







2025年还能靠改注意力机制发论文吗?姚期智大佬团队给出了答案,他们提出了一种新型注意力机制TPA,节省了90%内存占用但不降性能,一统了现代注意力设计!
可以看出,现在简单的改层数对于注意力机制来说已经不算创新了,我们需要思考更多...这里就建议大家考虑多头注意力机制、注意力机制融合、层次注意力机制、跳过连接和注意力门控、自适应注意力权重等思路,上述姚院士团队的方法就属于多头注意力机制的改进,同时也与自适应注意力权重相关。
如果大家感兴趣,可以看看最新的前沿成果找找灵感,我这边也已经帮同学们整理好了40个注意力机制创新方案,不想多花时间找资料的可以直接拿,也欢迎大家分享本文给好友同学~
全部论文+开源代码需要的同学看文末
Tensor Product Attention is All You Need
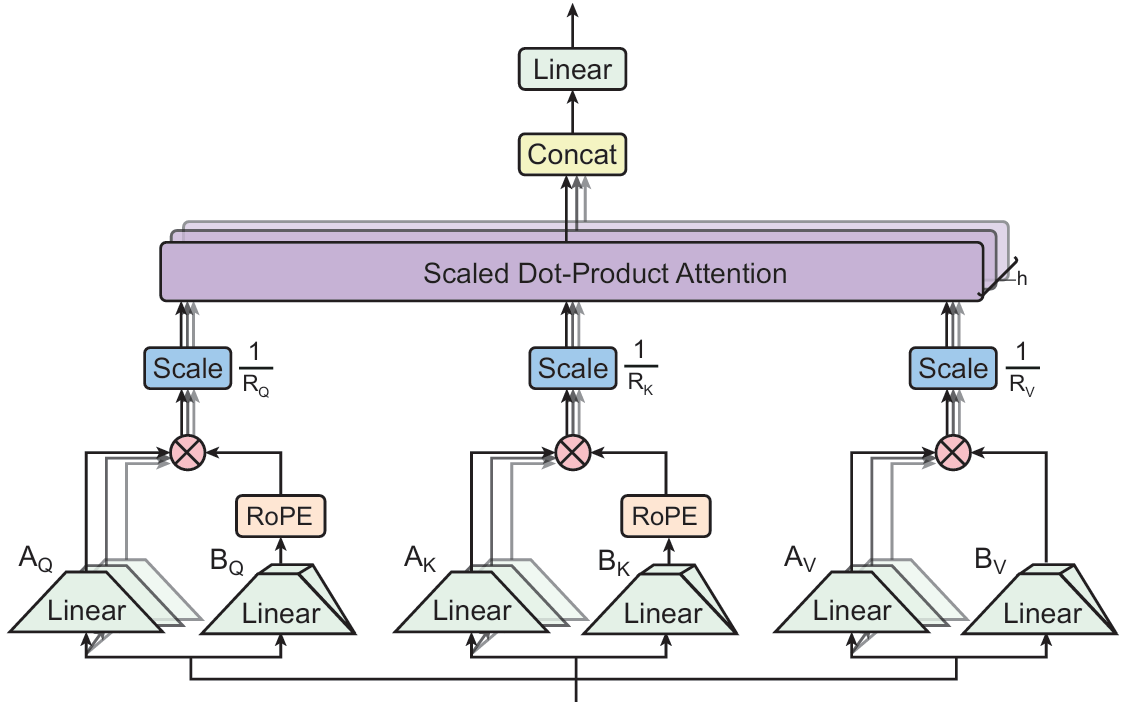
方法:论文提出了一种新的注意力机制——张量乘积注意力(TPA),通过对查询、键和值进行低秩张量分解,显著减少推理时的KV缓存大小,并提高模型质量,提出的Tensor ProducT ATTenTion Transformer (T6) 架构在多个语言建模任务中超越了传统Transformer基线(如MHA, MQA, GQA等)。
创新
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









