-CNN代表了contrast-sensitive规范项。是立体匹配中MRF/CRF模型中常用到的参数。
本文故意不使用后处理就是为了证明CRF模型可以替代大多数后处理过程。
可以用SSVM公式去训练上图完整的模型,训练这样一个模型谈何容易,不过可以用近似子梯度策略。
CNN-CRF网络即使仅有3-7层的浅层CNN模型依旧可以表现得很好。一个混合的模型能够以更少的参数达到现阶段模型同样的性能。这可以得到更加精炼的模型以及训练数据更有效的应用。
2.相关工作
CNNs for Stereo
普通cnn都是双塔模型,分别从两张图片中提取特征然后以一个固定的correlation功能(product layer)来匹配它们。模型中的unary-CNN和correlation层继续延续了这样的传统。
有的算法训练的时候可能会采用不匹配的图像块?(难怪有的时候loss突然诡异的变大一下)。后面又跟一些经典算法做比较。mc-cnn以全连接NN层去进行特征的比较。比它的快速版本mc-cnn-fast要精确但是速度更慢。所有这些方法都有后处理。
mc-cnn采用cost cross aggregation,semi-global matching,子像素增强,中值和双边滤波。
efficient-deep采用基于窗口的cost aggregation,semi-global matching,左右一致性确定,亚像素增强,中值滤波,双边滤波和slant plane(公司做的无后处理的efficient-deep还真不知道效果怎么样)。
[12](这篇没看过,套路一样)semi-global匹配,左右一致性确定,中值滤波和双边滤波。
以上的算法加了后处理跟本文算法比起来也是渣渣。
CNN matching
匹配网络指的是flownet和dispnet这两个另类。它们都有correlation层。然而,这个层是作为特征的堆叠并且后面跟着upconvolution来对密度图进行回归预测。这些网络有着更多的参数需要非常多的训练数据(哈哈哈,大胆,竟然如此看不起dispnet!不过参过多和数据损耗大确实是事实,我很好奇这篇文章的结果究竟有多厉害了)
joint Traing
这种CNN和CRF联合训练的模型常常用在语义分割上,后面巴拉巴拉。
3.CNN-CRF 模型
左图一般作为参考,在右图中找对应点。对于每个像素,都会在任何可能的disparity的位置上进行correlate。形成一个correlation向量(这是一个匹配置信度向量)。P(x)代表的是图1中的像素i跟图2中的像素i+x有多么的相似。
3.1 unary CNN
只用3~7层,每层100个滤波器。滤波器大小第一层3×3,其余层2×2。激活函数选tanh。无BN层。dispnet说tanh比ReLU更好,在correlation中的块匹配时(????????dispnet里面用的也是ReLU好吧)
3.2 Correlation
cross-correlation左右图的特征进行cross-correlation。

correlation层输出的是对应特征向量点乘的softmax规范化大小之后的值。常规上说,规范化固定了unary-cost的大小,有利于联合网络的训练(回想dispnet中的correlation,就是两个图像之间的像素卷积,毫无规范化可言。这个pi(k)相当于dispnet当中的cost volume取一条横线,那个横线上的点就是各种不同的disparity,线头就是左图的某个像素,其中俩特征的点乘对应dispnet中的两个特征块卷积,只不过那个是以像素点为中心的两个块卷积,而这里是两个像素点的点乘。比较抽象)
3.3 CRF
关于CRF的后面一项,像素位置差为1的惩罚P1设置成小点,而其余惩罚都设置成P2惩罚大点,这可以防止深度跳跃,因为后面的项当像素值大小接近时权重变大,而像素大小相差过大时,权重变小。即找的X点更加偏向于找像素差别较大的点,因为只看周围位置相差为1的点就可以了,其余位置相差2的都差不多,所以这个公式是找特征奇点。
3.4 Pairwise CNN

pairwise-CNN(左)在水平方向上两个相邻像素之间的pairwise cost的观测值。右边则是fixed edge-function。灰色像素代表着改变标签低成本而亮像素则代表着标签转换时候的高成本。看好了,深色像素follow物体的轮廓(轮廓大多就是那些深度不连续的地方)。注意那些纹理边缘(比如地面)被抑制着。
为了估计Pairwise CNN中的边缘权重。使用3层网络,激活函数使用tanh。前两层提取特征,第三层根据两个边缘方向来将像素i上的特征映射到权重中去。保证了pairwise的cost比0大,pairwise-CNN有自由控制输出大小的能力。让我们可以在数据保真项和规范项中进行权衡。权重w以2通道图片进行存储(每个方向一个通道)。他们概括出公式5中定义的contrast-sensitive权重,fij是pairwise-terms。直观上看,这意味着pairwise网络能够在宽泛的领域中根据图片内容自适应的学习到权重w。
4. Training
训练3种模型:
pixel-wise unary-CNN:CRF被设置成0,pairwise-CNN被关了。
Joint Unary-CNN+CRF模型:pairwise-CNN用来复制contrast-sensitive模型。训练的参数如下:unary-CNN和全局参数P1,P2。
训练完毕的unary-CNN和pairwise-CNN联合模型















 3160
3160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









