






都2025了,还能靠注意力机制魔改发论文吗?毫无疑问没问题!南开大学就靠改进多头注意力,拿下CVPR25!清华姚期智院士也下场,提出新型注意力,节省90%内存,统一现代注意力设计!且ICLR、ICML等顶会也都有多篇……
其热度可见一斑!想发文的伙伴勇敢冲!但同时也要注意使用方法,不然不涨点反而掉点!比如,具体的任务场景,最好选该任务下效果突出的注意力。最典型的就是目标检测了,自注意力的效果无人能及!再有就是要考虑注意力放置的位置。你要是放在网络结构的末尾,可能就会因为通道数过多,而过拟合……
为方便大家理解和使用,实现高效涨点!我给大家把2024-2025有代表性的注意力机制魔改都进行了梳理,原文和源码都有,共174种!主要涉及注意力机制自身改、与其他技术结合两大路线!

扫描下方二维码,回复「174注意」
免费获取全部论文合集及项目代码

新一代注意力
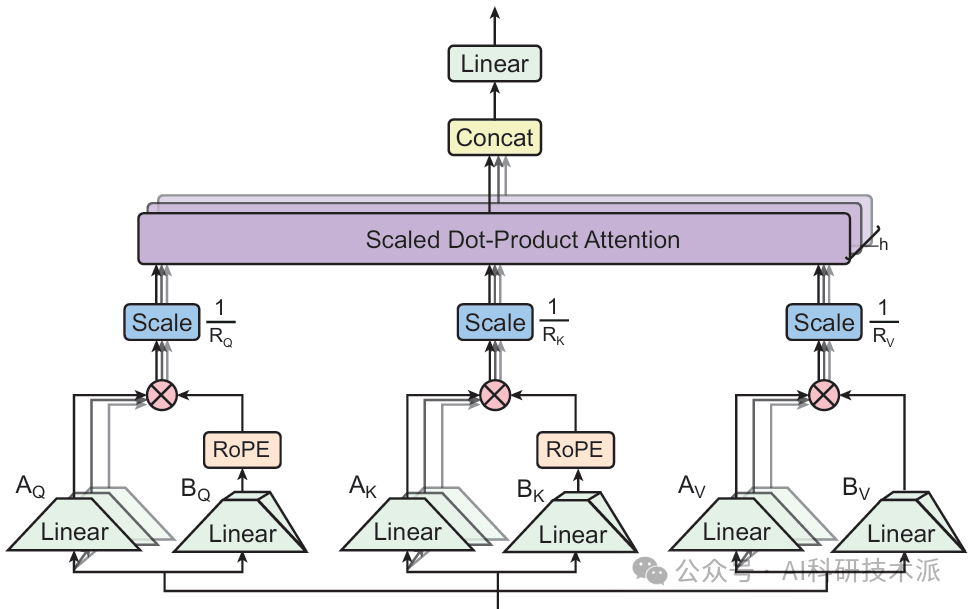
Tensor Product Attention Is All You Need
内容:论文提出了一种名为 Tensor Product Attention (TPA) 的新型注意力机制,通过张量分解来紧凑地表示查询(Q)、键(K)和值(V),显著减少了推理时的键值(KV)缓存大小,同时提升了模型性能。基于 TPA,作者还设计了T6模型架构,用于序列建模任务。实验表明,T6 在语言建模任务中优于标准 Transformer 基线(如 MHA、MQA、GQA 和 MLA),并且在固定资源约束下能够处理更长的序列,解决了现代语言模型中的关键可扩展性问题。
概念注意力
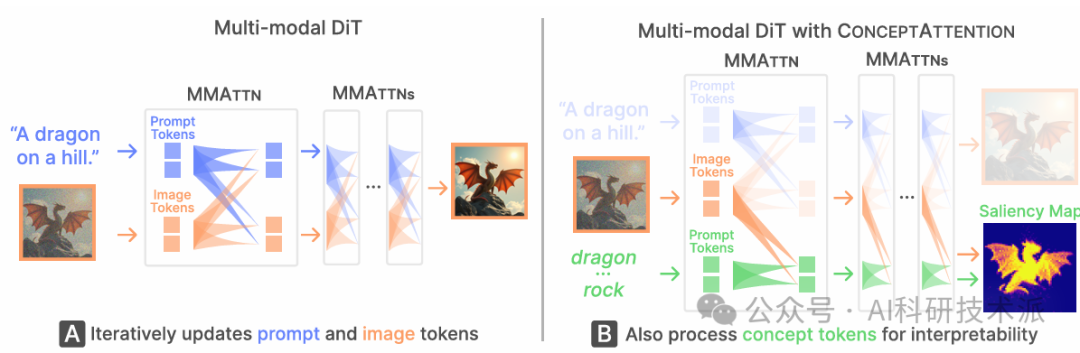
ConceptAttention: Diffusion TransformersLearn Highly Interpretable Features
内容:论文提出了一种名为 ConceptAttention 的新方法,用于解释多模态扩散变换器(DiTs)的丰富表示,并生成高质量的显著性图,以精确定位图像中的文本概念。该方法无需额外训练,通过重新利用 DiT 注意力层的参数来产生上下文化的概念嵌入,并发现在线性投影到注意力输出空间时,可以生成比常用交叉注意力机制更清晰的显著性图。ConceptAttention 在零样本图像分割基准测试中达到了最先进的性能,超越了基于 CLIP、DINO 和 UNet 的多种零样本可解释性方法。该研究首次证明了多模态 DiT 模型(如 Flux)的表示可以高度迁移到视觉任务(如分割)中,甚至优于多模态基础模型 CLIP。
多token注意力
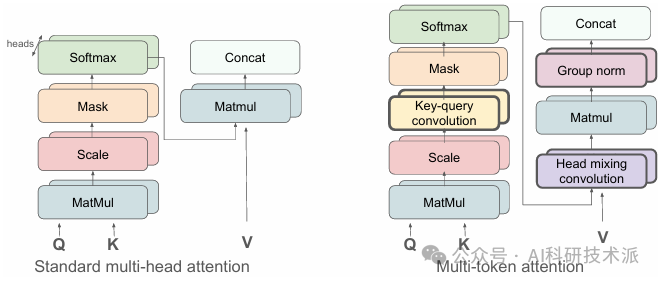
Multi-Token Attention
内容:论文提出了一种名为MTA的新注意力机制,旨在解决传统注意力机制中仅依赖单个查询(query)和键(key)向量相似度来确定相关性的局限性。MTA 通过在查询、键和注意力头之间应用卷积操作,允许模型同时基于多个查询和键向量来调整注意力权重,从而能够利用更丰富的信息来定位上下文中的相关部分。实验表明,MTA 在多种基准测试中表现出色,尤其是在需要在长上下文中搜索信息的任务中,其利用更丰富信息的能力显得尤为有益。
免费获取全部论文合集及项目代码

分层多头注意力
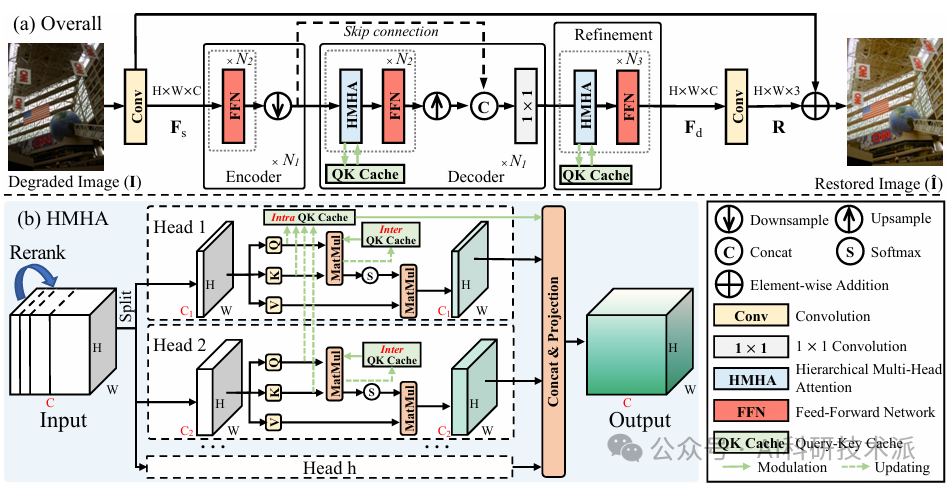
Devil is in the Uniformity: Exploring Diverse Learners within Transformer for Image Restoration
内容:论文出了一种名为 HINT的新型图像恢复模型。该模型通过引入层次化多头注意力(HMHA)和查询-键缓存更新(QKCU)机制,解决了传统多头注意力(MHA)中存在的冗余问题,能够学习到更具多样性的上下文特征,并增强不同注意力头之间的交互。HINT 在包括低光照增强、去雾、除雪、去噪和去雨等 5 种典型图像恢复任务的 12 个基准数据集上进行了广泛的实验,表现出优于现有先进算法的恢复图像质量和模型复杂度。
频域注意力
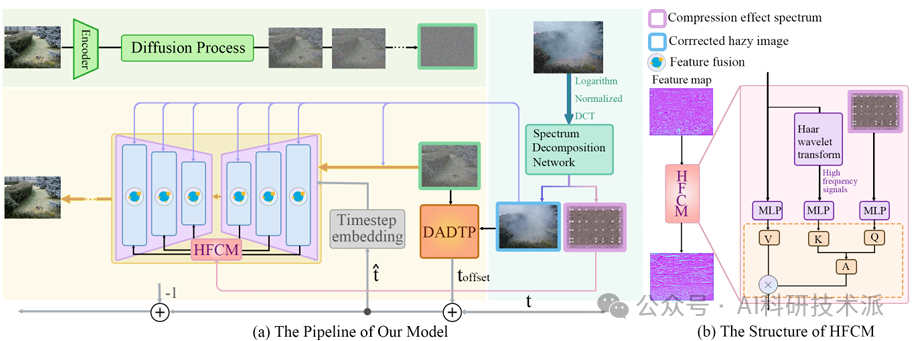
FDG-Diff: Frequency-Domain-Guided Diffusion Framework for Compressed Hazy Image Restoration
内容:论文提出了一种名为 FDG-Diff 的新型去雾框架,专门针对压缩后的雾霾图像恢复问题。该框架通过频域引导的扩散模型,结合高频补偿模块(HFCM)和降噪时间步预测器(DADTP),有效解决了雾霾退化与 JPEG 压缩之间的复杂联合损失问题。FDG-Diff 首先通过频谱分解网络分离压缩效应和无损信息,然后利用这些信息指导扩散模型采样,显著提升了压缩雾霾图像的恢复质量。实验结果表明,该方法在多个压缩去雾数据集上优于最新的去雾方法。
卷积注意力
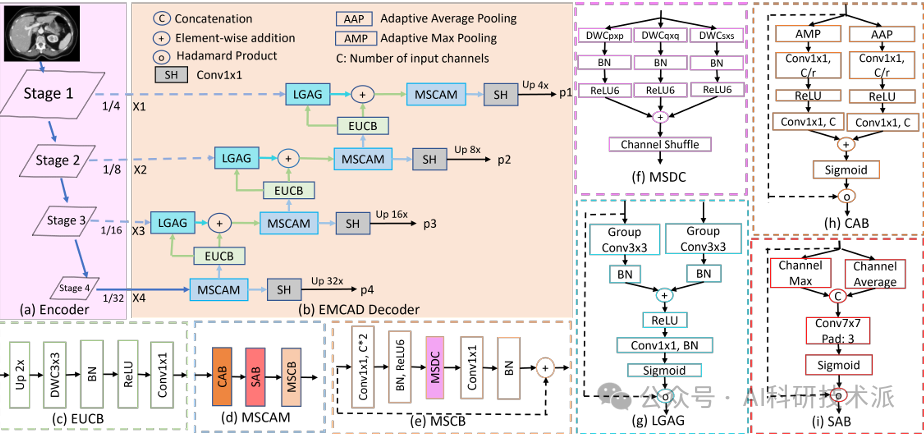
EMCAD:Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation
内容:论文提出了一种名为EMCAD的高效多尺度卷积注意力解码器,用于医学图像分割任务。EMCAD通过独特的多尺度深度可分离卷积块显著增强特征图,并结合通道、空间和分组(大核)门控注意力机制,有效捕捉复杂的空间关系,同时聚焦于显著区域。该解码器在保持高性能的同时,计算效率极高,例如在标准编码器下仅需1.91M参数和0.381G FLOPs。通过在12个数据集上的严格评估,EMCAD在多个医学图像分割任务中达到了最先进的性能,同时在参数数量和计算量上分别减少了79.4%和80.3%。此外,EMCAD的适应性使其能够与不同的编码器结合,并在多种分割任务中表现出色,为医学图像分析领域提供了一种更高效、更准确的工具。
免费获取全部论文合集及项目代码


















 2139
2139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









