






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达前言
文本是人类最重要的信息来源之一,自然场景中充满了形形色色的文字符号。OCR(Optical Character Recognition,光学字符识别)相信大家并不陌生,就是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
工业场景的图像文字识别更加复杂,出现在很多不同的场合。例如医药品包装上的文字、各种钢制部件上的文字、容器表面的喷涂文字、商店标志上的个性文字等。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此难以检测和识别图像字符。
对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
OCR的应用领域:
文字识别OCR通常应用在证件识别(身份证,驾驶证,护照,名片)、文档检索、截图识别等等。
OCR对图片都做了什么:
实际上我们预期的结果是把只有包含单个文字的图片交给计算机去翻译。
机器是怎么看到纸质或者电子文档或是图片上的文字的呢?接下来看一下他的工作流程。
工作流程:
首先要去掉杂质,这样程序就可以集中注意到文字上面。
预处理:
预处理主要包括灰度化,二值化,噪声去除,倾斜矫正等。
灰度化:
灰度图是只含亮度信息,不含色彩信息的图片。
在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值。
一般满足下面这个公式:
Gray=0.299R+0.587G+0.114B 这种参数考虑到了人眼的生理特点。

原图.jpg

灰度图.jpg
二值化:非黑即白
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
经过灰度处理的彩色图像还需经过二值化处理将文字与背景进一步分离开。
二值化的过程中涉及到“阈值”的概念,简单来说就是想找到一个合适的值来作为一个界限,大于或小于这个界限的值变为白色或黑色即0或255。那么“阈值”是怎么选出来的?
有很多方法,这里先介绍下面两种:
方法1:
取阈值为127(相当于0~255的中数,(0+255)/2=127),让灰度值小于等于127的变为0(黑色),灰度值大于127的变为255(白色),这样做的好处是计算量小速度快,但是缺点也是很明显的,因为这个阈值在不同的图片中均为127,但是不同的图片,他们的颜色分布差别很大,所以用127做阈值,这种一刀切,效果肯定是不好的。

方法2:
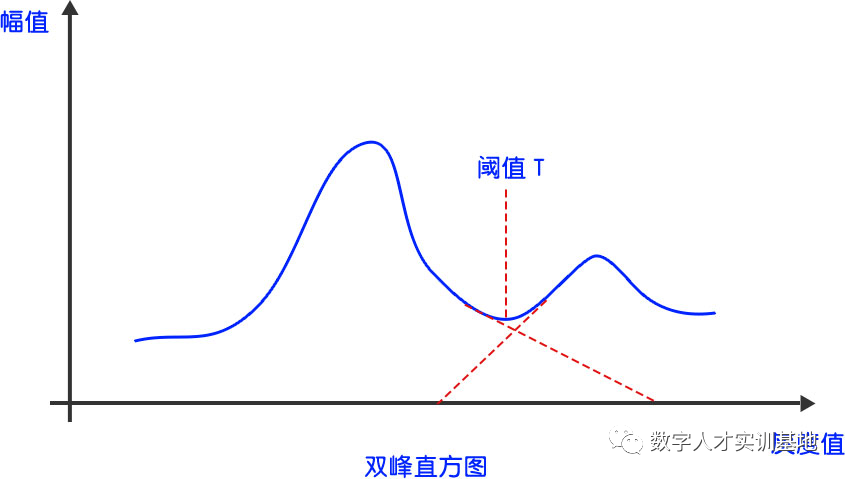
使用直方图方法(也叫双峰法)来寻找二值化阈值,直方图是图像的重要特质。直方图方法认为图像由前景和背景组成,在灰度直方图上,前景和背景都形成高峰,在双峰之间的最低谷处就是阈值所在。
下图就可以将小于T的视为全部为黑色,大于T的为白色。
图像降噪:
现实中的数字图像在数字化和传输过程中常受到成像设备与外部环境噪声干扰等影响,称为含噪图像或噪声图像。减少数字图像中噪声的过程称为图像降噪(Image Denoising)。
在演示的过程中可以看到当二值化之后的图片会显示很多小点,这些都是不需要的信息,会对后面进行图片的轮廓切割识别造成极大的影响,降噪是一个非常重要的阶段,降噪处理的好坏直接影响了图片识别的准确率。
最简单的降噪方法是算法中学到的DFS或者BFS(深度搜索和广度搜索)。我们对w*h的位图先搜索所有联通的区域(值为1的,我们看起来是黑色的,连接起来的区域)。所有联通区域算一个平均的像素值,如果某些联通区域的像素值远远低于这个平均值,我们就认为是噪点。然后用0代替他。

倾斜矫正:
拍照或者选取的图片不可能完全是水平的,倾斜会影响后面切出来的图片,所以要对图片进行旋转。
倾斜矫正最常用的方法是霍夫变换,其原理是将图片进行膨胀处理,将断续的文字连成一条直线,便于直线检测。计算出直线的角度后就可以利用旋转算法,将倾斜图片矫正到水平位置。

OCR在生活和工作中的应用:
1.证件OCR识别
证件OCR识别技术一开始是基于PC的,近几年开始向移动端发展,主要有android,ios平台的SDK,目前成熟的有身份证识别,行驶证识别,驾驶证识别,护照识别等。
2.银行卡OCR识别
银行卡OCR识别主要用于移动支付绑卡,是一项非常有技术含量的细分OCR技术,目前有一些APP已经在用,如支付宝,微信的实名认证,还有疫情期间扫描身份证录入信息等极大的便利了生活和办公。
3.名片OCR识别
名片OCR识别这一类技术也非常成熟了,目前市场上名片管理的APP大多已经使用过这类技术。
4.文档OCR识别
其实OCR技术最早的时候就是用于识别文档的,基于扫描技术,主要针对图书,报刊等,把这些纸质文档进行电子化,目前中英文识别率也非常高。近几年也开始用于移动端的文档识别,扫一扫就可以识别。
5.票据OCR识别
票据OCR识别顾名思义用于各式各样的票据识别,基于模板机制,需要针对不同的票据,定制不同的识别要素,这项技术也称要素识别OCR,最早的其实运用的是银行行业,现在企业、金融、电信机构都在使用。
6.车牌OCR识别
车牌识别技术主要应用在智能交通,小区停车场等,车牌识别的原理其实技术对车牌进行OCR识别,再进行比对的过程,现阶段也发展的相对成熟。生活中用于监测违章车辆,破获交通事故追根溯源等。
从OCR所识别图像的环境中分析,应用场景可分为清晰且具有固定模式的简单场景以及非清晰且模式不定的复杂场景。复杂场景的文本识别的难度极高,原因包括但不限于:图片背景极为丰富,经常面临低亮度、低对比度、光照不均、透视变形和残缺遮挡等问题,而且文本的布局可能存在扭曲、褶皱、换向等问题,其中的文字也会存在字体多样、字号字重颜色不一的问题。在很多实际情况下拍摄设备发生抖动、对焦偏差产生的失焦或者被拍摄对象处在运动中产生抖动模糊,还有文本印刷质量低下、书页陈旧破损、背景干扰过多或者光线条件差等问题,都会产生这类文本图像,这是目前的OCR技术的面临的一大难题。
对于模糊、泛黄的图像我们可以使用超分辨率技术提升模糊的低质图像的质量。
超分辨率技术的基本思想是采用信号处理的方法,从给定的低分辨率图像中恢复出高分辨率图像,可以在不改变当前硬件设备的前提下获得高于成像系统分辨率的图像。该类技术多应用与图像修复、图像重建、监控图像超分、卫星图像超分和医学影像等场景。

模糊的低质文档尚且可以尝试嵌入超分算法等方式进行质量提升,但常见的还有一类低质文档却无法应用超分算法,那就是背景很复杂的表格形式的文档。这类文档可能字迹印制清晰整洁,但文字和表格线多重叠、交错和颜色混合。
对于每类场景下较为固定的表格的色彩和形式,可以使用传统图像算法消除背景中的表格线和背景字符,这样能极大的降低图像中目标文本检测和识别的难度。
表格的种类多姿多彩,根据有无边框可以划分有线表、少线表、无线表。表格样式复杂多样,如存在背景填充、光照阴影、单元格行列合并等情况。OCR表格识别技术能够减少表格处理时间也成为了近些年的技术突破点方向之一。

表格识别技术流程图
对于表格识别及相关内容提炼,传统的表格识别方法设计起来较为复杂,对于版面布局分析和表格结构的提取,图像处理的方法依赖各种阈值和参数的选择,难以满足现实生活中复杂多样的表格场景,今后在技术上还有待突破。
就实际应用来看,大量的OCR工程还都是传统的通过海量数据增强来达到识别精度要求,然而面对业务场景越来越多形形色色的多样性,在项目效率上的需求还有待提升。
我们每天都被文字所环绕,像我们的工作文案、书本、证件、商品的介绍都是文字组成的,OCR技术的运用,可以让有些工作变得简单化、智能化,以后他将伴随着我们的生活,让我们的生活更加智能。
来源:数字人才实训基地
本文仅做学术分享,如有侵权,请联系删文。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 2635
2635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









