






论文信息
题目:Aligning, Autoencoding and Prompting Large Language Models for Novel Disease Reporting
对齐、自动编码与提示大语言模型用于新型疾病报告
作者:Fenglin Liu, Xian Wu, Jinfa Huang, Bang Yang, Kim Branson, Patrick Schwab, Lei Clifton, Ping Zhang, Jiebo Luo, Yefeng Zheng, and David A. Clifton
源码:https://github.com/ai-in-health/PromptLLM
论文创新点
- 提出全新框架:提出基于提示的深度学习框架PromptLLM,首次尝试在新型疾病标注数据稀缺的情况下进行新型疾病报告。该框架包含对齐、自动编码和提示三个组件,能够让深度学习框架在新型疾病早期阶段快速适应,实现高效的疾病报告。
- 降低数据依赖:通过独特的训练方式,PromptLLM仅利用1%的训练数据,就能在新型疾病报告任务上取得与之前使用完整数据集训练的最先进方法相媲美的性能,显著降低了对标注数据的依赖,为新型疾病早期数据分析提供了有力支持。
- 多任务拓展应用:除了新型疾病报告,还将生成的报告与输入图像相结合进行新型疾病分类,在六个数据集上都取得了具有竞争力的性能,拓展了模型的应用范围。
摘要
给定放射影像,自动生成放射学报告旨在产生能描述疾病的信息性文本,这对当前放射诊断临床实践具有重要意义。现有方法通常依赖临床医生标注的大规模医学数据集来训练理想模型。然而,对于新型疾病,如新型流行病或现有疾病的新变种,在早期阶段往往缺乏足够的训练数据。作者提出一种基于提示的深度学习框架PromptLLM,通过对齐、自动编码和提示大语言模型(LLM),实现准确高效地生成新型疾病报告。该方法主要包括三个步骤:(1)对齐视觉图像和文本报告,从有足够标注数据的疾病中学习跨模态通用知识;(2)利用新型疾病的未标注数据对大语言模型进行自动编码,学习新型疾病的特定知识和写作风格;(3)用学到的知识和写作风格提示大语言模型,以报告放射影像中包含的新型疾病。通过以上三个步骤,在新型疾病标注有限的情况下,PromptLLM能够快速学习相应知识,实现准确的新型疾病报告。在COVID-19和多种胸部疾病上的实验表明,作者的方法仅使用1%的训练数据,就能取得与之前使用完整数据集训练的最先进方法相媲美的性能。这表明该方法降低了对标注数据的依赖,有望在新型疾病早期数据分析中发挥实际作用。
关键字
大语言模型;新型疾病诊断;医学报告生成;少样本学习
1. 引言
利用放射影像报告疾病,即放射学报告生成,需要从输入的放射影像中理解临床信息,并生成相应的文本报告。在临床实践中,这项任务的首要目标和核心价值是准确描述相关疾病,从而为临床决策提供支持,如疾病诊断和治疗方案制定。自动报告疾病的能力有望减轻临床医生撰写报告的繁重工作。
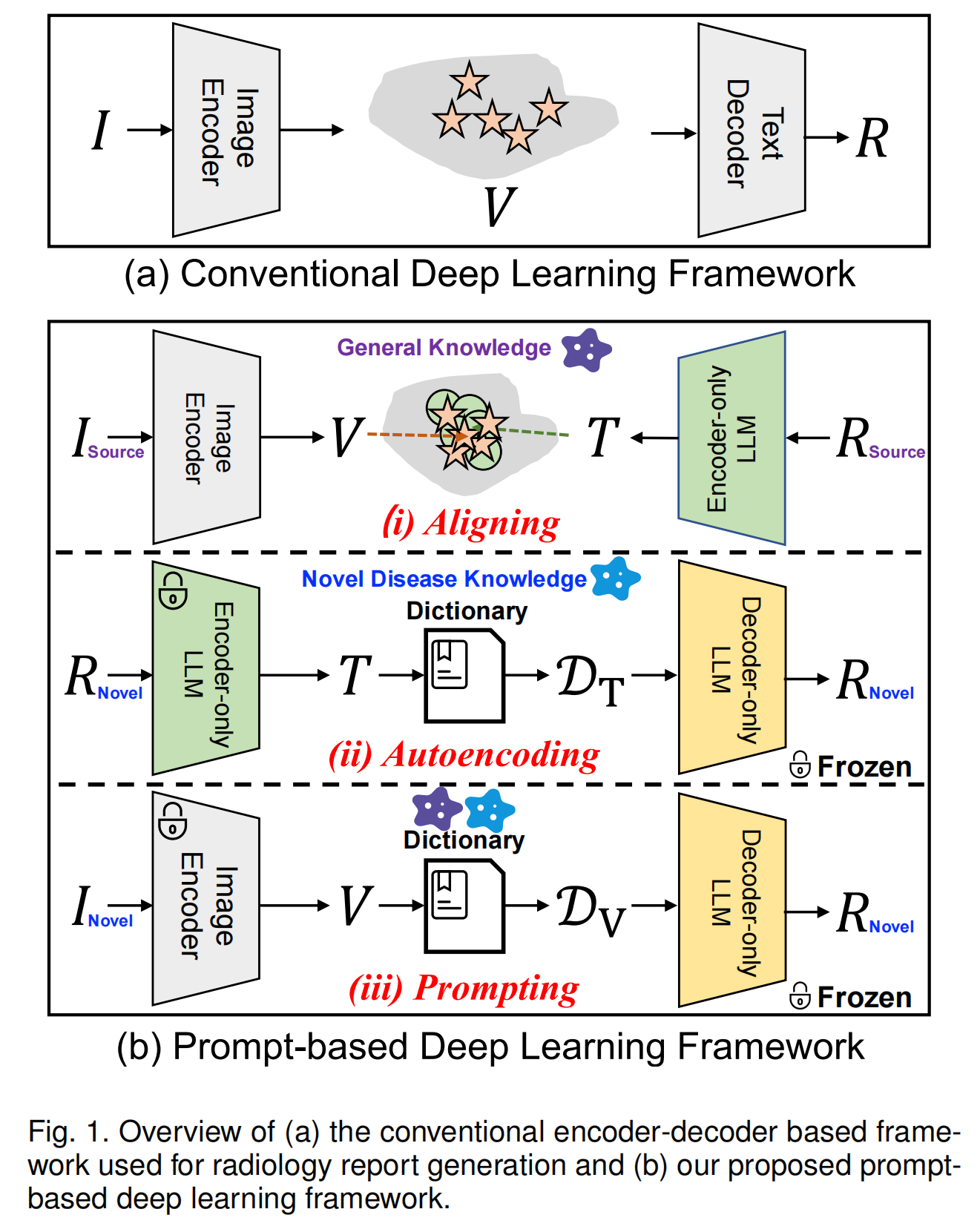
如图1所示,现有研究通常采用基于编码器 - 解码器的框架,包括图像编码器和文本解码器。图像编码器将放射影像 I I I转换为视觉表征 V V V,随后文本解码器将其解码为放射学报告 R R R。然而,这些方法依赖大量由临床医生标注的训练标签,即图像 - 报告( I − R I - R I−R)对,收集这些数据非常耗时。在新型疾病的情况下,如新型流行病或新变种,很难及时收集和标注足够的训练数据(一些研究收集足够数据花费了一年多时间),这使得此类编码器 - 解码器模型难以快速部署以应对新疾病。例如,即使在世界上一些最大的医院,COVID-19病例的收集时间也很长,直到疫情爆发约1.5年后的“第三波”,才拥有足够数量的病例用于传统模型的训练和验证。为此,作者构建了一个基于提示的深度学习框架PromptLLM,用于新型疾病报告。该方法适用于训练数据稀缺的情况,能够让深度学习框架在新型疾病(包括新型流行病或变种)的早期阶段快速适应,在遇到疾病后短时间内高效地报告疾病(而非发现疾病)。不过,该方法可与新型疾病发现方法相结合:当遇到新型疾病时,发现方法可及时提醒临床医生,然后作者的方法能使模型快速适应并部署,辅助临床医生诊断新疾病。这种结合的框架能为在新型疾病早期快速应对提供有效解决方案,在新型流行病中尤为重要,因为应对缓慢可能导致疫情最严重时期已过,医院也早已承受巨大压力。
详细来说,如图1所示,作者提出的框架包括对齐、自动编码和提示三个组件。以COVID-19为例,这个基于提示的框架通过以下方式准确高效地报告疾病:(1)对齐2019年前收集的类似但不同的胸部疾病的视觉图像和文本报告,学习跨模态的全面胸部通用知识;(2)用新型疾病COVID-19的未标注文本数据对语言模型进行自动编码,学习特定的新型疾病领域知识和写作风格,使模型更好地适应新型疾病领域;(3)用这些知识和写作风格提示模型,生成最终的临床描述,报告放射影像中新型胸部疾病COVID-19的临床发现。在实验中,作者通过“重现”COVID-19大流行的情况展示了该方法的有效性。实验表明,PromptLLM仅用1%的训练数据就能取得与先前工作相当的结果。这证明了它在极少标注数据下学习新情境的能力得到提升,这在未来面对新疾病时至关重要。总体而言,作者工作的贡献如下:
- 提出基于提示的深度学习框架PromptLLM,首次尝试在新型疾病标注数据稀缺的情况下进行新型疾病报告。
- 前瞻性实验(如在2019年前收集的疾病数据上预训练,对COVID-19进行预测)和回顾性实验证明了该方法的有效性,仅用1%的训练数据就能为新型疾病生成理想的报告。
- 除了新型疾病报告,作者还将生成的报告与输入图像相结合进行新型疾病分类。简而言之,在六个数据集上,该方法取得了与先前工作相媲美的性能。
2. 方法
2.1 公式化
如图1(a)所示,给定放射影像
I
I
I,报告疾病的目标是生成放射学报告
R
=
{
r
1
,
r
2
,
…
,
r
N
}
R = \{r_1, r_2, \ldots, r_N\}
R={r1,r2,…,rN},其中
r
i
r_i
ri表示报告中的第
i
i
i个单词。当前最先进的疾病报告系统通常由图像编码器(如ResNet-50)和文本解码器(如Transformer)组成,图像编码器用于提取视觉表征
V
V
V,文本解码器用于生成目标报告
R
R
R,可表示为:
图像编码器
:
I
→
V
;
文本解码器
:
V
→
R
.
(1)
\text{图像编码器} : I \to V; \text{文本解码器} : V \to R. \tag{1}
图像编码器:I→V;文本解码器:V→R.(1)
现有工作依赖图像 - 报告(
I
−
R
I - R
I−R)对来训练深度学习框架。给定输入放射影像的标注放射学报告,现有工作通过最小化监督训练损失(如交叉熵损失)来训练模型。然而,训练数据不足给构建描述新型疾病的模型带来了巨大挑战。
为此,作者提出如图2所示的基于提示的深度学习框架PromptLLM,它包括对齐、自动编码和提示三个组件,以在遇到新型疾病时生成准确理想的报告。与现有工作相比,该框架进一步引入了文本编码器和字典,可表示为:
{
对齐
{
图像编码器
:
I
→
V
文本编码器
:
R
→
T
自动编码
{
扩展编码器
:
R
→
T
字典
:
T
→
D
T
文本解码器
:
D
T
→
R
解码器
:
I
→
V
文本解码器
:
D
V
→
R
提示
{
图像编码器
:
I
→
V
字典
:
V
→
D
V
文本解码器
:
D
V
→
R
\begin{cases} \text{对齐} \begin{cases} \text{图像编码器} & : I \to V \\ \text{文本编码器} & : R \to T \end{cases} \\ \text{自动编码} \begin{cases} \text{扩展编码器} & : R \to T \\ \text{字典} & : T \to \mathbb{D}_T \\ \text{文本解码器} & : \mathbb{D}_T \to R \\ \text{解码器} & : I \to V \\ \text{文本解码器} & : D_V \to R \end{cases} \\ \text{提示} \begin{cases} \text{图像编码器} & : I \to V \\ \text{字典} & : V \to \mathbb{D}_V \\ \text{文本解码器} & : \mathbb{D}_V \to R \end{cases} \end{cases}
⎩
⎨
⎧对齐{图像编码器文本编码器:I→V:R→T自动编码⎩
⎨
⎧扩展编码器字典文本解码器解码器文本解码器:R→T:T→DT:DT→R:I→V:DV→R提示⎩
⎨
⎧图像编码器字典文本解码器:I→V:V→DV:DV→R
在对齐过程中,作者首先从有足够标注数据的类似但不同的疾病中收集训练标签。例如,对于COVID-19,可以利用2019年前收集的其他胸部疾病的标注标签。在实现过程中,为了公平比较,作者采用ResNet-50作为图像编码器,提取视觉表征
V
∈
R
B
×
d
V \in \mathbb{R}^{B \times d}
V∈RB×d,并采用BERT(一种仅编码器的大语言模型)作为文本编码器,提取输入报告的文本表征
T
∈
R
B
×
d
T \in \mathbb{R}^{B \times d}
T∈RB×d(
B
B
B表示批量大小,
d
d
d表示模型大小)。因此,文本编码器用于视觉图像和文本报告的对齐,以学习广泛的胸部知识。
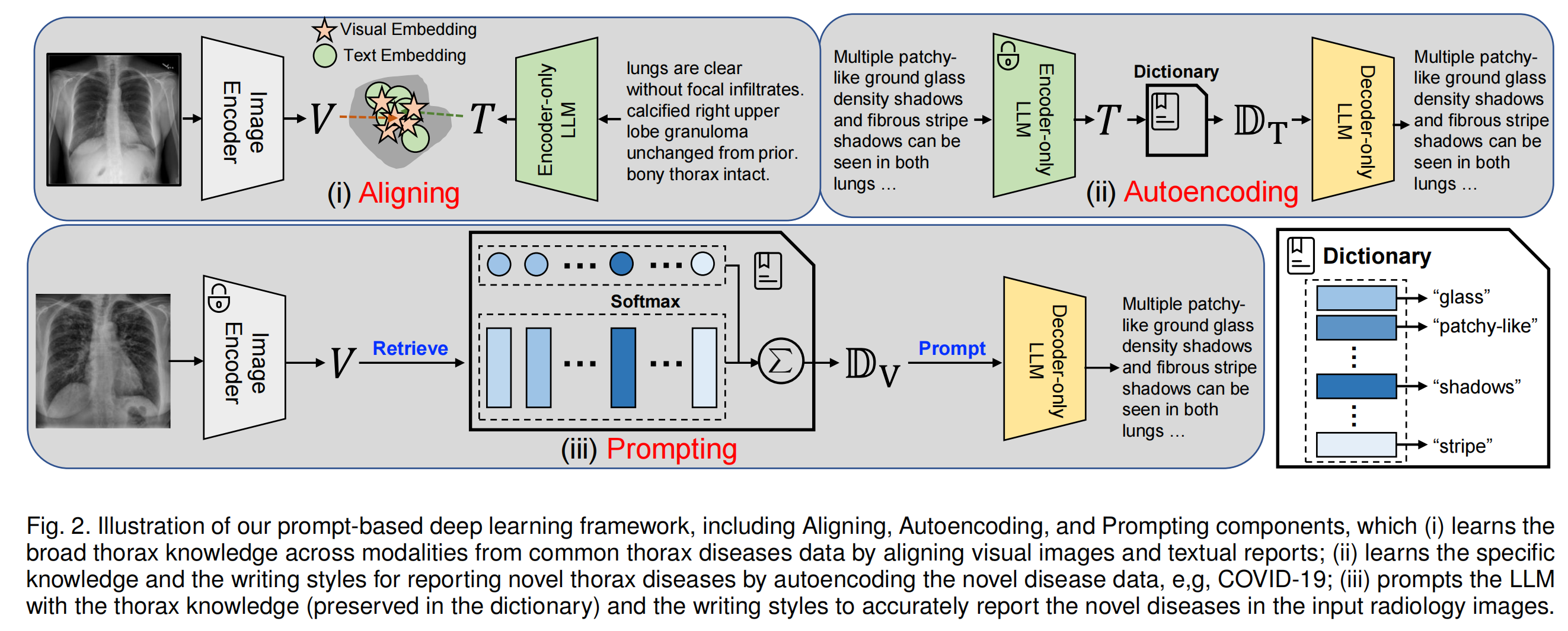
在自动编码过程中,由于新型疾病的标注数据通常数量不足,作者提出一种基于字典的自动编码器,引入字典( D \mathbb{D} D)和文本解码器,分别学习新型疾病领域知识和写作风格。作者通过在 R → D → R R \to \mathbb{D} \to R R→D→R的自动编码管道中重构输入报告 R R R来训练字典和文本解码器。由于自动编码过程重构相同的输入句子,模型训练相对简单,即学习提示。具体来说,作者构建一个字典 D = { d 1 , d 2 , … , d N D } ∈ R N D × d \mathbb{D} = \{d_1, d_2, \ldots, d_{N_D}\} \in \mathbb{R}^{N_D \times d} D={d1,d2,…,dND}∈RND×d,它由 N D N_D ND个可学习且固定的向量组成,用于学习和存储新型疾病的医学知识。为了从 T ∈ R B × d T \in \mathbb{R}^{B \times d} T∈RB×d得到 D T ∈ R B × d \mathbb{D}_T \in \mathbb{R}^{B \times d} DT∈RB×d,作者采用以下公式: D T = α D = ∑ k = 1 N D α k d k \mathbb{D}_T = \alpha \mathbb{D} = \sum_{k = 1}^{N_D} \alpha_k d_k DT=αD=∑k=1NDαkdk,其中 α = softmax ( T D ⊤ ) \alpha = \text{softmax}(T \mathbb{D}^{\top}) α=softmax(TD⊤)。在这个过程中, T T T可看作是检索字典 D \mathbb{D} D中疾病知识的“查询”。作者采用基于Transformer的模型作为文本解码器生成报告。因此,通过自动编码过程,引入的字典可以通过少量数据学习新型疾病所需的特定领域知识和写作风格。
在提示过程中,作者的方法将用学到的知识提示模型,以报告放射影像中的新型疾病。与自动编码过程类似,作者将 V V V作为“查询”,检索保存在字典 D \mathbb{D} D中的相关新型疾病知识,即 D V = β D = ∑ k = 1 N D β k d k \mathbb{D}_V = \beta \mathbb{D} = \sum_{k = 1}^{N_D} \beta_k d_k DV=βD=∑k=1NDβkdk,其中 β = softmax ( V D ⊤ ) \beta = \text{softmax}(V \mathbb{D}^{\top}) β=softmax(VD⊤)。最后,作者再次使用相同的解码器生成最终报告。作者在 I → D → R I \to \mathbb{D} \to R I→D→R的管道中提示模型生成新型疾病的临床描述。
在推理过程中,为了执行疾病报告任务,作者遵循 I → D V → R I \to \mathbb{D}_V \to R I→DV→R的管道,该管道不包括文本编码器,因此与现有工作( I → V → R I \to V \to R I→V→R,见公式(1))具有可比性。此外,作者遵循先前工作,进一步将生成的报告与原始输入图像相结合,执行额外的疾病分类任务。在实现过程中,生成报告的文本表征和输入图像的视觉表征被连接在一起,作为多标签分类网络的输入,以输出疾病类别。
2.2 对齐
在本小节中,作者提出对齐放射影像和医学报告,使模型能够从视觉和文本数据中学习广泛的知识。
先前工作通常采用MIMIC-CXR数据集,再加上外部大规模医学数据集(如CheXpert和ChestX-ray14)进行预训练,仅从视觉图像中学习医学知识。在作者的工作中,同样旨在学习医学知识,但与先前工作不同的是,作者引入信息噪声对比估计(InfoNCE)损失,同时从视觉图像和文本报告中学习广泛的医学知识,从而提高下游任务的性能。在训练过程中,作者使用MIMIC-CXR数据集,该数据集包含2019年前收集的常见胸部疾病数据,为了公平比较,未使用任何外部数据集。具体来说,如图2(i)所示,作者首先采样一批
B
B
B对
(
I
,
R
)
(I, R)
(I,R),编码为
(
V
,
T
)
(V, T)
(V,T),其中
v
i
v_i
vi和
t
i
t_i
ti分别表示第
i
i
i个输入放射影像和文本。然后,为了训练该方法,作者使用两个InfoNCE损失,即图像到文本损失
L
i
(
V
→
T
)
L_i^{(V \to T)}
Li(V→T)和文本到图像损失
L
i
(
T
→
V
)
L_i^{(T \to V)}
Li(T→V),定义如下:
L
i
(
V
→
T
)
=
−
log
exp
(
⟨
v
i
,
t
i
⟩
/
τ
)
∑
j
=
1
B
exp
(
⟨
v
i
,
t
j
⟩
/
τ
)
L
i
(
T
→
V
)
=
−
log
exp
(
⟨
t
i
,
v
i
⟩
/
τ
)
∑
j
=
1
B
exp
(
⟨
t
i
,
v
j
⟩
/
τ
)
\begin{align*} L_i^{(V \to T)} &= -\log \frac{\exp(\langle v_i, t_i \rangle / \tau)}{\sum_{j = 1}^{B} \exp(\langle v_i, t_j \rangle / \tau)} \\ L_i^{(T \to V)} &= -\log \frac{\exp(\langle t_i, v_i \rangle / \tau)}{\sum_{j = 1}^{B} \exp(\langle t_i, v_j \rangle / \tau)} \end{align*}
Li(V→T)Li(T→V)=−log∑j=1Bexp(⟨vi,tj⟩/τ)exp(⟨vi,ti⟩/τ)=−log∑j=1Bexp(⟨ti,vj⟩/τ)exp(⟨ti,vi⟩/τ)
其中,
⟨
⋅
,
⋅
⟩
\langle \cdot, \cdot \rangle
⟨⋅,⋅⟩和
τ
\tau
τ分别表示余弦相似度和温度参数。最后,将
L
i
(
V
→
T
)
L_i^{(V \to T)}
Li(V→T)和
L
i
(
T
→
V
)
L_i^{(T \to V)}
Li(T→V)相结合,完整的训练目标为:
L
f
u
l
l
=
1
B
∑
i
=
1
B
(
λ
L
i
(
V
→
T
)
+
(
1
−
λ
)
L
i
(
T
→
V
)
)
L_{full} = \frac{1}{B} \sum_{i = 1}^{B}(\lambda L_i^{(V \to T)} + (1 - \lambda) L_i^{(T \to V)})
Lfull=B1i=1∑B(λLi(V→T)+(1−λ)Li(T→V))
其中,
λ
∈
[
0
,
1
]
\lambda \in [0, 1]
λ∈[0,1]是控制正则化的超参数。作者根据验证集上的平均性能将
λ
\lambda
λ的值设置为0.75。作者推测原因是,由于最终目标是生成文本报告来报告新型疾病,较大的
λ
\lambda
λ值迫使视觉模态
V
V
V更接近文本模态
T
T
T,从而显著提升性能。
2.3 自动编码
当遇到新疾病时,现有的预训练深度学习方法通常会出现显著的性能下降,这是由新型疾病的新领域知识和新写作风格导致的。因此,为了在新型疾病的少量样本上高效训练和部署模型,作者提出对新型疾病数据进行自动编码,以学习新型疾病的特定知识和写作风格。自动编码组件由字典( D \mathbb{D} D)和文本解码器组成,用于学习新型疾病领域知识和写作风格。这里仅需要新型疾病的未标注文本报告。
如图2(ii)所示,作者首先采用文本编码器对新型疾病的医学报告进行编码,获取文本表征
T
∈
R
B
×
d
T \in \mathbb{R}^{B \times d}
T∈RB×d。然后,构建一个字典
D
=
{
d
1
,
d
2
,
…
,
d
N
D
}
∈
R
N
D
×
d
\mathbb{D} = \{d_1, d_2, \ldots, d_{N_D}\} \in \mathbb{R}^{N_D \times d}
D={d1,d2,…,dND}∈RND×d,其中
N
D
N_D
ND表示新型疾病知识(即提示)的总数,用于学习和存储新型疾病的医学知识,定义如下:
D
T
=
α
D
=
∑
k
=
1
N
D
α
k
d
k
,
其中
α
=
softmax
(
T
D
⊤
)
(5)
\mathbb{D}_T = \alpha \mathbb{D} = \sum_{k = 1}^{N_D} \alpha_k d_k, \text{其中} \alpha = \text{softmax}(T \mathbb{D}^{\top}) \tag{5}
DT=αD=k=1∑NDαkdk,其中α=softmax(TD⊤)(5)
可以看出,
T
T
T可看作是检索字典
D
\mathbb{D}
D中疾病知识的“查询”。最后,在获取
D
T
\mathbb{D}_T
DT后,作者采用基于Transformer的解码器,如先前工作一样,学习生成最终的放射学报告
R
R
R。作者通过基于
D
T
\mathbb{D}_T
DT重构输入报告
R
R
R来训练基于字典的自动编码器,以最小化交叉熵损失:
L
C
E
=
−
∑
t
=
1
T
log
(
p
(
r
t
∣
r
1
:
t
−
1
)
)
L_{CE} = -\sum_{t = 1}^{T} \log(p(r_t | r_{1:t - 1}))
LCE=−t=1∑Tlog(p(rt∣r1:t−1))
通过上述操作,作者的自动编码过程能够使模型在少量新型疾病数据上学习新型疾病的领域知识和写作风格。值得注意的是,作者提出的自动编码过程:(1)可以通过使用更多大规模的新型疾病未标注医学文本来进一步改进;(2)可以随着新型疾病的演变(如新型流行病/新变种),不断从新添加的医学文本中学习,以提升性能。因此,该方法为报告新型疾病提供了良好的基础。
2.4 提示
在自动编码之后,作者提出用学到的新型疾病领域知识和新写作风格提示模型,基于新型疾病的输入放射影像报告疾病。在实现过程中,作者首先采用图像编码器提取新型放射影像的视觉表征
V
∈
R
B
×
d
V \in \mathbb{R}^{B \times d}
V∈RB×d。然后,将
V
V
V作为“查询”,检索保存在字典
D
\mathbb{D}
D中的相关新型疾病知识:
D
V
=
β
D
=
∑
k
=
1
N
D
β
k
d
k
,
其中
β
=
softmax
(
V
D
⊤
)
(7)
\mathbb{D}_V = \beta \mathbb{D} = \sum_{k = 1}^{N_D} \beta_k d_k, \text{其中} \beta = \text{softmax}(V \mathbb{D}^{\top}) \tag{7}
DV=βD=k=1∑NDβkdk,其中β=softmax(VD⊤)(7)
在这个公式中,输入图像
V
V
V可看作“查询”,字典
D
\mathbb{D}
D可看作“键”和“值”。因此,注意力机制可以使字典中的提示与输入放射影像相关联,并确定关键提示来提示模型。在图2中,作者对检索到的提示进行可视化,以便更好地理解该方法。具体来说,作者计算提示与词汇表中单词嵌入之间的余弦相似度,然后采用相似度最高的单词将提示可视化为单词。最后,作者采用检索到的知识
D
V
\mathbb{D}_V
DV作为提示,提示解码器报告输入放射影像中的新型疾病。给定新型疾病的真实报告
R
=
{
r
1
,
r
2
,
…
,
r
N
}
R = \{r_1, r_2, \ldots, r_N\}
R={r1,r2,…,rN},作者再次采用交叉熵损失来训练框架:
L
C
E
=
−
∑
t
=
1
T
log
(
p
(
r
t
∣
r
1
:
t
−
1
)
)
L_{CE} = -\sum_{t = 1}^{T} \log(p(r_t | r_{1:t - 1}))
LCE=−t=1∑Tlog(p(rt∣r1:t−1))
在测试过程中,作者遵循
I
→
D
V
→
R
I \to \mathbb{D}_V \to R
I→DV→R的管道,生成测试放射影像
I
I
I的最终新型疾病报告
R
R
R。通过这种方式,作者的方法减少了对大规模标注数据集的依赖,仅用1%的训练数据就能取得与先前工作相媲美的结果。
3. 实验
在本节中,作者首先描述六个数据集、广泛使用的评估指标以及用于评估报告和分类性能的实验设置。然后,展示前瞻性和回顾性实验的结果。
3.1 数据集、指标和设置
3.1.1 数据集
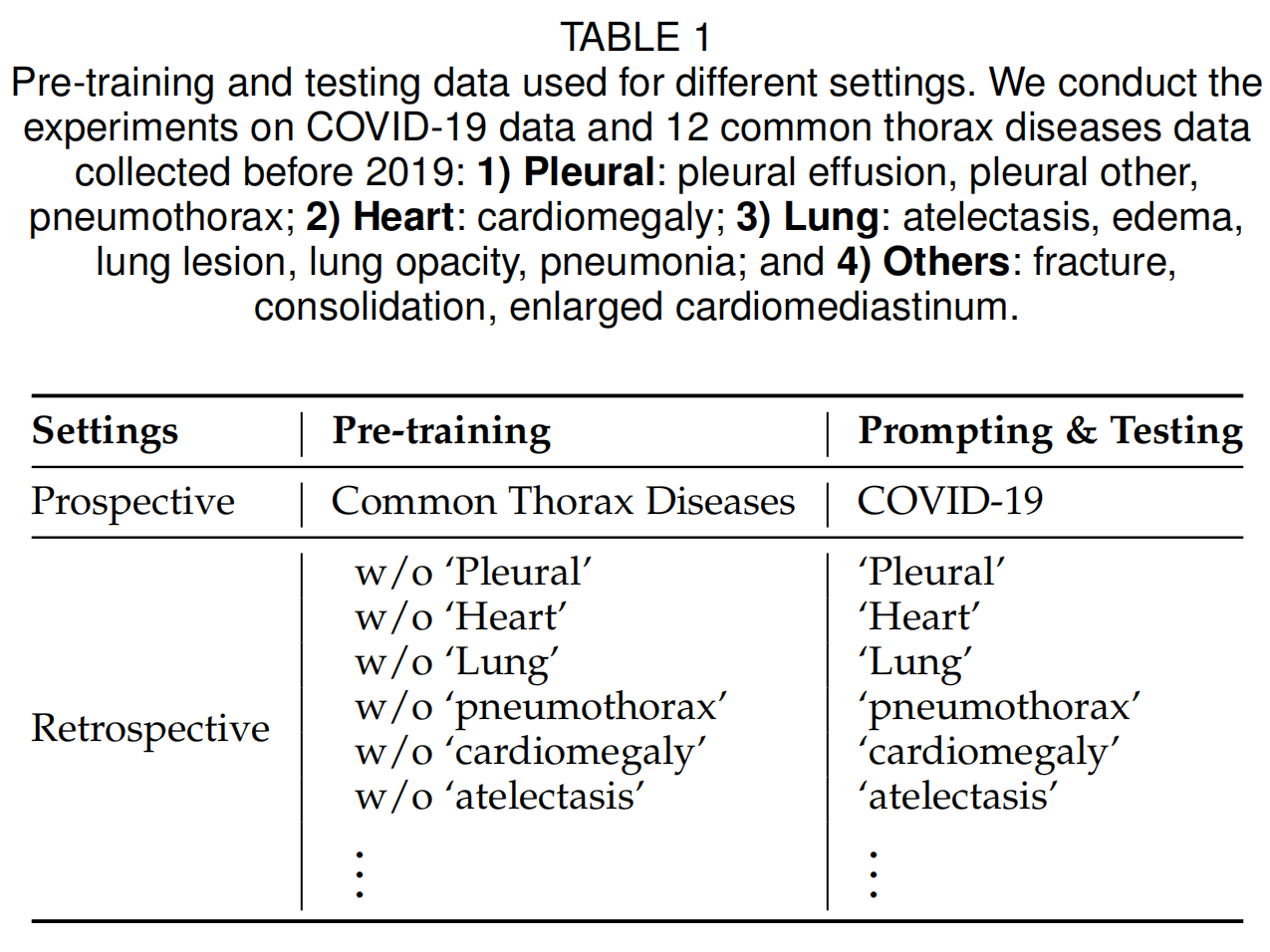
作者在六个数据集上评估提出的框架,包括四个COVID-19数据集,即COVIDx-CXR-2、COVID-CXR、BIMCV-COVID-19和COVCTR,以及两个常见疾病数据集MIMIC-CXR和NIH ChestX-ray。所使用的六个数据集均来自不同国家和地区的真实医院。(1)COVIDx-CXR-2包含来自51个国家的29,986张医学图像。(2)COVID-CXR由来自26个国家的472名患者的超过900张医学图像组成。(3)BIMCV-COVID-19是一个大型放射影像数据集,包含超过10,000张胸部X光片,这些图像收集自西班牙的1,311名COVID-19患者。(4)COV-CTR是由哈尔滨医科大学附属第一医院构建的COVID-19报告数据集,总共包含728张医学图像(349张COVID-19图像和379张非COVID图像)及相应的医学报告。(5)MIMIC-CXR是最近发布的数据集,由2011 - 2016年在贝斯以色列女执事医疗中心收集的377,110张医学图像组成,这些图像关联有文本放射学报告,包含2个标签(“未见异常”和“支持设备”)以及12种常见胸部疾病标签,用于指示疾病的存在或缺失,这些疾病包括“肺不张”“心脏肥大”“实变”“水肿”“纵隔增宽”“骨折”“肺部病变”“肺部阴影”“胸腔积液”“胸膜其他病变”“肺炎”“气胸” 。(6)NIH ChestX-ray是一个广泛使用的来自美国的数据集,包含112,120张放射图像,这些图像标注了来自30,805名患者的常见胸部疾病。最后,作者遵循先前的工作,对数据集进行预处理,并将它们随机划分为训练集、验证集和测试集,比例分别为8:1:1。
| 设置 | 预训练 | 提示与测试 |
|---|---|---|
| 前瞻性 | 常见胸部疾病 | COVID-19 |
| 回顾性 | 无“胸膜”相关疾病 | “胸膜”相关疾病 |
| 无“心脏”相关疾病 | “心脏”相关疾病 | |
| 无“肺部”相关疾病 | “肺部”相关疾病 | |
| 无“气胸”相关疾病 | “气胸”相关疾病 | |
| 无“心脏肥大”相关疾病 | “心脏肥大”相关疾病 | |
| 无“肺不张”相关疾病 | “肺不张”相关疾病 |
3.1.2 指标
对于报告任务,作者遵循常用做法,采用广泛使用的语言生成指标,即BLEU-4、ROUGE-L和CIDEr,这些指标用于衡量生成的报告与专业临床医生标注的真实报告之间的匹配程度。对于分类任务,作者采用广泛使用的AUC分类分数,它表示接收器操作特征(ROC)曲线下的面积。
- 前瞻性实验:作者通过在2019年前收集的MIMIC-CXR常见胸部疾病数据上进行训练,并在具有显著不同疾病知识和写作风格的COVID-19数据上进行评估,来执行前瞻性实验。
- 回顾性实验:作者在12种常见胸部疾病数据上进行回顾性实验:(1)胸膜相关疾病:胸腔积液、胸膜其他病变、气胸;(2)心脏相关疾病:心脏肥大;(3)肺部相关疾病:肺不张、水肿、肺部病变、肺部阴影、肺炎;(5)其他疾病:骨折、实变、纵隔增宽。以“肺不张”为例,作者将包含目标疾病“肺不张”的样本作为测试集,将不包含目标疾病“肺不张”的其余样本作为训练集。因此,训练集和测试集之间没有患者和目标疾病的重叠。
3.1.3 训练设置
作者的方法与图像和文本编码器/解码器的具体选择无关。为了进行公平比较,作者遵循先前的工作,采用用ImageNet初始化的ResNet-50作为图像编码器,采用Transformer作为文本解码器。因此,作者展示了方法的两个变体,即PromptLLM和PromptNet,它们分别采用LLAMA-2-7B和Transformer-BASE作为解码器。作者采用图像编码器提取2048维的特征图,然后使用多层感知器(MLP)层将其投影到512维的特征图。作者采用用MIMIC初始化的BERT来实现文本编码器。基于验证集上的平均性能,公式(4)中的 λ \lambda λ设置为0.75,字典中的 N D N_D ND设置为10,000。除了可学习的向量,作者还引入了用训练集中报告的嵌入初始化的固定向量。在对齐过程中,作者使用批量大小为100和学习率为 5 × 1 0 − 5 5\times10^{-5} 5×10−5。在自动编码和提示过程中,作者冻结图像编码器和文本编码器的参数;使用批量大小为32,学习率为 1 × 1 0 − 4 1\times10^{-4} 1×10−4,并引入文献中提到的数据损坏和增强技术。对于优化,作者采用AdamW优化器。作者基于CIDEr进行提前停止。在推理过程中,作者应用大小为3的束搜索。
3.1.4 测试设置
如表1所示,作者在少样本(1%)和完全监督(100%)设置下,对六个数据集进行前瞻性和回顾性实验,其中1%和100%表示分别使用训练分割的1%和100%数据进行微调(即提示)。
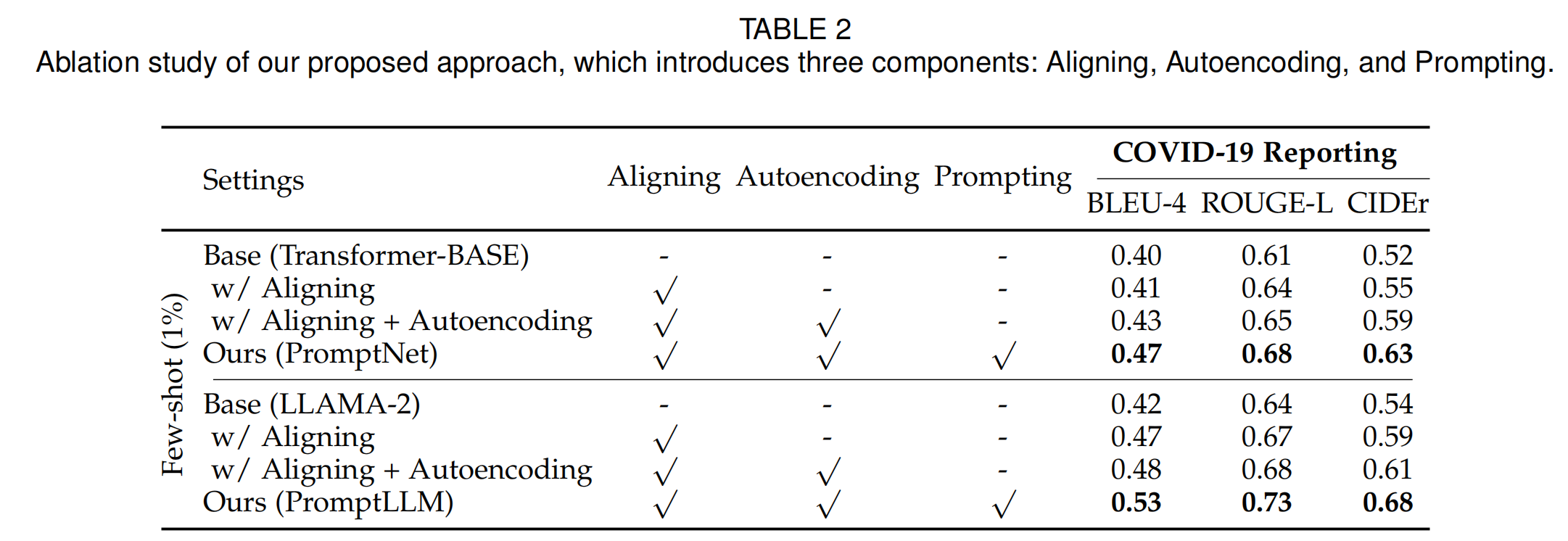
3.2 消融研究
作者对框架进行消融研究,以展示所提出的组件如何提高性能。表2中的结果表明,框架中提出的对齐、自动编码和提示组件都有助于提高性能,证明了每个组件的有效性。具体而言,通过比较“有对齐”和“基线”,可以观察到对齐在所有指标上都带来了改进,使得性能优于先前的方法,证明了通过对齐视觉图像和文本报告来学习广泛知识的有效性。比较“有对齐”和“有对齐 + 自动编码”可以发现,包含字典和文本解码器的自动编码组件可以进一步提高性能,这可能是因为新型疾病报告涉及显著不同的知识和写作风格,因此在数据稀缺时,学习新型疾病相应的特定知识和写作风格非常重要。有了提示模块(在CIDEr指标上从0.59提升到0.63,从0.61提升到0.68),完整模型能够取得更好的结果,这表明用医学知识提示模型对于准确报告新疾病的重要性。最后,作者观察到将三个组件结合起来会带来整体性能的提升。
3.3 前瞻性评估
在本节中,作者报告了模型遇到新型疾病(如在新的大流行期间)时的性能。以COVID-19为例,报告结果可以在表3的左侧找到。为了进行比较,由于作者首次尝试新型疾病报告,为了改进评估,在实验中实现了四种先前的方法,即R2Gen、PPKED、CMN和XProNet。具体而言,为了公平比较,在训练过程中,作者的方法和先前的方法都首先在常见胸部疾病上进行预训练,然后在COVID-19数据上进行微调。表3展示了作者模型的优越性能,在有限标签设置(1%)下,其BLEU-4分数比先前方法高出20.5%,ROUGE-L分数高出10.6%,CIDEr分数高出15.3%,并且仅用1%的数据进行训练就能与先前的完全监督方法(100%)取得相当的结果。同时,在使用完整训练数据(100%)时,作者提出的框架在所有指标上都取得了最佳性能。
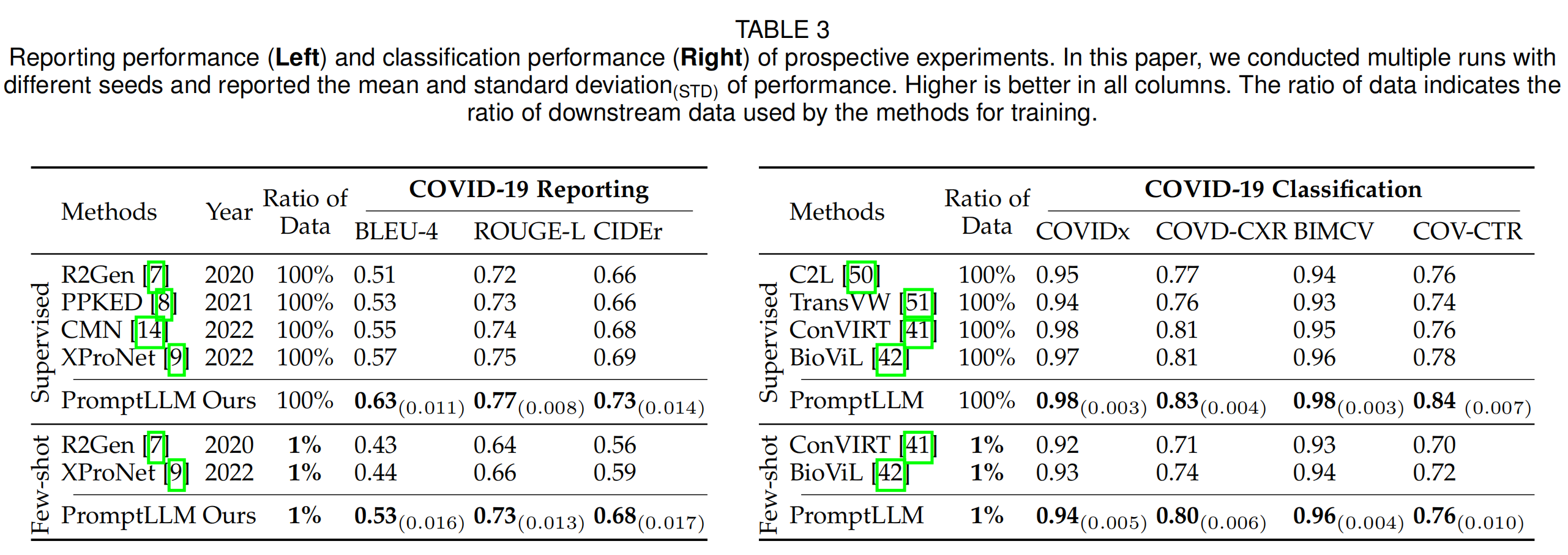
表3的右侧报告了在四个COVID-19数据集上的分类结果。在这个实验中,作者旨在区分COVID-19和非COVID-19病例。作者选择了四种现有的最先进方法进行比较,即C2L、TransVW、ConVIRT和BioViL,其中C2L、ConVIRT和BioViL利用了对比学习。作者的方法和先前的方法都首先在相同的常见胸部疾病数据上进行预训练,然后在下游的COVID-19数据集上进行微调,如现有工作一样。可以看出,使用1%的下游数据进行训练,作者的方法在COVIDx-CXR-2、COVID-CXR、BIMCV-COVID-19和COV-CTR数据集上的AUC分数分别比现有方法高出2%、9%、3%和6%。使用100%的下游数据进行训练,作者的方法在四个数据集上都创造了新的最先进性能。
COVID-19报告和分类在有限标签下的性能证明了作者方法的有效性,使其有潜力在遇到新的大流行时短时间内应用。
3.4 回顾性评估
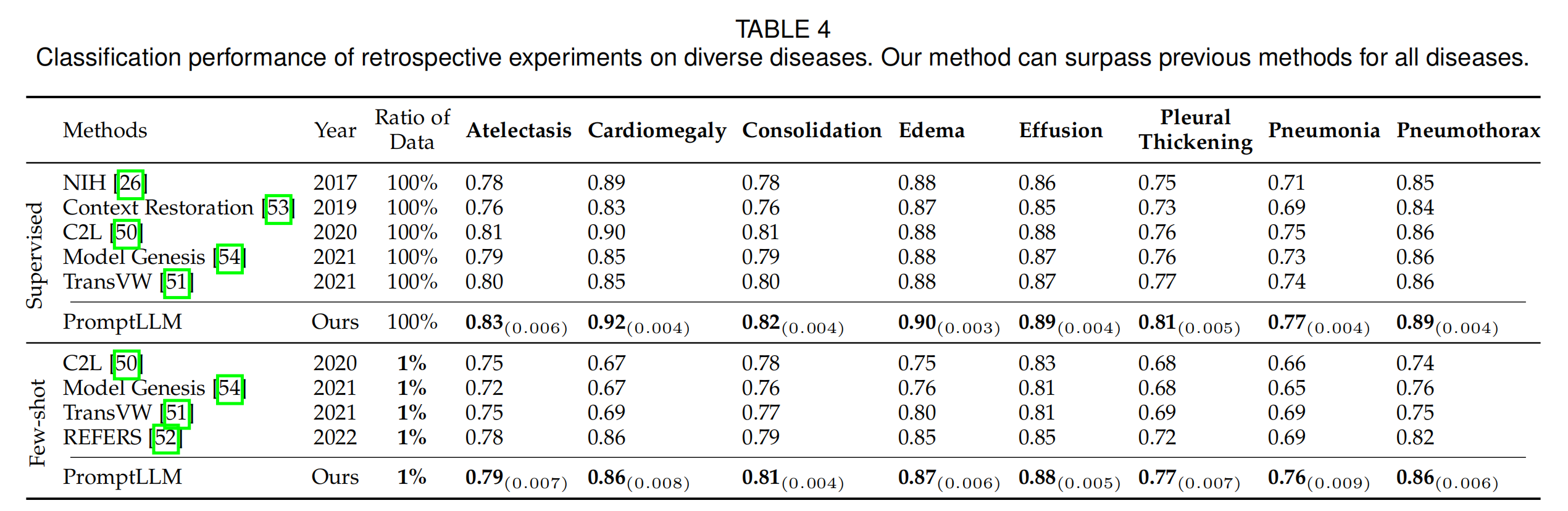
在表4中,作者报告了在各种常见胸部疾病上的分类性能。作者在广泛使用的NIH ChestX-ray数据集上进行实验。可以观察到,仅使用1%的训练数据,作者的PromptLLM在所有胸部疾病上的AUC分数比先前的少样本方法REFERS高出多达7%。更令人鼓舞的是,PromptLLM甚至在“实变”“胸腔积液”“肺炎”和“气胸”等疾病上超过了完全监督的方法,证明了作者框架在有限标签下对新型胸部疾病的有效性。与先前结果类似,使用100%标记的下游数据进行训练,PromptLLM创造了新的最先进结果。
4. 分析
4.1 GPT-4评估
在本节中,作者遵循先前的工作,采用GPT-4o进一步验证方法的有效性。具体而言,作者从COVID-19报告任务中随机选择200个样本。通过给出真实参考,让GPT-4o比较作者方法PromptLLM(1%数据训练)的输出和基线模型的输出,选择“两个模型中哪个输出更接近参考”。GPT-4o不知道这些输出是由哪个模型生成的。作者选择了两个强大的基线模型BiomedGPT和LlaVA-Med来展示GPT-4o的评估结果,结果如表5所示。可以看出,作者的方法比BiomedGPT和LlaVA-Med分别高出
92.0
−
2.5
=
89.5
92.0 - 2.5 = 89.5
92.0−2.5=89.5和
84.5
−
4.5
=
80.0
84.5 - 4.5 = 80.0
84.5−4.5=80.0个百分点。这表明作者方法生成的报告比竞争基线更接近真实情况,证明了该方法在为新型疾病生成准确报告方面的优势。结果进一步表明,作者的方法可以帮助模型更好地适应新型疾病领域,并对新型疾病的医学数据分析产生影响。

如表6所示,PromptLLM始终优于基线模型,在报告新器官或身体部位的新型疾病方面取得了可靠的性能。特别是,仅用1%的数据进行训练,PromptLLM在不同疾病组上就可以超过先前的少样本/完全监督方法,这进一步验证了作者方法在用学到的新型疾病领域知识和写作风格提示模型方面的有效性和鲁棒性,从而减少了对训练数据的依赖,能够用较少的标注数据为新型疾病生成更高质量的报告。同时,在“胸膜”相关疾病方面,使用1%的下游标记数据进行训练,作者的方法取得了卓越的性能,在所有指标上比之前所有完全监督方法的绝对分数高出2%的BLEU-4、3%的ROUGE-L和2%的CIDEr。使用100%标记的下游数据进行训练,作者的方法在所有疾病组的整体指标上都取得了最佳结果。这些改进的结果证明了作者方法的有效性,与先前方法相比,能够为以前未探索的身体部位或器官的新型胸部疾病提供更高质量的报告。

4.2 鲁棒性分析
在本节中,为了证明方法的鲁棒性,作者进一步对新型胸部疾病组进行实验。在实现过程中,作者根据器官或身体部位将常见胸部疾病构建为三个胸部疾病组(胸膜、心脏和肺部)。在训练过程中,作者将属于目标新型疾病组(例如“心脏”组)的样本作为测试集,将其余样本(不包含“心脏”相关疾病)作为训练集。这个分析在更具挑战性的场景中检验模型的性能。因为同一器官内的不同疾病可能具有共同特征,这个实验使得模型不能从同一器官先前疾病中采用类似特征来报告以前未见过的器官或身体部位的新型疾病。因此,这个针对新器官或身体部位的实验让作者能够在更具挑战性的设置中评估方法的泛化性和鲁棒性,在这种设置中,新型疾病的模式和特征可能与不同器官的疾病有显著差异。
4.3 持续学习
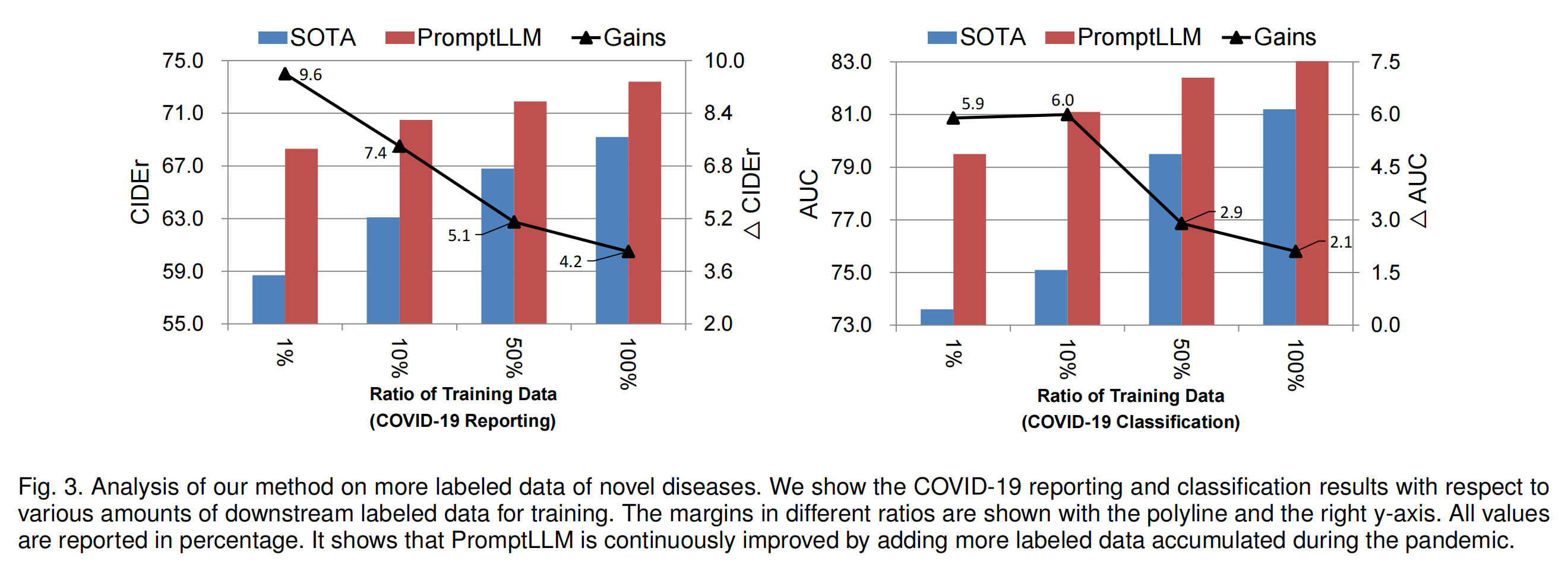
作者进一步评估了在大流行期间随着更多标记数据积累模型的性能。在图3中,作者报告了PromptLLM以及最近的最先进方法XProNet和BioViL在COVID-19报告/分类任务中,随着下游标记训练数据量增加的结果。对于COVID-19分类,作者报告了在广泛使用的COVID-CXR数据集上的结果。很明显,作者的方法可以通过纳入额外的新疾病数据进行训练进一步改进,并且始终优于先前的方法。此外,可以注意到训练数据越少,优势差距越大。更令人鼓舞的是,在1%训练数据设置下,PromptLLM在COVID-19报告和分类任务上分别比先前方法高出9.6%和5.9%的绝对优势。在低数据设置下的优势表明,作者的方法特别适合新型疾病,尤其是新的大流行和新变种,因为在早期阶段这些疾病的下游数据稀缺。此外,随着时间推移更多标记数据的积累,模型的性能有持续提升的潜力。因此,作者的方法可以提高深度学习模型在新型疾病方面的实际应用价值。
4.4 定性分析
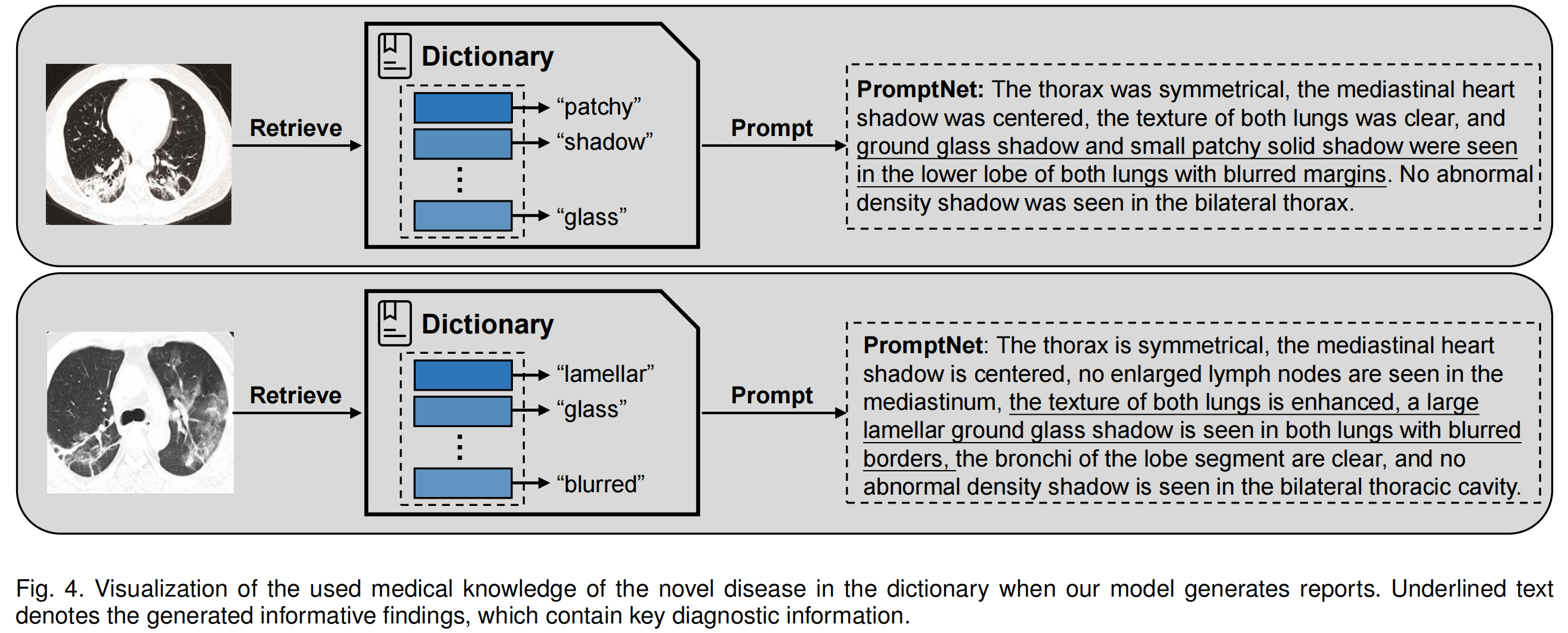
图4给出了两个例子,以更好地理解作者的方法,该方法有效地报告了新型疾病COVID-19,并生成了有重要正常和异常信息支持的理想结果。具体而言,在第一个例子中,作者的方法正确描述了关键异常情况,例如“双肺下叶可见磨玻璃影及小斑片状实变影”,并伴有“边缘模糊”等细节支持。同时,PromptLLM可以生成流畅的正常情况描述,例如第一个例子中的“双肺纹理清晰”“双侧胸腔未见异常密度影”,以及第二个例子中的“叶段支气管清晰”。对“字典”的可视化显示,作者的方法准确检索了新型疾病领域知识作为提示,以促进新型胸部疾病报告,例如第一个例子中的“影”和“玻璃”,以及第二个例子中的“片状”和“模糊”。总体而言,考虑到用于训练的COVID-19标记数据稀缺,PromptLLM报告新型疾病的能力令人鼓舞。
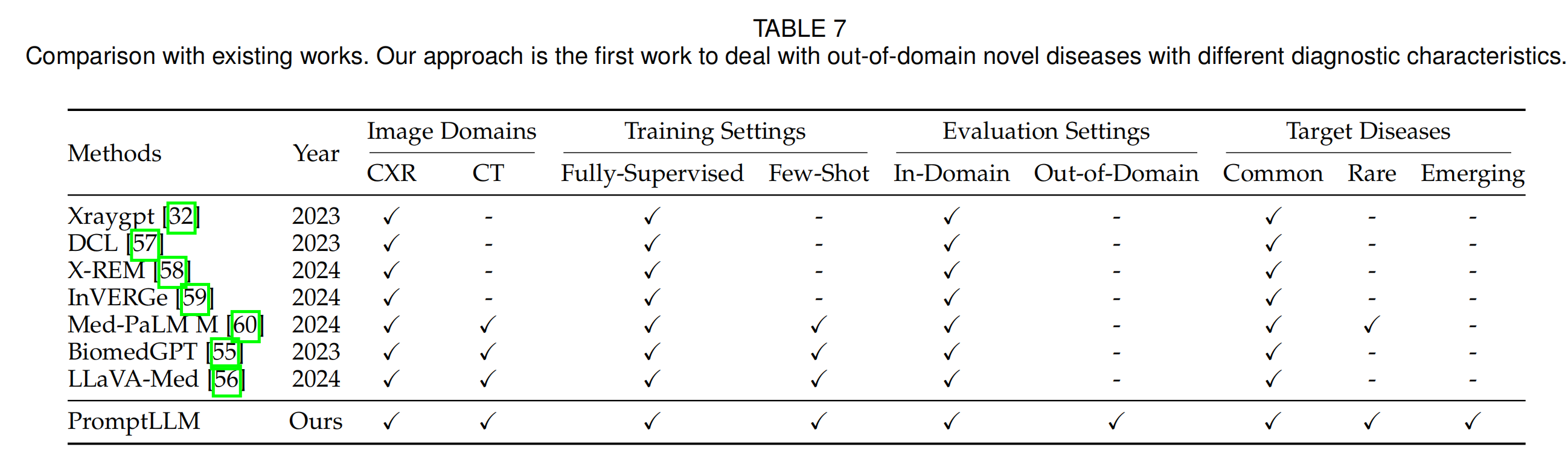
6. 结论
在本文中,作者提出了一种有效的新型疾病报告生成方法。该方法减少了对现有方法普遍依赖的标记数据的需求,为临床实践中稳健的疾病报告提供了坚实基础,使作者能够提出在真实临床环境中进一步开发和验证的工具。该方法对新型疾病(如新型大流行或现有疾病的新变种)特别有用,因为在早期阶段这些疾病的标签稀缺。在六个数据集上的广泛实验证明了该方法的有效性,其性能优于先前的最先进方法。
局限性
尽管作者的方法可以为低数据领域的疾病报告提供坚实基础,但该方法的有效性依赖于新型疾病知识的质量和相关性,对于某些疾病领域,这些知识可能不容易获得。此外,作者的实验是在胸部疾病上进行的,因此评估该方法在其他疾病领域的泛化性具有前景。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与作者联系,作者将在第一时间回复并处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











