






本文来自公众号“AI大道理”
——————
论文原文:
http://yann.lecun.com/exdb/publis/pdf/chopra-05.pdf
很多园区楼下都有人脸识别的机器,然后智能的为你开门。
实现这样的功能需要将你本人的一张图片输入到系统中,接下来就可以识别出你是不是在系统中,若是则给你开门。
那么这究竟是如何实现的呢?为什么只需要输入一张图片就够?
Siamese Network给你答案。
Siamese Network是一种学习图片相似度的网络,可应用于人脸识别、签名验证。

1、摘要
我们提出了一种从数据中训练相似性度量的方法。该方法可以用于识别或验证应用,其中类别的数量非常大,在训练期间是未知的,并且其中单个类别的训练样 本的数量非常小。其思想是学习将输入模式映射到目标空间的函数,使得目标空间中的范数接近输入空间中的“语义”距离。该方法应用于人脸验证任务。
学习过程最小化区分损失函数,该函数使得相似性度量对于来自同一个人的多对人脸较小,而对于来自不同个人的多对人脸较大。从原始空间到目标空间的映射是卷积网络,其架构被设计为对几何失真具有鲁棒性。该系统在 Purdue/AR 人脸数据库上进行测试,该数据库在姿势、光 照、表情、位置以及诸如墨镜和遮挡围巾之类的人工遮挡方面具有非常高的可变性。
(AI大道理:Siamese Network是在提取输入图片的特征,然后对特征进行对比,得到两个类似图片的特征对比结果很近,不一样的两张图片特征对比结果很远。)

2、介绍
使用判别方法进行分类的传统方法,例如神经网络或支持向量机,通常要求预先知道所有类别。他们还要求提供所有类别的训练样本。此外,这些方法本质上局限于相当小数量的类别(大约 100 个)。这些方法不适用于类别数量非常大、每个类别的样本数量很小以及在训练时仅知道类别子集的应用。这种应用包括面部识别和面部验证。这些应用种类的数量可以是数百或数千。解决这类问题的常用方法是基于距离的方法,该方法包括计算要分类或验证的模式与存储的原型库之间的相似性度量。另一种常见的方法是在降维空间中使用非判别(生成)概率方法,其中可以在不使用来自其他类别的样本的情况下训练一个类别的模型。为了将判别学习技术应用到这类应用中,我们必须设计一种方法,能够从可用数据中提取关于问题的信息,而不需要关于类别的特定信息。
(AI大道理:类似的问题不是靠分类模型来做的。对公司的人员进行采集人脸数据集是非常困难的,且公司人员变动频繁,每变动一次就要重新训练一次模型,显然是不现实的。)
本文提出的解决方案是从数据中学习相似性度量。该相似性度量稍后可以用于比较或匹配来自先前未见过的类别的新样本。我们提出了一种新的用于训练相似性度量的判别训练方法。该方法可以应用于分类问题,其中类别的数量非常大和/或在训练时来自所有类别的样本都不可用。
主要思想是找到一个将输入模式映射到目标空间的函数,使得目标空间中的简单距离(比如欧几里德距离)近似于输入空间中的“语义”距离。更准确地说,给定由参数化的一族函数Gw(X),我们寻求找到一个参数值W,使得相似性度量如果X1和X2属于同一类别,则为小;如果它们属于不同类别,则为大。
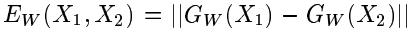
该系统在取自训练集的成对模式上被训练。通过训练最小化的损失函数Ew(X1,X2),在X1和X2来自相同类别时最小化Ew(X1,X2),而在它们属于不同类别时最大化。除了关于w的可微性之外,没有对Gw的性质做出任何假设。因为具有相同参数的相同函数被用于处理这两者输入,相似性度量是对称的。这被称为连体结构。
(AI大道理:两个一模一样的网络对图像进行特征提取,保证提出出来的特征具有可比性。)
为了用这种方法建立人脸验证系统,我们首先训练模型以产生输出向量,这些输出向量对于来自同一个人的成对图像是邻近的,而对于来自不同个人的成对图像是远离的。该模型然后可以被用作在训练期间没有看到的新人的面部图像之间的相似性度量。
所提出的方法的一个重要方面是,我们在选择Gw(X)时具有完全的自由度。特别是,我们将使用被设计用来提取对输入的几何失真具有鲁棒性的表示的架构,例如卷积网络。所得的相似性度量对于图像对之间的小的姿态差异将是鲁棒的。
由于目标空间的维数很低,并且该空间中的自然距离对于输入的不相关变形是不变的,所以我们可以很易地从非常少量的样本中估计每个新类别的概率模型。
1.1. 以前的工作
在比较之前将人脸图像映射到低维目标空间的想法有很长的历史,始于基于PCA 的特征脸方法,其中 G(X)是一种线性投影,非歧视性地训练以最大化方差。基 LDA 的 Fisherface 方法也是线性的,但是被有区别地训练,以便最大化类间和类内方差的比率。已经讨论了基于核PCA和核LDA的非线性扩展。对用于人脸识别的子空间方法的综述。所有这些方法的一个主要缺点是它们对输入图像的几何变换(移 位、缩放、旋转)和其他可变性(面部表情、眼镜和模 糊围巾的变化)非常敏感。一些作者已经描述了对于一组已知的变换是局部不变的相似性度量。一个例子是切线距离法。另一个已经应用于人脸识别的例子是弹性匹配。其他人提倡基于变形的标准化算法,以最大限度地减少由于姿态的外观变化。所有这些模型的不变性都是预先手工设计的。在本文描述的方法中,不变性属性不是来自关于任务的先验知识,而是从数据中学习的。当使用卷积网络作为映射函数时,所提出的方法可以学习数据中存在的大范围的不变性。
我们的方法有点类似于[4]的方法,它使用一个连体结构进行签名验证。他们的方法和我们的方法之间的主要区别是通过训练过程使损失函数最小化的本质。我们的损失函数是从基于能量的模型(EBM)的判别学习框架中导出的。
我们的方法与其他降维技术非常不同,如多维标度 (MDS) 和局部线性嵌入(LLE)。MDS根据已知的成对相异度,从训练集中的每个输入对象计算目标向量,而无需构建映射。相比之下,我们的方法产生一个非线性映射,可以将任何输入向量映射到其相应的低维版本。
(AI大道理:以前的方法是基于人工的方法,Siamese Network则是从数据中学习的特征。)

3、总体框架
概率模型将标准化概率分配给建模变量的每个可能配置,而基于能量的模型(EBM)将非标准化能量分配给这些配置。在这种系统中,预测是通过搜索使能量最小的变量的配置来进行的。EBM 用于必须比较各种配置的能量以做出决定(分类、验证等)的情况。可训练的相似性度量可以被视为将能量Ew(X1,X2)与输入模式对相关联。在最简单的人脸验证设置中,我们简单地设置X2所要求身份的所有可用图像,并比较最小值Ew(X1,X2)达到预定的阈值。
EBMs 优于传统概率模型,特别是生成模型的优点是不需要估计输入空间上的归一化概率分布。标准化的缺失使我们免于计算可能难以处理的配分函数。这也让我们在选择模型的架构时有了相当大的自由度。
通过在训练集上评估,找到W使适当设计的损失函数最小化的来执行学习。乍一看,我们可能认为简单地最小化Ew(X1,X2)一组输入对的平均值同样的类别就足够了。但是这通常会导致灾难性的崩溃:通过简单地构造一个常数函数Gw(X1),能量和损失可以变为零。因此,我们的损失函数需要一个对比项,以确保不仅来自相同类别的一对输入的能量低,而且来自不同类别的一对输入的能量大。这个问题不会出现在适当标准化的概率模型中,因为使特定对的概率高会自动地使其他对的概率低。
(AI大道理:不仅要使得相似的距离近,还要使得不相似的距离远,双管齐下。)
2.1 利用学习的相似性度量进行人脸验证
人脸验证的任务是接受或拒绝图像中主体的身份。使用两种方法进行评估:错误接受的百分比和错误拒绝的百分比。一个好的系统应该同时最小化这两种措施。
我们的方法是建立一个可训练的系统,该系统将人脸的原始图像非线性地映射到低维空间中的点,使得如果图像属于同一个人,则这些点之间的距离很小, 否则这些点之间的距离很大。学习相似性度量是通过训练一个网络来实现的,该网络由两个相同的卷积网络组成,这两个网络共享相同的一组权重,即一个连体结构。
2.2 EBM 的能量函数
图 1 给出了我们学习机的架构。Gw(X)的架构详情见第 3.2 节
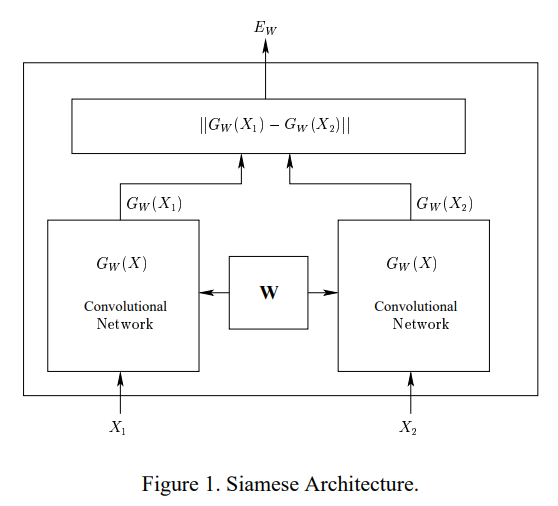
设x1和x2是显示给我们的学习机器的一对图像。设Y是该对的二进制标签,如果X1和x2属于同一个人则Y=0(一双真品),如果X1和x2不属于同一个人则Y=1(一对冒名顶替者)。设W为需要学习的共享参数向量,设Gw(X1)和Gw(X2)是通过映射X1和x2生成的低维空间中的两个点。那么我们的系统可以看作是一个标量“能量函数”Ew(X1,X2)用于测量x1、X2之间的兼容性。它被定义为:
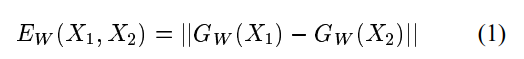
给定来自训练集(X1,X2)的真实对和来自训练集(X1,X2")的冒名顶替者对,如果以下条件成立,则机器以期望的方式运行:
条件1:
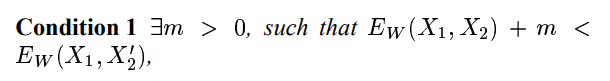
正数可以解释为边距。
为了简化记法,本文的其余部分将Ew(X1,X2)记为
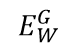
,Ew(X1,X2")记为
。
2.3 用于训练的对比损失函数
我们假设损失函数只通过能量间接地依赖于输入和参数。我们的损失函数的形式是:
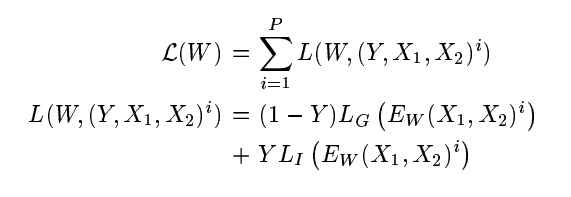
其中(Y,X1,X2)i是第i个样本,它由一对图像和一个标签(真品或冒名顶替者)组成,LG是真实对的部分损失函数,LI是冒名顶替者对的部分损失函数,P是训练样本的数量。LG和LI并且应该以这样的方式设计,使得的最小化L将降低真实对的能量,并增加冒名顶替者对的能量。实现这一点的简单方法是使得LG单调递增和LI单调递减。然而,有一组更一般的条件,在这些条件下,最小化L将使机器接近条件1。我们的论点类似于 LeCun 等人给出的论点。我们将考虑由一个真实对组成的训练集(X1,X2) 和一个带能量的冒名顶替者
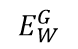
。让我们来定义:
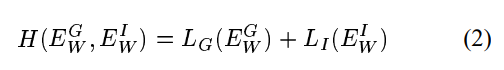
作为两对的总损失函数。我们将假设它的两个自变量H都是凸的(注意:我们不假设W是凸的)。我们还假设存在单个训练样本的一个W,从而满足条件 1。对于
和的所有值,损失函数H必须满足以下条件。
(AI大道理:损失函数由两部分组成,一部分是一对相似的图片,另外一部分是一对不相似的图片。)
条件 2 :H的最小值应该在这个式子的半平面内
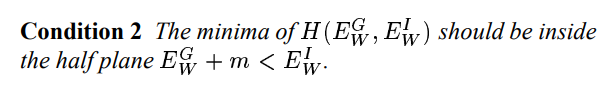
这个条件清楚地保证了当我们最小化H时关于w,机器被驱动到一个区域
该解满足条件1。对于最小值位于无穷远处的(见图 2),以下条件就足够了。
条件 3 :边缘线
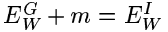
上的H梯度的负值具有方向为[-1,1]的正点积
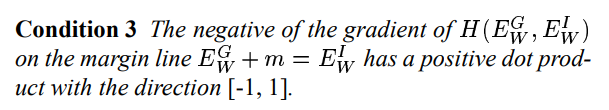
为了证明这一点,我们陈述并证明以下定理。
定理1:设
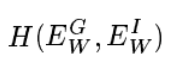
在和中是凸的,并且在无穷大处具有极小值。假设一个采样点存在W,从而满足条件1。如果条件3成立,则使H相对于W最小化将导致找到满足条件1的W。
证明:考虑由
和形成的平面的正象限(见图3)。设两个半平面和分别由HP1和HP2表示。对于W在其域中的所有值,我们在和上最小化H。设R是由和形成的平面内的区域,和对应于W域中的所有值。在最一般的设置中,R可以是非凸的,并且可以位于平面中的任何位置。然而,通过我们的假设,即至少存在一个W,从而满足条件1,我们可以得出结论,R的一部分与半平面HP1相交。为了根据条件3证明定理,我们需要证明在R和HP1的交点上至少存在一个点,使得该点的损失H小于R和HP2的交点上所有点的损失。
设
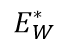
为边界线上的点,其最小值为H。就是这样
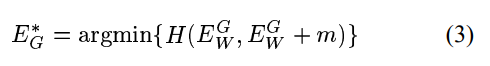
由于在边界线上所有点上H的梯度的负值都在半平面HP1内的方向上(条件3),通过H的凸性,我们可以得出当
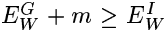
时:
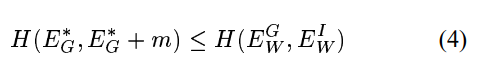
现在考虑一个距离
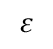
处的点,该点位于半平面HP1内。这就是点:
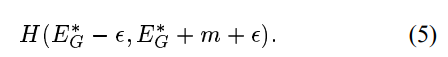
使用一阶泰勒展开,我们可以写出上面的作为:
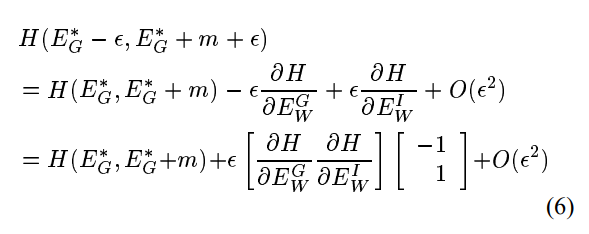
根据条件3,方程6右侧的第二项为负。因此,对于足够小的
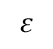
,
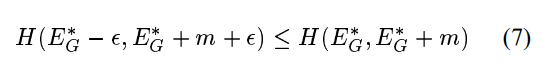
因此,在区域R和半平面HP1的相交处存在损耗函数小于R和HP2的相交处的任何点的点。接下来是这一说法。
注意,当L0是单调递增函数,而L1是单调递减函数时,条件3显然适用于任何H。
我们对单个样本使用的确切损失函数是:
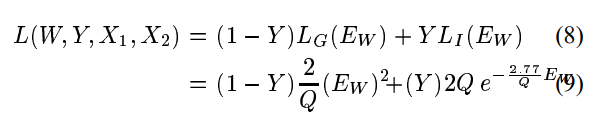
其中
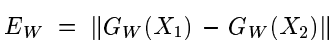
。在我们的体系结构中,Gw的组件是有界的,因此Ew也是有界的。常数Q设置为Ew的上界。
可以清楚地看到,上述损失函数在
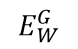
中单调递增,在中则单调递减,并且它相对于和都是凸的。因此,通过上述论点,我们得出结论,最小化该损失函数将使机器达到W,在那里它将以所需的方式表现。
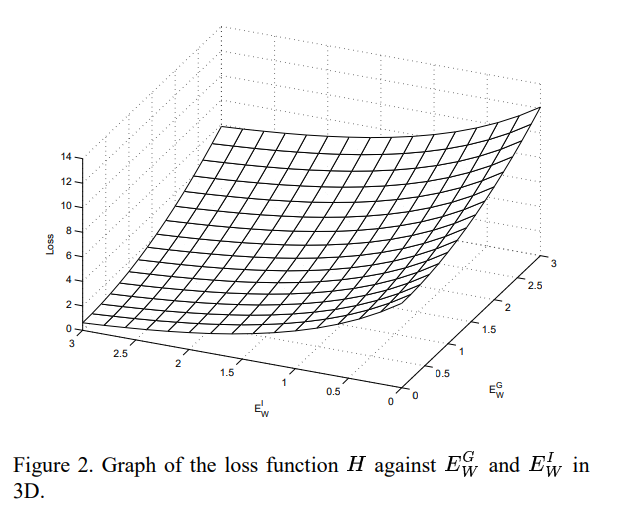
关于我们的损失函数,我们再谈两点。首先,解释了损失函数中的常数。我们用来最小化损失函数的优化算法是基于梯度的。选择这些常数是为了确保边缘线上的损失函数的梯度的负方向总是指向区域R内部。这是为了避免我们的算法被困在梯度指向R外部的边界上的一点上的情况。在这种情况下,基于梯度的算法可以将该点识别为损失函数的局部最小值并终止。
其次,我们必须强调,使用平方范数而不是能量的L1范数是不合适的。事实上,如果能量是二者之差的平方范数,则能量相对于参数的梯度将随着能量接近零而消失。这将在损失函数中产生一个危险的平台。这可能导致机器在两个图像是冒名顶替并且相应能量接近零的情况下无法学习。
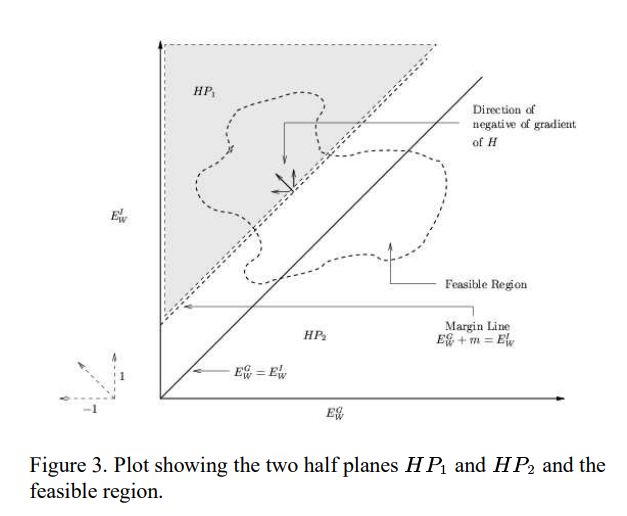
图3显示两个半平面HP1的图和 HP2和可行区域
2.4.卷积网络
为了将原始图像映射到低维空间中的点,从而实现学习的相似性度量,我们使用两个具有公共参数向量的相同进化网络(见图1)。卷积网络是可训练的多层非线性系统,可以在像素级操作,并以集成的方式学习低级特征和高级表示。卷积网络是端到端训练的,用于将像素图像映射到输出。他们的主要优势是可以学习最优移位不变局部特征检测器,并构建对输入图像的几何失真鲁棒的表示。我们使用的网络的确切规格在第3.2节中给出。

4、实验
上一节中描述的模型和架构在3个人脸图像数据库上进行了训练,并在其中2个数据库上进行测试。我们将详细讨论数据库,然后解释训练协议和架构。
3.1数据集和数据处理
第一轮训练和测试是用美国电话电报公司人脸数据库中的400张相对较小的图像数据集完成的。该数据集包含40名受试者的10张图像,每个受试者在光线、面部表情、配饰和头部位置方面都有所不同。每个图像都是112x92像素,灰度级,并经过紧密裁剪,仅包括面部。见图4。



图4。顶部:来自AT&T数据集的图像。中间:来自AR数据集的图像。底部:来自FERET数据集的图像。每张图片都显示了一对真品、一对冒名顶替者和一个典型主题的图像。
没有必要对图像进行尺寸或照明标准化的预处理,因为其中一个既定目标是训练一种能够适应这种变化的架构。然而,我们确实使用4x4子采样将图像的分辨率降低到56x46。
第二组训练和测试实验是通过结合两个数据集进行的:普渡大学创建的人脸AR数据库和灰度Feret数据库的子集。来自这两个数据集的Im-age对被用于训练,但只有来自AR数据集的图像被用于测试。
AR数据集包括136个受试者的3536张图像,每个受试者有26张图像。一个受试者的每个26个图像集由相隔14天拍摄的2组13个图像组成。在每组13幅图像中,有4幅图像具有表情变化,3幅图像具有照明变化,3张图像具有深色太阳镜和照明变化,以及3张图像带有遮脸围巾和照明变化。由于单个受试者的图像之间的外观差异很大,因此该数据集极具挑战性。示例如图4所示。由于人脸在图像中没有很好地居中,因此应用了一种简单的基于相关性的居中算法。然后对图像进行裁剪,并将其缩小到56x46像素。尽管定中心足以用于裁剪,但在许多图像中,头部位置仍然存在显著变化。
Feret数据库由美国国家标准与技术研究所分发,包括从1209名受试者中收集的14051张图像。我们只使用了完整数据库的一个子集进行训练。我们的子集由1122个图像组成,即187个受试者中的每个受试者有6个图像。唯一的预处理是裁剪和二次采样到56x46像素。
划分为了生成由机器在训练过程中看不到的受试者图像组成的测试集,我们将数据集划分为两个离散集,即SET1和SET2。这些集合中的每个图像都与该集合中的其他图像配对,以生成最大数量的真实对和即时对。
对于AT&T数据,SET1由前35名受试者的350张图像组成,SET2由后5名受试人的50张图像组成。通过这种方式,从SET1生成了总共3500个正版和119000个冒名顶替对,从SET2生成了500个正版和2000个冒名顶替对。仅使用SET1生成的图像对进行训练。使用来自SET2的图像对和来自SET1的未使用的图像对进行测试(验证)。
对于AR/Feret数据,SET1包含AR数据库中96名受试者的所有Feret图像和2496张图像。SET2包含AR数据库内其余40名受试人的1040张图像。拍摄2张图像的所有组合,得到71628对真品和11096376对真品。实际使用的训练集包含140000个图像对,这些图像对在真实和冒名顶替之间平均分配。测试集是从SET2中的1081600对中提取的。因此,只有在训练中没有看到的受试者才被用于测试。
3.2 训练协议和体系结构
孪生架构。孪生架构包括两个相同的网络和一个成本模块。系统的输入是一对图像和一个标签。图像通过子网络,产生两个输出,这两个输出被传递到产生标量能量的成本模块,如第2.3节所述。损失函数将标签与能量结合在一起。损失函数相对于控制两个子网的参数向量的梯度是使用反向传播来计算的。使用两个子网贡献的梯度之和,使用随机梯度方法更新参数向量。
第一组实验使用小型AT&T数据集,探索了6种不同的子网架构:一个2层全连接神经网络和五个不同层数、大小和卷积核大小的卷积网络。基于这些实验,第二组实验集中在单个卷积网络架构上。我们仅在以下部分中描述性能最佳的体系结构。Cx表示卷积层,Sx表示子采样层,Fx表示全连接层,其中x是层索引。基本架构为C1-S2-C3-S4-C5-F6。
-
C1:卷积层,15个7×7卷积核,输出15个大小为50×40特征图
-
S2:池化层,输出15个大小为25×20特征图
-
C3:卷积层,45个6×6卷积核,输出45个大小为20×15特征图
-
S4:池化层,输出45个大小为5×5特征图
-
C5:卷积层,255个5×5卷积核,输出250个大小为1×1特征图
-
F6:全连接层,50个神经元
训练协议训练需要两组数据:训练集,用于实际学习系统的权重,验证集,用于在训练期间测试系统的性能。通过验证集定期进行性能评估,我们可以控制拟合。
训练网络是用从SET1拍摄的成对图像完成的。一半的图像对是真实的,一半是冒名顶替者,通过随机配对不同受试者的图像产生。验证集由1500个图像对组成,这些图像对取自SET1的未使用对,并且与训练集具有相同的50%真实、50%冒名顶替比率。
网络的性能是通过计算接受的冒名顶替对的百分比(FA)和拒绝的真实对的百分比来衡量的。这一计算是通过测量一对输出之间的差的范数,然后选取阈值来进行的其设置FA和FR百分比之间的给定折衷。
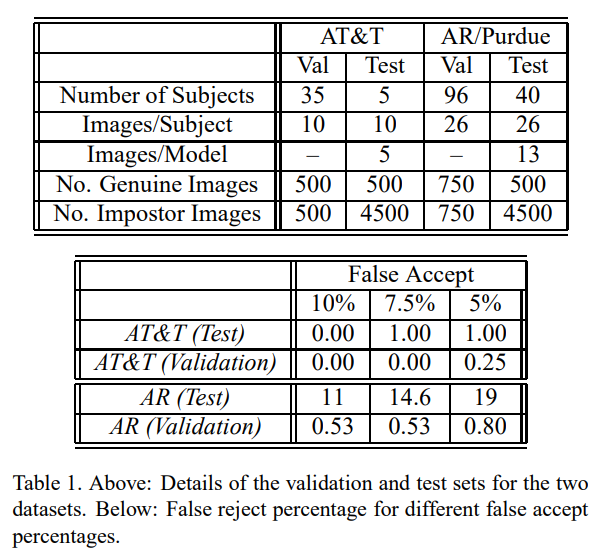
表1。上图:两个数据集的验证和测试集的详细信息。以下:不同错误接受百分比的错误拒绝百分比。

图5。一个特殊例子的卷积网络的内部状态。

5、测试和结果
图5显示了特定测试图像的卷积网络的内部状态。第一层提取各种类型的局部梯度特征以及平滑特征。
该系统针对人脸验证场景进行了测试。系统收到一张图像,并被要求确认该图像中受试者的身份。我们通过将测试图像与高斯图像进行比较来进行验证所要求保护的主题的图像模型。下面将讨论该方法。
4.1验证
测试(验证)是在一个尺寸为5000的测试集上进行的。它由500对真品和4500对冒名顶替者组成。对于AT&T实验,测试图像来自训练中看不到的5个子对象。对于AR/Feret实验,测试图像来自难度更大的AR数据库中的40个看不见的受试者。
孪生网络的其中一个子网的输出是受试者输入图像的特征向量。我们假设每个受试者图像的特征矢量形成多元正态密度。通过使用从每个受试者的前五个图像生成的特征向量来计算平均特征向量和方差-协方差矩阵,来构建每个受试物的模型。
通过评估测试图像在相关受试者模型上的正常密度,可以确定测试图像是真图像的可能性。测试图像是冒名顶替者的可能性,Pimpostor,被假设为一个常数,其值是通过计算相关P真实对象的所有冒名顶替图像的平均值来估计的。给定图像是真实图像的概率由下式给出:
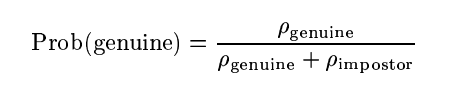
对于阈值概率的所有可能值,绘制被错误拒绝的图像和被错误接受的图像的百分比的值。最佳阈值概率是将测试集划分为真实和冒名顶替对并最小化FA和FR率的值。
通过测试AT&T数据库和AR/Purdue数据库获得的验证率显著不同(见表1和图6和图7),突显了这两个数据库在难度上的差异。AT&T数据集相对较小,我们的系统只需要5000个训练样本就可以在测试集上获得非常高的性能。AR/Purdue数据集非常庞大且多样化,在表达、照明和添加遮挡方面存在巨大差异。我们较高的错误率反映了这种难度。

6、结论与展望
我们提出了一种学习复杂相似性度量的通用判别方法。该方法最适合分类或验证场景,其中类的数量非常大,或在训练时所有类的示例都不可用。我们用一个人脸验证应用程序来说明该方法。
我们提出了一个损失函数,并证明最小化该函数会使系统接近期望的行为。我们的损失函数是有区别的,因为它驱动系统做出正确的决策,但不会导致系统产生概率估计。该方法与概率密度模型的不同之处在于,没有试图估计输入空间中每个类别的密度。这为我们在选择Gw(x)时提供了额外的灵活性,因为我们确实需要担心规范化。我们选择使用卷积网络架构,该架构对输入的几何变化表现出鲁棒性,从而减少了对人脸图像精确配准的需求。
可训练相似性度量在本文所述的度量之外还有许多应用。除其他外,它们可用于构建不变核函数,用于构建支持向量机和其他基于核的模型[17]。
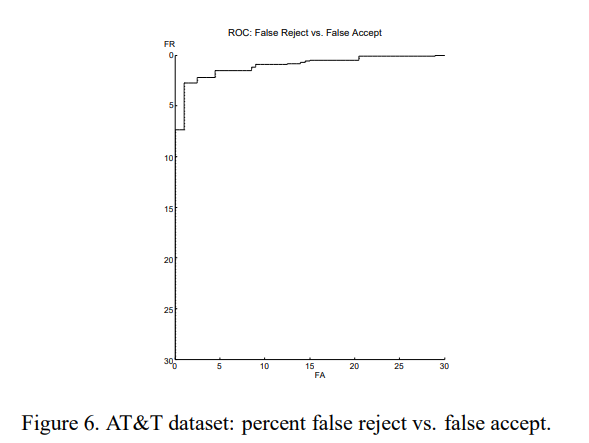
图6。AT&T数据集:错误拒绝与错误接受的百分比。
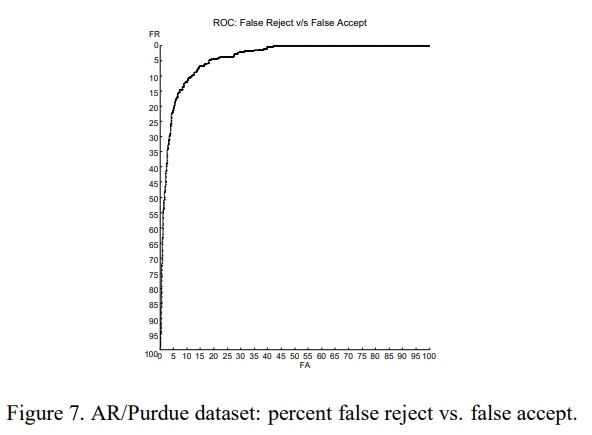
图7。AR/Purdue数据集:错误拒绝与错误接受的百分比。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————















 4385
4385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









