







引言
VAE 是一类 encoder-decoder 模型,给定一个高维数据 x ∈ R D \mathbf{x} \in \mathbb{R}^D x∈RD,encoder 将生成潜在空间对应的表达 z ∈ R d , d ≪ D \mathbf{z} \in \mathbb{R}^d,d \ll D z∈Rd,d≪D,decoder 利用 z \mathbf{z} z 恢复原始数据 x ′ \mathbf{x}' x′,整个模型使用 x \mathbf{x} x 和 x ′ \mathbf{x}' x′ 之间的差异来训练。当训练好以后,随机从潜在空间中采样一个 z \mathbf{z} z,希望 decoder 能生成对应的数据。
动机
普通 encoder-decoder 用于生成任务时,容易造成严重的过拟合,使学习到的 潜在空间不规则。由于模型仅仅被要求在有限的训练数据上得到尽可能少的恢复损失,且缺少对潜在空间的约束,encoder 和 decoder 可能会学习到一种简单的一一对应关系,使得潜在空间中的一些点在被解码后的内容是无意义的。假设
z
∈
R
\mathbf{z} \in \mathbb{R}
z∈R,上述情况如下所示:
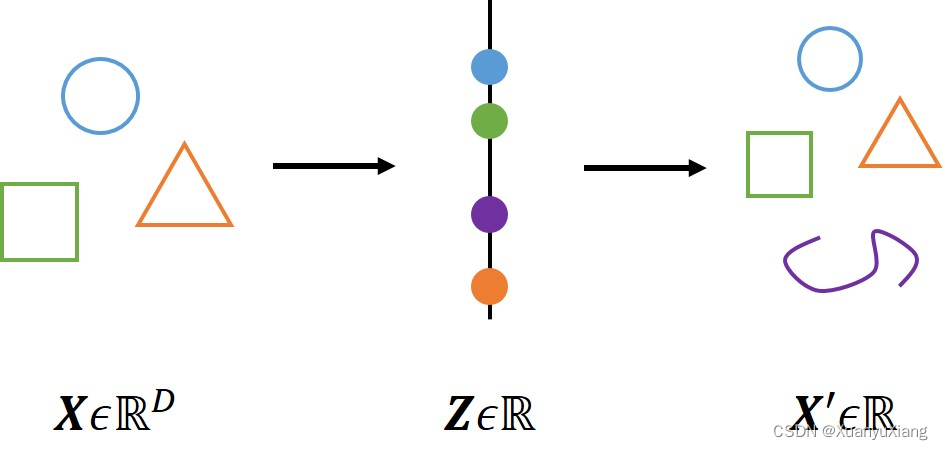
因此,为了使用 decoder 生成数据,必须保证潜在空间是规则的,一个可行的办法是在训练的时候对潜在空间添加正则化,这就是 VAE 的主要动机之一。
VAE 介绍
VAE 在训练的时候添加正则化以避免过拟合,同时使潜在空间更规则。普通的 encoder-decoder 将输入映射为一个数值,而 VAE 的 encoder-decoder 将输入映射为一个分布,在实作中,encoder 的输出分布被假设是高斯分布,encoder 实际预测的是均值和方差,流程如下:

目标函数为:
∣
∣
x
−
x
′
∣
∣
2
+
K
L
[
N
(
μ
x
,
σ
x
)
,
N
(
0
,
1
)
]
||\mathbf{x} - \mathbf{x}'||^2 + KL[\mathcal{N}(\mu_x, \sigma_x), \mathcal{N}(0, 1)]
∣∣x−x′∣∣2+KL[N(μx,σx),N(0,1)]
第一项是恢复损失,第二项是正则项。
正则项的直观理解
规则的潜在空间应该具有两个属性:连续性,完备性,连续性指潜在空间中相邻点的解码内容应该相近,完备性指潜在空间中任意点的解码内容都有意义,如下图(引自[1]):
 如果仅要求 encoder 的输出是一个高斯分布,也难以满足连续性和完备性。例如,当学习到的均值差异很大,方差很小时,此时的模型和普通encoder-decoder没有区别,为了避免这种情况,必须同时对方差和均值进行约束。在论文中,作者要求 encoder 的输出服从
N
(
0
,
1
)
\mathcal{N}(0, 1)
N(0,1),均值为0使各模式的均值接近,缓解均值差异大的问题,方差为1使各模式分布有一定的“重合”,增强空间连续性,如下图(引自[1]):
如果仅要求 encoder 的输出是一个高斯分布,也难以满足连续性和完备性。例如,当学习到的均值差异很大,方差很小时,此时的模型和普通encoder-decoder没有区别,为了避免这种情况,必须同时对方差和均值进行约束。在论文中,作者要求 encoder 的输出服从
N
(
0
,
1
)
\mathcal{N}(0, 1)
N(0,1),均值为0使各模式的均值接近,缓解均值差异大的问题,方差为1使各模式分布有一定的“重合”,增强空间连续性,如下图(引自[1]):
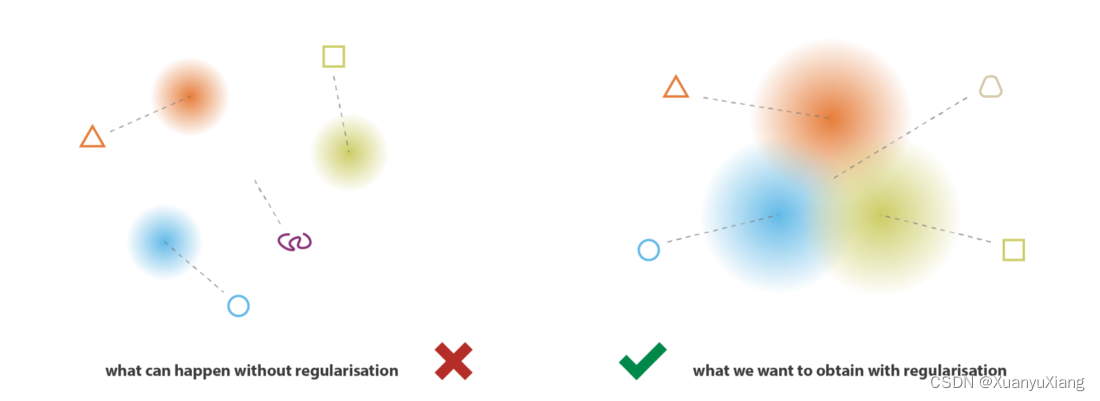
数学理解
这一节从理论角度来分析 VAE。首先定义一些符号,其中 θ \theta θ 代表生成模型参数:
- 先验 p θ ( z ) p_\theta(\mathbf{z}) pθ(z)
- 似然 p θ ( x ∣ z ) p_\theta(\mathbf{x}|\mathbf{z}) pθ(x∣z)
- 后验 p θ ( z ∣ x ) p_\theta(\mathbf{z}|\mathbf{x}) pθ(z∣x)
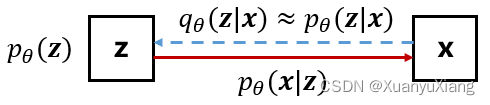
当我们想要计算
p
θ
(
z
∣
x
)
p_\theta(\mathbf{z}|\mathbf{x})
pθ(z∣x) 时,利用贝叶斯公式可知:
p θ ( z ∣ x ) = p θ ( x ∣ z ) p θ ( z ) p θ ( x ) p_\theta(\mathbf{z}|\mathbf{x})=\frac{p_\theta(\mathbf{x}|\mathbf{z})p_\theta(\mathbf{z})}{p_\theta(\mathbf{x})} pθ(z∣x)=pθ(x)pθ(x∣z)pθ(z)
p θ ( x ) = ∫ p θ ( x ∣ z ) p θ ( z ) d z p_\theta(\mathbf{x})=\int p_\theta(\mathbf{x}|\mathbf{z})p_\theta(\mathbf{z})d\mathbf{z} pθ(x)=∫pθ(x∣z)pθ(z)dz
在计算 p θ ( x ) p_\theta(\mathbf{x}) pθ(x) 时,由于无法遍历 z \mathbf{z} z,导致无法直接计算后验,故使用 q ϕ ( z ∣ x ) q_\phi(\mathbf{z}|\mathbf{x}) qϕ(z∣x) 来近似 p θ ( z ∣ x ) p_\theta(\mathbf{z}|\mathbf{x}) pθ(z∣x)(这个涉及到概念 variational inference)。
目标函数
很自然的,可以使用 KL 散度来度量两个分布之间的距离:
K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) ) KL(q_\phi(z|x)||p_\theta(z|x)) KL(qϕ(z∣x)∣∣pθ(z∣x))
= − ∑ z q ϕ ( z ∣ x ) l o g ( p θ ( z ∣ x ) q ϕ ( z ∣ x ) ) =-\sum_z q_\phi(z|x)log(\frac{p_\theta(z|x)}{q_\phi(z|x)}) =−∑zqϕ(z∣x)log(qϕ(z∣x)pθ(z∣x))
= − ∑ z q ϕ ( z ∣ x ) l o g ( p θ ( x , z ) q ϕ ( z ∣ x ) p θ ( x ) ) =-\sum_z q_\phi(z|x)log(\frac{p_\theta (x,z)}{q_\phi(z|x)p_\theta(x)}) =−∑zqϕ(z∣x)log(qϕ(z∣x)pθ(x)pθ(x,z))
= − ∑ z q ϕ ( z ∣ x ) [ l o g ( p θ ( x , z ) q ϕ ( z ∣ x ) ) − l o g ( p θ ( x ) ) ] =-\sum_z q_\phi(z|x)[log(\frac{p_\theta(x,z)}{q_\phi(z|x)})-log(p_\theta(x))] =−∑zqϕ(z∣x)[log(qϕ(z∣x)pθ(x,z))−log(pθ(x))]
= l o g ( p θ ( x ) ) − ∑ z q ϕ ( z ∣ x ) l o g ( p θ ( x , z ) q ϕ ( z ∣ x ) ) =log(p_\theta(x))-\sum_z q_\phi(z|x)log(\frac{p_\theta(x,z)}{q_\phi(z|x)}) =log(pθ(x))−∑zqϕ(z∣x)log(qϕ(z∣x)pθ(x,z))
左右交换可以得到:
l o g ( p θ ( x ) ) = K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) ) + ∑ z q ϕ ( z ∣ x ) l o g ( p θ ( x , z ) q ϕ ( z ∣ x ) ) log(p_\theta(x))=KL(q_\phi(z|x)||p_\theta(z|x))+\sum_z q_\phi(z|x)log(\frac{p_\theta(x,z)}{q_\phi(z|x)}) log(pθ(x))=KL(qϕ(z∣x)∣∣pθ(z∣x))+∑zqϕ(z∣x)log(qϕ(z∣x)pθ(x,z))
可以知道, l o g ( p θ ( x ) ) log(p_\theta(x)) log(pθ(x)) 是一个常数,且 KL 散度是非负的,于是最小化 KL 散度等价于最大化等式右边第二项,将这一项缩写为 L ( θ , ϕ ; x ) L(\theta, \phi; x) L(θ,ϕ;x),论文中被称为 variational lower bound,继续对这一项进行变换:
L ( θ , ϕ ; x ) L(\theta, \phi; x) L(θ,ϕ;x)
= ∑ z q ϕ ( z ∣ x ) l o g ( p θ ( x ∣ z ) p θ ( z ) q ϕ ( z ∣ x ) ) =\sum_z q_\phi(z|x)log(\frac{p_\theta (x|z)p_\theta(z)}{q_\phi(z|x)}) =∑zqϕ(z∣x)log(qϕ(z∣x)pθ(x∣z)pθ(z)) (1)
= ∑ z q ϕ ( z ∣ x ) [ l o g ( p θ ( x ∣ z ) ) + l o g ( p θ ( z ) q ϕ ( z ∣ x ) ) ] =\sum_z q_\phi(z|x)[log(p_\theta(x|z))+log(\frac{p_\theta(z)}{q_\phi(z|x)})] =∑zqϕ(z∣x)[log(pθ(x∣z))+log(qϕ(z∣x)pθ(z))] (2)
= E q ϕ ( z ∣ x ) [ l o g ( p θ ( x ∣ z ) ) ] − K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) =E_{q_\phi(z|x)}[log(p_\theta(x|z))]-KL(q_\phi(z|x)||p_\theta(z)) =Eqϕ(z∣x)[log(pθ(x∣z))]−KL(qϕ(z∣x)∣∣pθ(z)) (3)
其中第一项是重建损失,第二项是正则化项,整体是需要优化的目标函数,只需要求出其相对 ϕ \phi ϕ 的梯度,就可以用梯度下降法更新参数 ϕ \phi ϕ 了。
重参数化技巧
对于这种形式,一种典型的方法是 Monte Carlo 梯度估计法。记公式(2)中括号里的部分为 f ( z ) f(z) f(z)(虽然 f ( z ) f(z) f(z) 与 ϕ \phi ϕ 有关,但这里先暂时忽略),这里仅展示结论性的推导结果:
▽ ϕ E q ϕ ( z ) [ f ( z ) ] \triangledown \phi \mathbb{E}_{q_\phi(z)}[f(z)] ▽ϕEqϕ(z)[f(z)]
= E q ϕ ( z ) [ f ( z ) ▽ ϕ l o g ( q ϕ ( z ) ) ] =\mathbb{E}_{q\phi(z)}[f(z)\triangledown_{\phi}log(q_\phi(z))] =Eqϕ(z)[f(z)▽ϕlog(qϕ(z))]
≃ 1 L ∑ l = 1 L f ( z ) ▽ ϕ l o g ( q ϕ ( z l ) ) , z l ∼ q ϕ ( z ∣ x ) \simeq \frac{1}{L}\sum^L_{l=1}f(z)\triangledown_{\phi}log(q_\phi(z^l)),\quad z^l\sim q_\phi(z|x) ≃L1∑l=1Lf(z)▽ϕlog(qϕ(zl)),zl∼qϕ(z∣x)
如果使用该方法,会产生很大的 variance,使训练不稳定。对此,VAE 提出了 Generic Stochastic Gradient Variational Bayes (SGVB) 梯度估计,包含重参数化技巧(reparameterization trick),这里涉及一个很重要的讨论,为什么需要重参数化技巧?,在 Monte Carlo 梯度估计法中,我们假设 f ( z ) f(z) f(z) 和参数 ϕ \phi ϕ 无关,但根据公式(1)明显是有关的,在有关情况下再次考虑梯度:
▽ ϕ E q ϕ ( z ∣ x ) [ f ϕ ( z ) ] \triangledown_\phi \mathbb{E}_{q_\phi(z|x)}[f_\phi(z)] ▽ϕEqϕ(z∣x)[fϕ(z)]
= ▽ ϕ [ ∑ z q ϕ ( z ∣ x ) f ϕ ( z ) d z ] =\triangledown_\phi[\sum_z q_\phi(z|x)f_\phi(z)dz] =▽ϕ[∑zqϕ(z∣x)fϕ(z)dz]
= ∑ z ▽ ϕ [ q ϕ ( z ∣ x ) f ϕ ( z ) ] d z =\sum_z \triangledown_\phi [q_\phi(z|x)f_\phi(z)]dz =∑z▽ϕ[qϕ(z∣x)fϕ(z)]dz
= ∑ z f ϕ ( z ) ▽ ϕ q ϕ ( z ∣ x ) d z + ∑ z q ϕ ( z ∣ x ) ▽ ϕ f ϕ ( z ) d z =\sum_z f_\phi(z) \triangledown_\phi q_\phi(z|x)dz + \sum_z q_\phi(z|x) \triangledown_\phi f_\phi(z)dz =∑zfϕ(z)▽ϕqϕ(z∣x)dz+∑zqϕ(z∣x)▽ϕfϕ(z)dz
= ∑ z f ϕ ( z ) ▽ ϕ q ϕ ( z ∣ x ) d z + E q ϕ ( z ∣ x ) [ ▽ ϕ f ϕ ( z ) ] =\sum_z f_\phi(z) \triangledown_\phi q_\phi(z|x)dz + \mathbb{E}_{q_\phi(z|x)}[\triangledown_\phi f_\phi(z)] =∑zfϕ(z)▽ϕqϕ(z∣x)dz+Eqϕ(z∣x)[▽ϕfϕ(z)]
由于第一项不能写成期望的形式,无法用求平均来近似,且无法遍历 z 进行积分,因此是不可解的,对此才提出重参数技巧。重参数化令 z = g ϕ ( ϵ , x ) , ϵ ∼ p ( ϵ ) z=g_\phi(\epsilon, x), \epsilon \sim p(\epsilon) z=gϕ(ϵ,x),ϵ∼p(ϵ),从而使用 g ϕ ( ϵ , x ) g_\phi(\epsilon, x) gϕ(ϵ,x) 的分布来替代 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),该替换原理基于 variational inference:
▽ ϕ E q ϕ ( z ∣ x ) [ f ( z i ) ] \triangledown_\phi \mathbb{E}{q\phi(z|x)}[f(z^i)] ▽ϕEqϕ(z∣x)[f(zi)]
= ▽ ϕ E p ( ϵ ) [ f ( g ϕ ( ϵ , x i ) ) ] =\triangledown_\phi \mathbb{E}{p(\epsilon)}[f(g\phi(\epsilon,x^i))] =▽ϕEp(ϵ)[f(gϕ(ϵ,xi))]
= E p ( ϵ ) [ ▽ ϕ f ( g ϕ ( ϵ , x i ) ) ] =\mathbb{E}{p(\epsilon)}[\triangledown\phi f(g_\phi(\epsilon,x^i))] =Ep(ϵ)[▽ϕf(gϕ(ϵ,xi))]
≈ 1 L ∑ l = 1 L ▽ ϕ f ( g ϕ ( ϵ l , x i ) ) \approx \frac{1}{L} \sum^L_{l=1} \triangledown_\phi f(g_\phi(\epsilon^l,x^i)) ≈L1∑l=1L▽ϕf(gϕ(ϵl,xi))
此时就可以计算梯度了。对于为什么要使用重采样技巧,还有一种很受欢迎的解释是,从
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x) 中采样的过程不可导,因此将抽样通过辅助随机变量
ϵ
\epsilon
ϵ 剥离出来,梯度就可以通过
g
ϕ
(
ϵ
,
x
)
g_\phi(\epsilon, x)
gϕ(ϵ,x) 进行反向传播,如下图(引自[3]):
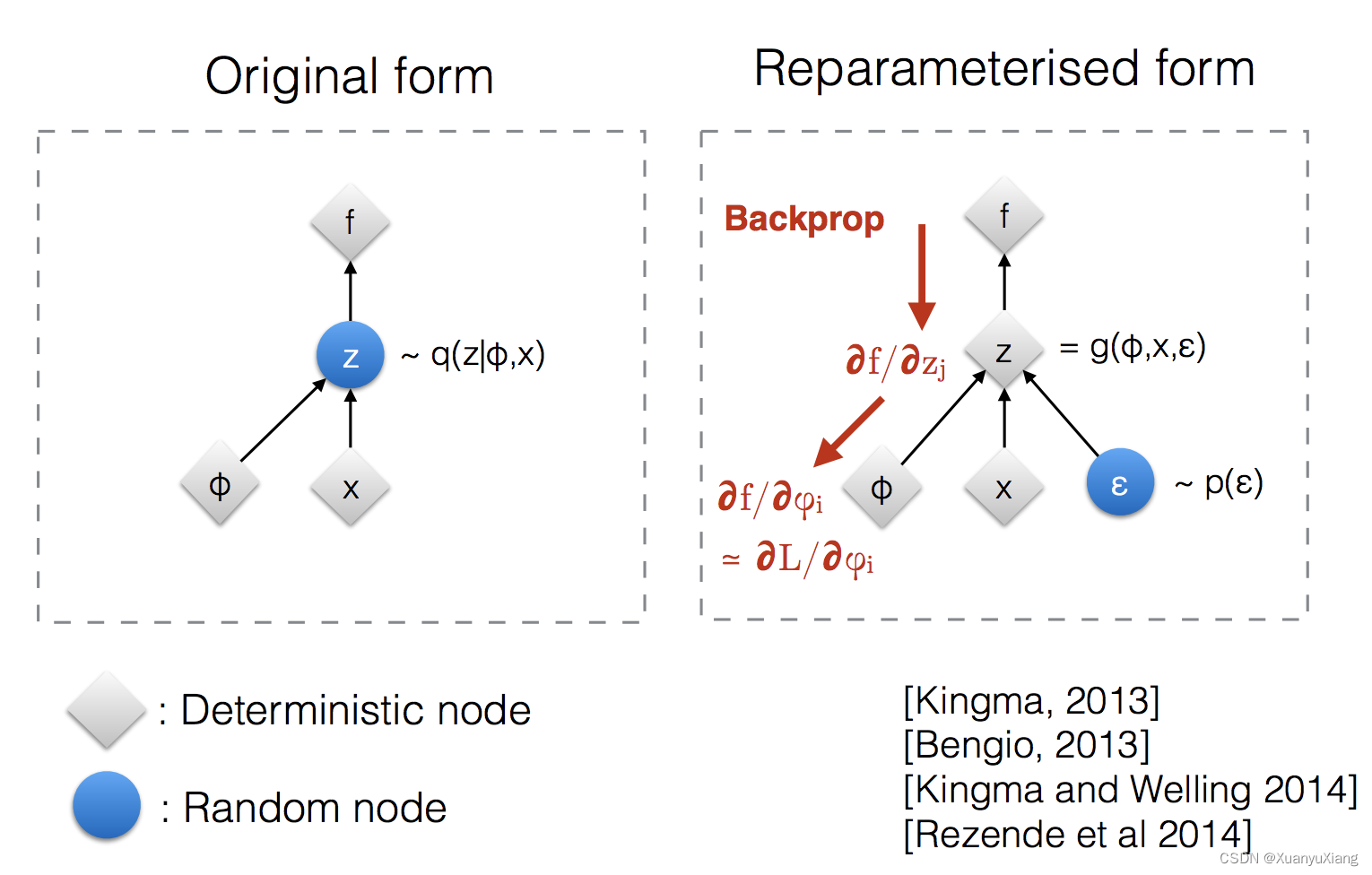
SGVB
根据公式(1),将 z = g ϕ ( ϵ , x ) z=g_\phi(\epsilon,x) z=gϕ(ϵ,x) 代入 L ( θ , ϕ ; x ) L(\theta, \phi; x) L(θ,ϕ;x) 可以得到 SGVB 估计结果 L ~ A ( θ , ϕ ; x i ) ≃ L ( θ , ϕ ; x i ) \widetilde{L}^A(\theta,\phi;x^i) \simeq L(\theta,\phi;x^i) L A(θ,ϕ;xi)≃L(θ,ϕ;xi):
L ( θ , ϕ ; x ) L(\theta, \phi; x) L(θ,ϕ;x)
= E q ϕ ( z ∣ x ) [ − l o g q ϕ ( z ∣ x ) + l o g p θ ( x , z ) ] =\mathbb{E}_{q_\phi(z|x)}[-log\ q_\phi(z|x)+log\ p_\theta(x,z)] =Eqϕ(z∣x)[−log qϕ(z∣x)+log pθ(x,z)]
L ~ A ( θ , ϕ ; x i ) \widetilde{L}^A(\theta,\phi;x^i) L A(θ,ϕ;xi)
= 1 L ∑ l = 1 L l o g p θ ( x i , z i , l ) − l o g q ϕ ( z i , l ∣ x i ) , =\frac{1}{L} \sum^L_{l=1} log\ p_\theta(x^i,z^{i,l})-log\ q_\phi(z^{i,l}|x^i)\ , =L1∑l=1Llog pθ(xi,zi,l)−log qϕ(zi,l∣xi) ,
w h e r e z i , l = g ϕ ( ϵ i , l , x i ) a n d ϵ l ∼ p ( ϵ ) where \quad z^{i,l}=g_\phi(\epsilon^{i,l},x^i) \quad and \quad \epsilon^l \sim p(\epsilon) wherezi,l=gϕ(ϵi,l,xi)andϵl∼p(ϵ)
除此之外,论文还发现,由于我们假设 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 和 p θ ( z ) p_\theta(z) pθ(z) 都服从高斯分布,且 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 的协方差矩阵为对角矩阵,在计算公式(3)中 KL 散度时可以利用高斯分布的性质来简化计算:
∫ q ϕ ( z ∣ x ) l o g p ( z ) d z \int q_\phi(z|x)log\ p(z)dz ∫qϕ(z∣x)log p(z)dz
= ∫ N ( z ; μ , σ 2 ) l o g N ( z ; 0 , I ) d z =\int \mathcal{N}(z;\mu,\sigma^2)log\ \mathcal{N}(z;0,I)\ dz =∫N(z;μ,σ2)log N(z;0,I) dz
= ∫ N ( z ; μ , σ 2 ) ( − 1 2 z 2 − 1 2 l o g ( 2 π ) ) d z =\int \mathcal{N}(z;\mu,\sigma^2)(-\frac{1}{2}z^2-\frac{1}{2}log(2\pi))\ dz =∫N(z;μ,σ2)(−21z2−21log(2π)) dz
= − 1 2 ∫ N ( z ; μ , σ 2 ) z 2 d z − J 2 l o g ( 2 π ) =-\frac{1}{2}\int \mathcal{N}(z;\mu,\sigma^2)z^2dz-\frac{J}{2}log(2\pi) =−21∫N(z;μ,σ2)z2dz−2Jlog(2π)
= − J 2 l o g ( 2 π ) − 1 2 E z ∼ E ( z ; μ , σ 2 ) ( z 2 ) =-\frac{J}{2}log(2\pi)-\frac{1}{2}\mathbb{E}_{z \sim \mathbb{E}(z;\mu,\sigma^2)}(z^2) =−2Jlog(2π)−21Ez∼E(z;μ,σ2)(z2)
= − J 2 l o g ( 2 π ) − 1 2 ( E z ∼ N ( z ; μ , σ 2 ) 2 ( z ) + V a r ( z ) ) =-\frac{J}{2}log(2\pi)-\frac{1}{2}(\mathbb{E}^2_{z \sim \mathcal{N}(z;\mu,\sigma^2)}(z)+Var(z)) =−2Jlog(2π)−21(Ez∼N(z;μ,σ2)2(z)+Var(z))
= − J 2 l o g ( 2 π ) − 1 2 ∑ j = 1 J ( μ j 2 + σ j 2 ) =-\frac{J}{2}log(2\pi)-\frac{1}{2}\sum^J_{j=1}(\mu^2_j+\sigma^2_j) =−2Jlog(2π)−21∑j=1J(μj2+σj2)
其中 J 是 z 向量的维数,同理还可以得到:
∫ q ϕ ( z ∣ x ) l o g q ϕ ( z ∣ x ) d z \int q_\phi(z|x)log\ q_\phi(z|x)dz ∫qϕ(z∣x)log qϕ(z∣x)dz
= − J 2 l o g ( 2 π ) − 1 2 ∑ j = 1 J ( 1 + l o g ( σ j 2 ) ) =-\frac{J}{2}log(2\pi)-\frac{1}{2}\sum^J_{j=1}(1+log(\sigma^2_j)) =−2Jlog(2π)−21∑j=1J(1+log(σj2))
最终,KL 散度的计算可以简化为:
− K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) -KL(q_\phi(z|x)||p_\theta(z)) −KL(qϕ(z∣x)∣∣pθ(z))
= ∫ q ϕ ( z ∣ x ) ( l o g p θ ( z ) − l o g q ϕ ( z ∣ x ) ) d z =\int q_\phi(z|x)(log\ p_\theta(z)-log\ q_\phi(z|x))dz =∫qϕ(z∣x)(log pθ(z)−log qϕ(z∣x))dz
= 1 2 ∑ j = 1 J ( 1 + l o g σ j 2 − μ j 2 − σ j 2 ) =\frac{1}{2}\sum^J_{j=1}(1+log\ \sigma^2_j-\mu^2_j-\sigma^2_j) =21∑j=1J(1+log σj2−μj2−σj2)
而为了优化公式(3)中的第一项,使用 MSE 损失即可,因此最终的计算过程可以总结为下图(引自[4]):
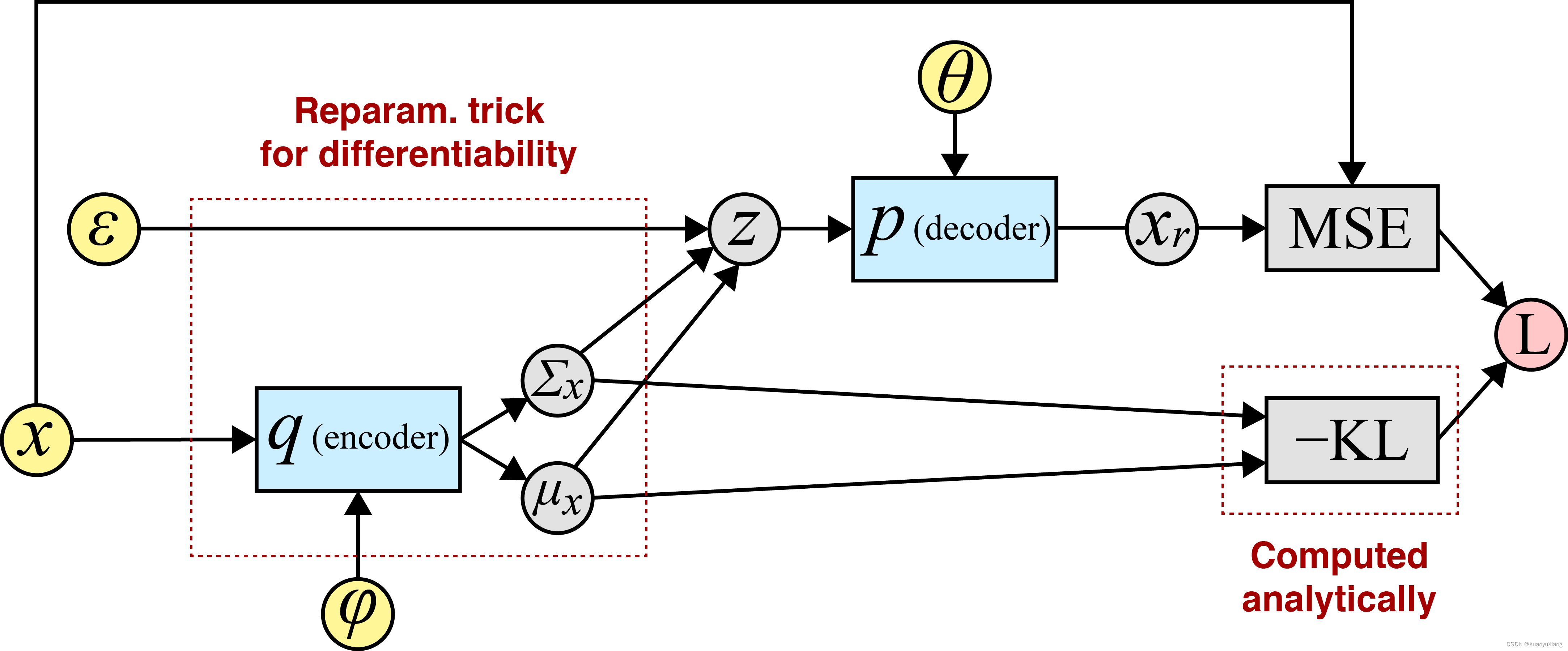
参考
[1] Understanding Variational Autoencoders (VAEs)
[2] [论文简析]VAE: Auto-encoding Variational Bayes[1312.6114]
[3] From Autoencoder to Beta-VAE
[4] The Reparameterization Trick
补充自2022年10月18日
关于 evidence:p(x)
在很多任务里,需要计算数据的分布
p
(
x
)
p(x)
p(x),根据贝叶斯公式,可以知道:
p ( x ) = ∫ z p θ ( x ∣ z ) p ( z ) p(x)=\int_z p_\theta(x|z)p(z) p(x)=∫zpθ(x∣z)p(z)
上面讨论过这个是 intractable 的,并引入了 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 进行近似计算,因此可以进一步写成:
p ( x ) = ∫ q ϕ ( z ∣ x ) p θ ( x ∣ z ) p ( z ) q ϕ ( z ∣ x ) p(x) = \int q_\phi(z|x) \frac{p_\theta(x|z)p(z)}{q_\phi(z|x)} p(x)=∫qϕ(z∣x)qϕ(z∣x)pθ(x∣z)p(z)
l o g p ( x ) = l o g E z ∼ q ϕ ( z ∣ x ) [ p θ ( x ∣ z ) p ( z ) q ϕ ( z ∣ x ) ] log\ p(x) = log\ \mathbb{E}_{z \sim q_\phi(z|x)}[\frac{p_\theta(x|z)p(z)}{q_\phi(z|x)}] log p(x)=log Ez∼qϕ(z∣x)[qϕ(z∣x)pθ(x∣z)p(z)]
根据 Jenson 不等式,可以得到:
l o g p ( x ) ≥ E z ∼ q ϕ ( z ∣ x ) l o g [ p θ ( x ∣ z ) p ( z ) q ϕ ( z ∣ x ) ] log\ p(x) \ge \mathbb{E}_{z \sim q_\phi(z|x)}log\ [\frac{p_\theta(x|z)p(z)}{q_\phi(z|x)}] log p(x)≥Ez∼qϕ(z∣x)log [qϕ(z∣x)pθ(x∣z)p(z)]
不等式右边的项也就是 evidence lower bound(ELBO),VAE 的目标是尽可能最大化 ELBO,这样 p ( x ) p(x) p(x) 也就会更大。这里就和前面联系起来了,为了计算 ELBO:
E L B O ELBO ELBO
= E q ϕ ( z ∣ x ) [ l o g ( p θ ( x ∣ z ) ) ] − K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ) ) =E_{q_\phi(z|x)}[log(p_\theta(x|z))]-KL(q_\phi(z|x)||p_\theta(z)) =Eqϕ(z∣x)[log(pθ(x∣z))]−KL(qϕ(z∣x)∣∣pθ(z))
第一项用 MSE 处理,为了计算第二项 KL 散度,作者假设 p θ ( z ) ∼ N ( 0 , I ) , q ϕ ( z ∣ x ) ∼ N ( μ , σ 2 ) p_\theta(z) \sim \mathcal{N}(0, I),\ q_\phi(z|x) \sim \mathcal{N}(\mu,\sigma^2) pθ(z)∼N(0,I), qϕ(z∣x)∼N(μ,σ2),为了在反向传播中使梯度能够通过不可导的 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 采样这一步,引入了重参数化技巧,此时 ϵ \epsilon ϵ 仅仅作为网络的输入,不参与梯度传播,梯度通过相关系数 μ , σ \mu,\sigma μ,σ 进行传播。

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









