






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达跟踪的评价指标有哪些?
首先明确评价目标跟踪算法的出发点:
希望所有出现的目标都要被及时找到;
希望每个目标的位置要与真实的目标位置一致;
希望每个目标都被分配一个唯一的ID,并且分配给这个目标的ID在整个序列中保持不变。
用于评价的文件
det.txt
这个文件是保存模型推理的检测结果的文件,内容如下:
1,-1,1359.1,413.27,120.26,362.77,2.3092,-1,-1,-1
1,-1,571.03,402.13,104.56,315.68,1.5028,-1,-1,-1
2,-1,1494.4,408.29,112.14,338.41,0.16075,-1,-1,-1
2,-1,572.83,364.89,128.96,388.88,-0.011851,-1,-1,-1
从左到右分别代表:
frame: 代表第几帧图片
id: 表示分配给这个检测框的id,在这里都是-1,那么表示的是没有id信息
bbox(四位): 分别是左上角的坐标以及检测框的长宽
conf:这个bbox包含物体的置信度,可以看到这里的数值并不是趋于0-1范围,分数越高代表置信度越高
MOT3D(x,y,z): 是在MOT3D中使用到的内容,但我们这里只关心MOT2D,所以这三个数值都设置为-1
可以看出以上内容提供的信息,和目标检测中推理出的信息没有太大区别,所以也在一定程度上可以用于检测器的训练。
gt.txt
这个文件和det.txt类似。
1,1,912,484,97,109,0,7,1
2,1,912,484,97,109,0,7,1
3,1,912,484,97,109,0,7,1
从左到右分别是:
frame: 代表第几帧图片
ID:表示的是轨迹的ID,可以看出gt里边是按照轨迹的ID号进行排序的
bbox: 分别是左上角的坐标以及检测框的长宽
是否忽略:0代表忽略,1代表不忽略
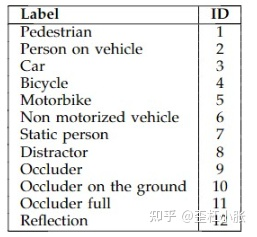
classes:目标的类别个数,因为在这个数据集中是12个类别,而7代表的是人,第8个类代表错检,9-11代表被遮挡的类别
评价过程的步骤
建立目标与标签之间的对应关系
对所有的对应关系,计算位置偏移误差
统计主要的误差:计算漏检数、计算误报数、跟踪目标在该序列中发生跳变的次数
目标跟踪的评价指标如下:
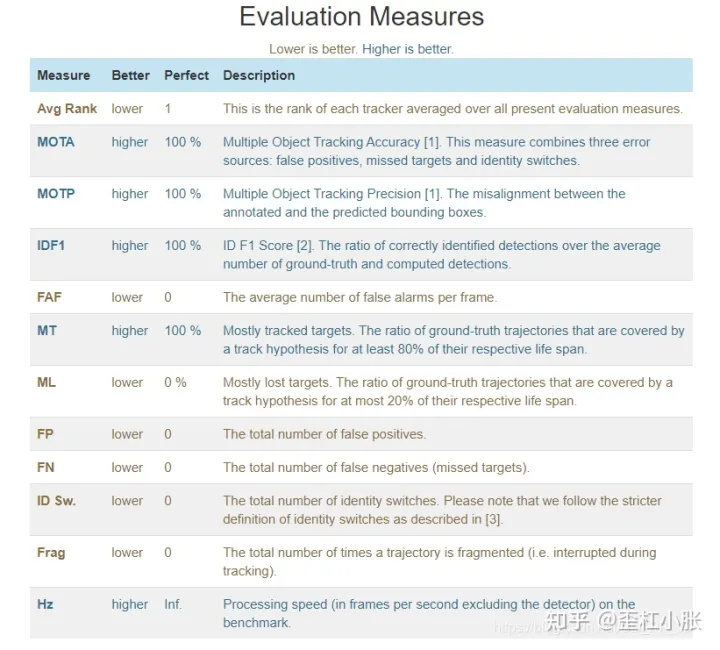
MOTA(Multiple Object Tracking Accuracy)
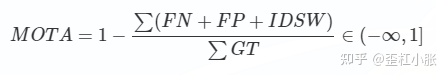
MOTA主要考虑在跟踪中所有对象的匹配错误,主要是FP,FN,IDs。FN为False Negative,FP为False Positve,IDSW为ID Switch,即ID切换次数,GT是Ground Truth,表示的是物体的数量。
MOTA能非常直观地衡量跟踪器在检测物体和保持轨迹时的性能,与目标检测精度无关。它的取值一般小于100,当跟踪器产生的错误超过了场景中的物体时,MOTA就会变为负数。
MOTP(Multiple Object Tracking Precision)
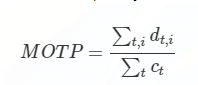
d为检测目标i和给它分配的ground truth之间在所有帧中平均度量的距离,在这里是使用框与框之间的IOU值进行度量。如果是通过IOU度量,那么MOTP是越大越好,但如果使用欧氏距离进行度量,那么MOTP就越小越好;而c为在当前帧匹配成功的数目。
MOTP主要量化检测器的定位精度,几乎和跟踪器实际性能没有关系。
注意 MOTA&MOTP是计算所有帧相关指标后再进行平均的,不是计算每帧的rate然后进行rate平均。
MT(Mostly Tracked)
Mostly Tracked表示的是满足Ground Truth在至少80%的时间内都成功匹配的track,在所有追踪目标中所占的比例。
ML (Mostly Lost)
Mostly Lost表示的是满足Ground Truth在小于20%的时间内匹配成功的track,在所有追踪目标中所占的比例。
注意这里的MT和ML与当前track的ID是否发生改变没有关系,只要Ground Truth能与目标匹配上就行了。
ID Switch
表示GT所分配的ID发生变化的次数。

FM (Fragmentation)
FM计算的是跟踪有多少次被打断,也就是Ground Truth的track没有被匹配上,换句话说:每当轨迹将其状态从跟踪状态变为未跟踪状态,并在稍后跟踪上相同的轨迹时,就会对FM进行计数。
在FM计数时要求ground truth的状态满足:tracked->untracked->tracked,如上图中(b)所示,而(c)中的不算FM。
需要注意的是,FM与ID是否发生变化无关。
FP (False Positive)
如果当前帧所预测的track和detection没有匹配上,将错误预测的track称为FP。是否匹配成功与匹配时所设置的阈值有关。
FN (False Negative)
如果当前帧所预测的track和detection没有匹配上,将未匹配上的gt称为FN,也可以称作Miss。
ID scores
MOTA也有缺点,因为它仅仅考虑跟踪器出错的次数,但是在一些场景中,比如航空场景,会更加关心一个跟踪器是否尽可能长时间地成功跟踪一个目标。这个可以通过构建二分图来解决,可以通过IDTP、IDFP、IDFN计算得出,具体指标有IDP、IDR、IDF1。IDP:
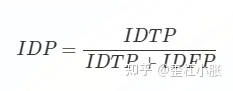
IDR:

正确识别的检测与真实数和计算检测的平均数之比IDF1
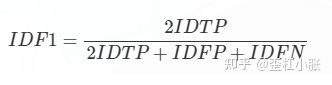
以上本文提到的,就是目标跟踪里大部分的评价指标了。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









