






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
推荐阅读
42个pycharm使用技巧,瞬间从黑铁变王者Google C++项目编程风格指南 (中文版) 分享

2020 年顶会论文中,很多都会将关系加入到注意力机制的获取中。
除了该文,还有 2020 年 CVPR 的基于视频的 Multi-Granularity Reference-Aided Attentive Feature Aggregation for Video-based Person Re-identification、基于图像的Relation-Aware Global Attention 等。
该方法都会在这些论文中有着很好的效果,可见这是在行人重识别领域一大发展。
论文名称:Relation-Guided Spatial Attention and Temporal Refinement for Video-Based Person Re-Identification(基于关系引导的空间注意力和时间特征提取的基于视频的行人再识别)
第一作者:Xingze Li
通讯作者:Wengang Zhou
作者单位:CAS Key Laboratory of Technology in GIPAS, EEIS Department,中国科学院电子工程与信息科学系 University of Science and Technology of China(中国科学技术大学)
01
看点
RGSA(relation-guided spatial attention)模块:每个 spatial 位置的注意力由它的特征和与所有位置的关系向量决定(也就是关系引导),并最终融合为一个frame的特征,它能够捕捉局部和全局信息,同时定位特征区域而抑制背景信息。同时作者提出,感受野要尽量的小,才能提取出更加具有区别性的特征。
RGTR(relation-guided temporal refinement)模块:所有帧与帧的关系信息使得各个帧之间能够相互补充,有助于增强帧级特征表示。
RM 关系模块:计算特征之间的关系使用的方法不再是 dot 或 inner,而是自己开发了一种 RM 关系模块来生成两个特征的关系向量。
GRV(global relation vector):通过计算每个 spatial 位置的的关系和各个frame 之间的关系,生成 spatial-level 和 frame-level 的 GRV。并分别用在了RGSA 和 RGTR 模型中。
PS:Spatial feature:指的是以(i, j)每个像素为单位的特征。为 1x1xC 维度。

02
Motivation
基于图像的所获得的信息是有限的,尤其是当受到遮挡或者有异常点时。
基于视频的行人重识别领域中,通常的做法是将局部信息融合为全局,然后估计全局(frames)或局部(parts)区域的质量,并将质量用作融合特征的权重。通常,这些方法仅仅单独考虑每个区域的质量,而忽略了区域内的质量差异和上下文信息。
03
Contribution
基于视频领域经常使用的方法是RNNs、卷积运算和注意力机制对空间和时间信息进行建模。他们中使用光流来提取低层次的运动信息,或者使用注意力机制来评估每个frame的质量分数。与这些捕捉局部信息的方法不同,我们的方法利用很少探索的全局关系信息来引导空间注意力和时间特征提取。
传统的 Non-Local Mechanisms 中,特征之间的相似性被归一化以用作关注,并且每个特征由所有特征的加权和来更新。在所有上述非局部机制中,特征通过加权求和操作来更新,其中相似的特征具有大的权重。
缺点:这种方法在有效获取上下文信息和识别更新特征的区别区域方面存在局限性。我们的:与这些方法不同,我们的方法探索全局关系信息以聚焦于informative foreground,并使框架在上下文中相互补充。
提出新的 RM 模型用来提取时间和空间特征之间的关系,生成 GRV,可以使得在空间位置上定位特征区域而抑制背景信息。每个位置的注意力由它的特征和与所有位置的关系向量决定,它能够捕捉局部和全局信息。又能在空间位置上进一步提取和增强帧之间的特征,所有帧内的关系信息使得各个帧能够相互补充,有助于增强帧级特征表示。
04
Method
主要介绍总体框架、RM(relation module), 基于 RM 生成的 GRV 全局关系向量、RGSA(relation-guided spatial attention module)、 RGTR (relation-guided temporal refinement module)、Loss function
Framework Overview
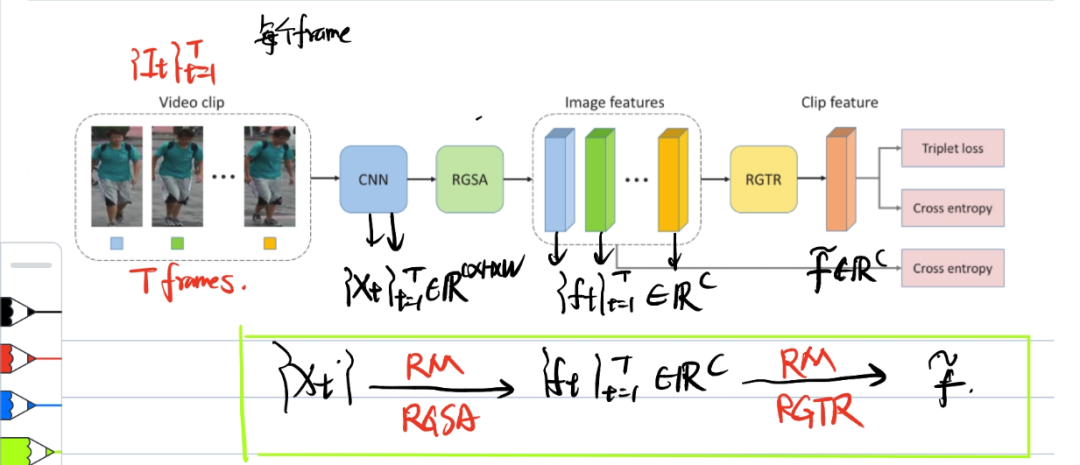
输入:video clip,T 帧 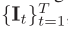
过程:
T帧分别进入CNN生成特征图
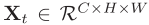 (t=1~n-1)
(t=1~n-1)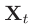 进入 RGSA(以 spatial 为单位,找各个之间的关系),生成被关系引导attention 后组合成帧级特征向量的
进入 RGSA(以 spatial 为单位,找各个之间的关系),生成被关系引导attention 后组合成帧级特征向量的 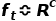
ft进入RGTR(找Frame之间的关系),其特征的平均混合为一个视频级特征向量
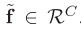
采用的损失包含:帧级的交叉熵损失、视频级的交叉熵损失、三元组损失。
Relation Module
两个特征之间的关系,一般使用 np.inner() 或者是 np.dot() 来计算的,但是
Inner product(内积)只是表明这些特性在多大程度上是相似的。从这种关系中不能推断出一些详细的信息,如哪些部分相似,哪些部分不同。
np.dot() 则使得差异关系并不紧密,包含冗余信息、计算消耗。
因此,我们开发了一个关系模块来生成两个特征的关系向量,与内积和差相比,该关系向量既信息丰富又紧凑。
框架:
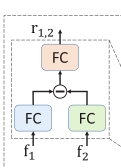
可以看到的是,输入两个特征,计算两者关系
目的:就是设计一个 RM 模型,通过计算来获取两个特征之间的关系!
步骤:
输入: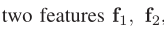
过程:
① 计算两个特征的差异
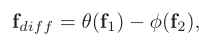 其中
其中
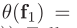
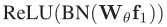 、
、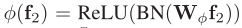
全连接层中参数权重 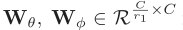
② 以 difference 为基础,计算 more compact relationvector
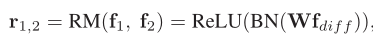
其中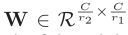
输出: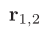
Relation-Guided Spatial Attention
学习 attention 来关注 foreground object(应该关注的地方),但是传统的Deep stack of convolutional operations时,有效感受野比理论感受野小得多。也就是说,你用卷积来做的话,必然卷积核是大于等于1的,但是往往informative的区域比这还小。也就是 local-aware。
因此我们
提出 Local-aware,以(i, j)每个像素为单位的D层的特征,每个空间位置的注意力由它的特征以及来自所有位置的关系向量决定,揭示了局部和全局信息之间的依赖性。
生成的 GRV 通过和原特征 concat 后经过 FC 层生成权重信息,可以生成被关系引导的 attention,从而更好的实现特征聚合。
框架:GRV 和 RGSA
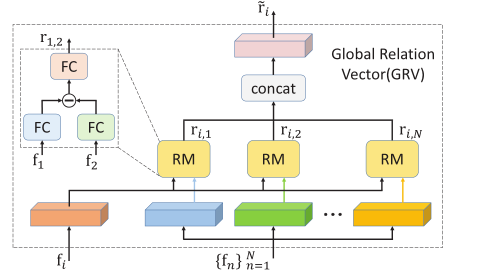
GRV(步骤①~③) 生成关系向量
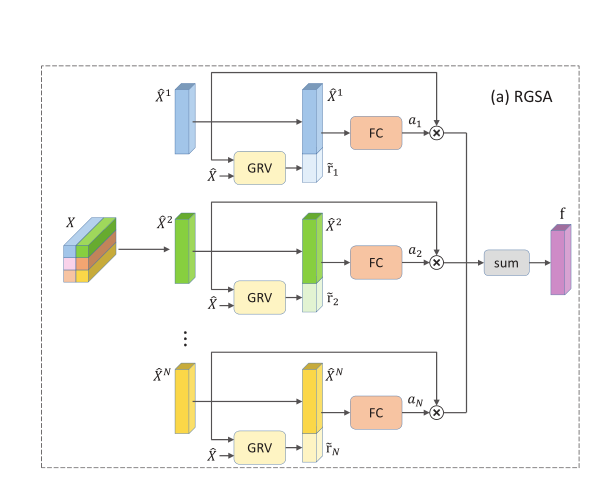
RGSA(步骤④和⑤)
GRV 关系特征和 特征 concat 后经过 FC 层被称为是关系引导
特征 concat 后经过 FC 层被称为是关系引导
步骤:
输入: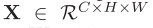 (未经处理的 frame-level 的特征)
(未经处理的 frame-level 的特征)
过程:
① Reshape 成 spatial vector(X)
一个图像的 Feature maps 是。因此有 N(N= H × W)个不同的空间位置,并且每个特征都是C维度的。因此加以 reshape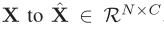 。其中
。其中 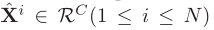 表明是第 i 个位置的特征。
表明是第 i 个位置的特征。
②利用 RM 来计算第i个位置特征和其它位置的关系向量
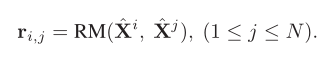
③ 生成全局 global 关系向量
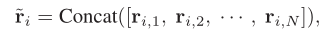
其中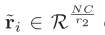 包含全局比较信息
包含全局比较信息
④ 生成 spatial-level 的 GRV
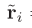 与 original feature
与 original feature 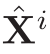 结合,之后通过全连接层和BN层,生成空间注意力得分。
结合,之后通过全连接层和BN层,生成空间注意力得分。
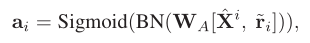
其中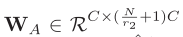 ,
,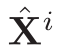 和
和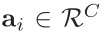
⑤生成 frame-level 特征 f(Xàf)(关系是用的 spatial-level)
最终特征向量融合了空间注意力,为:
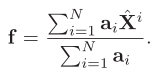
输出:经过处理的 frame-level 特征 f
Relation-Guided Temporal Refinement
在 Temporal feature fusion 上,常用的方法估计不同帧的质量,并通过加权求和操作融合特征。
但是缺点是:当相互比较时候,乘以低质量的frames可能会包含更多信息(低质量的特征可能也会包含有用的信息),因此我们利用不同的帧可以相互补充,并被细化和聚合以增强区分能力的特性,开发了一个关系引导的时间提取模块,通过它与其他帧的特征的关系来提取帧级特征。
框架:
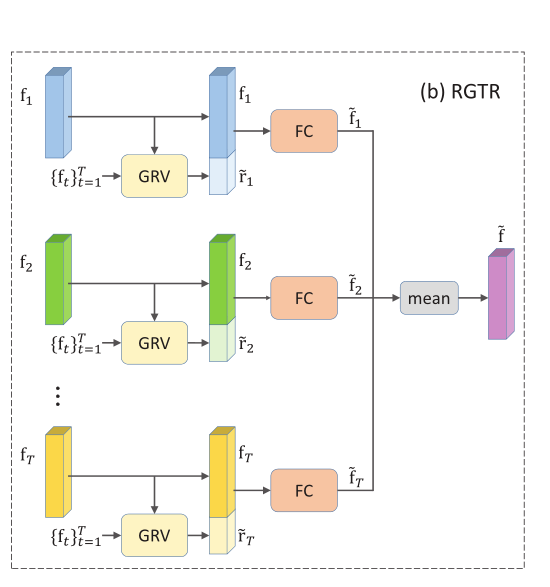
目的:获得最终特征!方法和 RGSA 相似!只是最后不再根据权重来计算每一帧的输出,而是求平均。因为,不同 frame 可能含有不同的区别性特征!
步骤:
输入: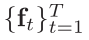 (经过CNN和RGSA层之后的)
(经过CNN和RGSA层之后的)
过程:
① 获得 frames 之间的成对关系
通过 RM 获得
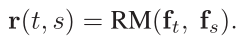
② 生成 frame-level 的 GRV
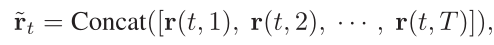
其中 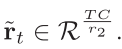
③ 生成 frame-level 特征(关系使用的是 frame-level)
利用 GRV 与 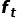 的concat,之后通过 FC 层和 BN 层生成特征
的concat,之后通过 FC 层和 BN 层生成特征
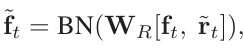
④ 生成 clip-level 特征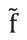
与上面不同的是,这里直接求 mean
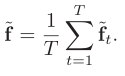
其中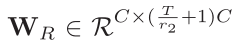 、
、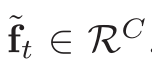
补充:GRV 在两个框架的作用
① RGSA
开发辨别区域并抑制背景(因为有权重啊!背景多很显然是被降低了权重)
② RGTR
增强 frame-level 特征的 discriminative 能力,从而强化增强 frame-level 特征的 discriminative 能力,从而强化 clip-level 的特征表示
Loss Function
整体是由交叉熵损失函数和三元组损失组成
cross entropy loss(交叉熵损失函数)
输入:each batch 包含了 P identities and K video
过程:和大多数方法是一样的
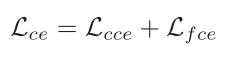
其中 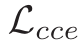 是 Clip-level 的交叉熵损失
是 Clip-level 的交叉熵损失
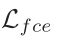 是 frame-level 的交叉熵损失,用于增强帧级特征的区分能力
是 frame-level 的交叉熵损失,用于增强帧级特征的区分能力
triplet loss
输入: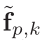 ,p 行人的第 k 个 clip
,p 行人的第 k 个 clip
P 行人的 positive 样本 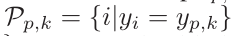
P 行人的 negative 样本 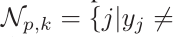
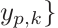
过程:
Triplet loss方法一般分为batch hard triplet loss和adaptive weighted triplet loss,其中前者选择距离最近的和最远的正负样本,而后者在所有样本,硬样本权重较大,简单样本权重较小。作者选择了后者。
正样本的权重:
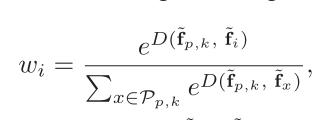
负样本的权重:
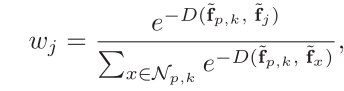
Triplet Loss:
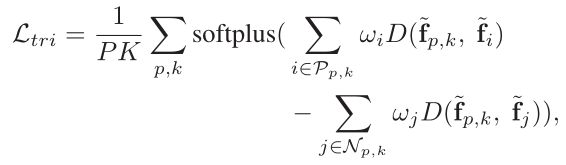
其中,
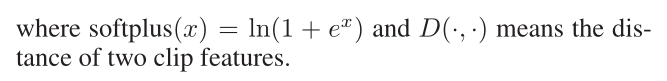
Overall:
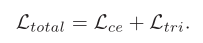
05
Experiments
Implementation Details
Train:
① 数据集:MARS、DukeMTMC-VideoReID、iLIDS-VID、PRID-2011;
② 实验细节:在训练阶段随机从视频中挑选T帧,每个 batch 包含 P 个行人 ID,每个行人 ID 包含 K 个视频;数据输入采取随机翻转、随机擦除;骨干网络采用预训练的 ResNet50;训练阶段选取帧数为 T/2;采用 4 块 NVIDIA Tesla V100 GPU进行训练测试;
其中:Resnet50 框架,最后一层要改掉。

③ 参数设置:P = 18,K = 4,即batch size = 72 T;输入图像规格为 256*128;训练器为 Adam,其 weight decay = 5*10-4;迭代次数为 375 次;学习率为 3*10-4,在 125 个 epoch 和 250 个 epoch 后均下降到 0.1 倍。
Test:
①T->T/2
②所有的 Clip-level 的 frames 被提取之后,并使用 L2 正则化来生成序列特征
③使用余弦距离来匹配 query 和 gallery 的图像
06
Ablation Study
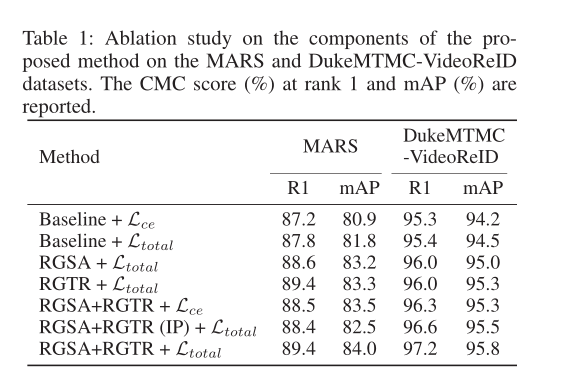
可以看到在 baseline 基础之上分别添加损失 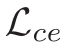 和
和 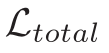 ,添加 RGTA 和RGTR 之后性能都有提升!证明了方法的有效性。
,添加 RGTA 和RGTR 之后性能都有提升!证明了方法的有效性。
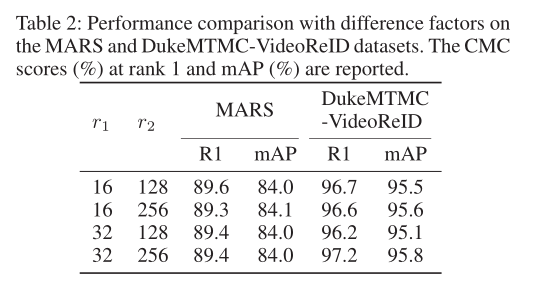
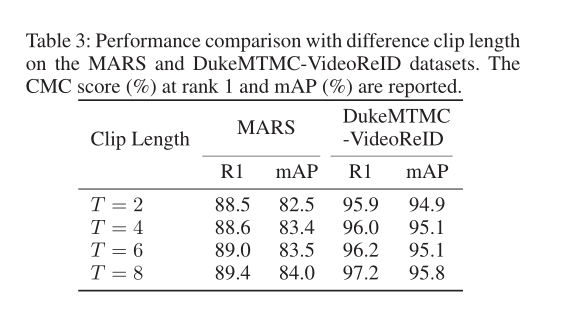
Table2 和 3 是分别试验了 difference factors 和 difference clip length 的 rank1 和 mAP 分数。
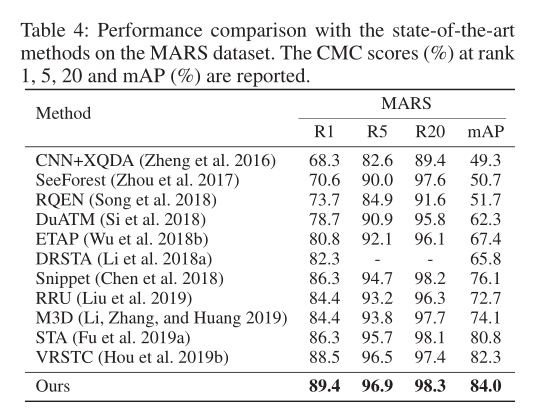
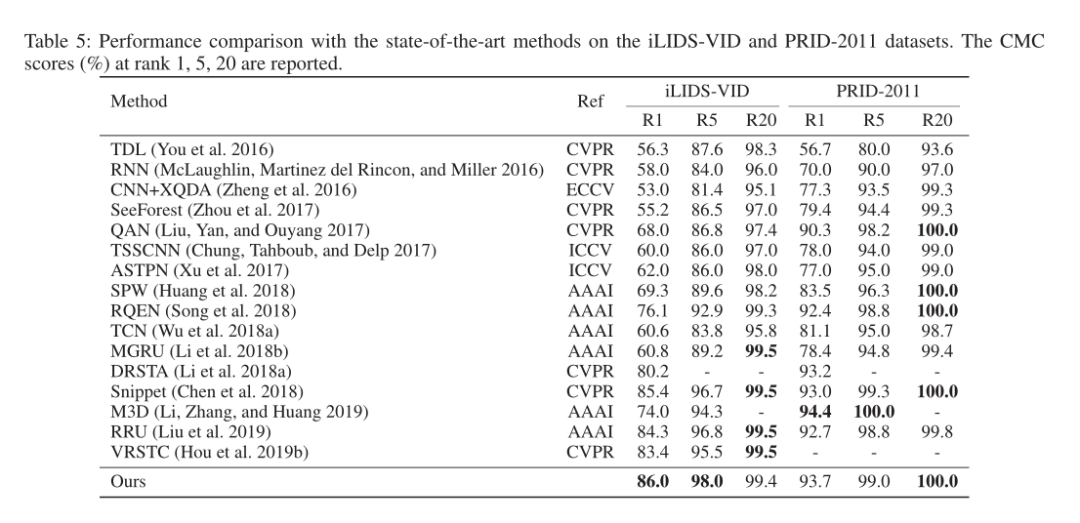
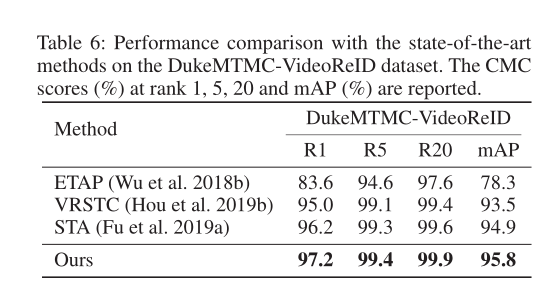
分别与在 MARS dataset、iLIDS-VID and PRID2011 dataset、DukeMTMC-VideoReID dataset 三个数据集效果。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目31讲
在「小白学视觉」公众号后台回复:Python视觉实战项目31讲,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
下载4:leetcode算法开源书
在「小白学视觉」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









