







循环序列模型
1. 为什么选择序列模型

有些问题,输入数据 X 和 输出数据 Y 都是序列,但有时也会不一样长,比如语音识别问题。
还有另一些问题,只有 X 或 只有 Y 是序列,比如音乐生成等。
2. 数学符号


3. 循环Recurrent 神经网络模型
为什么不使用标准神经网络去学习上面的 X 到 Y 的映射?


循环神经网络的前向传播:

一般化后的公式:
a
<
t
>
=
g
1
(
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
+
b
a
)
y
^
<
t
>
=
g
2
(
W
y
a
a
<
t
>
+
b
y
)
\begin{aligned} a^{<t>}&=g_{1}\left(W_{a a} a^{<t-1>}+W_{a x} x^{<t>}+b_{a}\right) \\ \hat{y}^{<t>}&=g_{2}\left(W_{y a} a^{<t>}+b_{y}\right) \end{aligned}
a<t>y^<t>=g1(Waaa<t−1>+Waxx<t>+ba)=g2(Wyaa<t>+by)
对上述公式进行形式上的化简:

4. 通过时间的反向传播
编程框架通常会自动实现反向传播,但还是要了解下它的运作机制

每个阶段的损失和整体损失的定义如下:
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
=
−
y
<
t
>
log
y
^
<
t
>
−
(
1
−
y
<
t
>
)
log
(
1
−
y
^
<
t
>
)
L
(
y
^
,
y
)
=
∑
t
=
1
T
x
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
\begin{aligned} L^{<t>}\left(\hat{y}^{<t>}, y^{<t>}\right)&=-y^{< t>} \log \hat{y}^{<t>}-\left(1-y^{<t>}\right) \log \left(1-\hat{y}^{<t>}\right) \\ L(\hat{y}, y)&=\sum_{t=1}^{T_{x}} L^{<t>}\left(\hat{y}^{<t>}, y^{<t>}\right) \end{aligned}
L<t>(y^<t>,y<t>)L(y^,y)=−y<t>logy^<t>−(1−y<t>)log(1−y^<t>)=t=1∑TxL<t>(y^<t>,y<t>)
然后需要最小化损失,通过梯度下降来更新参数
5. 不同类型的循环神经网络

6. 语言模型和序列生成
语言模型所做的就是,它会告诉你某个特定的句子它出现的概率是多少
得到一个句子后:
- 建立一个字典,将每个单词转成
one-hot编码 - 定义句子的结尾,增加一个额外的标记 EOS(
结尾识别符) - 还有不存在的词都归为
unknow UNK

7. 对新序列采样
训练一个序列模型之后,要想了解到这个模型学到了什么,一种非正式的方法就是进行一次新序列采样

以上是基于词汇的RNN模型,还可以基于字符
基于字符的优缺点:
- 优点:不必担心会出现未知的标识
- 缺点:1. 会得到太多太长的序列,大多数英语句子只有10到20个的单词,但却可能包含很多很多字符。2. 基于字符的模型在捕捉句子中的依赖关系不如基于词汇的语言模型那样可以捕捉长范围的关系,并且基于字符的模型训练成本较高。
自然语言处理的趋势就是,绝大多数都是使用基于词汇的语言模型,但随着计算机性能越来越高,会有更多的应用。在一些特殊情况下,会开始使用基于字符的模型。除了一些比较专门需要处理大量未知的文本或未知词汇的应用,还有一些要面对很多专有词汇的应用。
8. 循环神经网络的梯度消失

反向传播的时候,随着层数的增多,梯度不仅可能指数下降,也可能指数上升。
- 梯度爆炸,你会看到很多NaN,数值溢出。解决方法就是用梯度修剪。如果它大于某个阈值,缩放梯度向量,保证它不会太大,这是相对比较鲁棒的
- 然而梯度消失更难解决
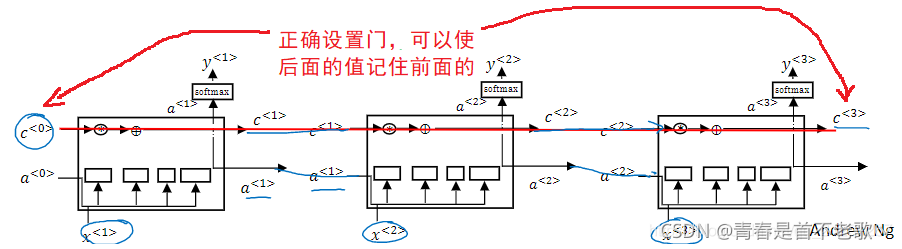
9. Gated Recurrent Unit(GRU单元)
门控循环单元 GRU,它改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题
普通的RNN单元结构如下:

简化版的GRU单元如下所示:

候
选
值
:
c
~
<
t
>
=
tanh
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
控
制
门
:
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
更
新
值
(
是
否
更
新
取
决
于
Γ
u
)
:
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
\begin{aligned} 候选值:\tilde{c}^{<t>}&=\tanh \left(W_{c}\left[c^{<t-1>}, x^{<t>}\right]+b_{c}\right) \\ 控制门:\Gamma_{u}&=\sigma\left(W_{u}\left[c^{<t-1>}, x^{<t>}\right]+b_{u}\right) \\\\ 更新值(是否更新取决于\Gamma_{u}):c^{<t>}&=\Gamma_{u} * \tilde{c}^{<t>}+\left(1-\Gamma_{u}\right) * c^{<t-1>} \end{aligned}
候选值:c~<t>控制门:Γu更新值(是否更新取决于Γu):c<t>=tanh(Wc[c<t−1>,x<t>]+bc)=σ(Wu[c<t−1>,x<t>]+bu)=Γu∗c~<t>+(1−Γu)∗c<t−1>
GRU单元的优点就是通过门决定是否更新记忆细胞
- 当你从左到右扫描一个句子的时候,是否需要更新某个记忆细胞取决于 Γ u \Gamma_{u} Γu值( Γ u \Gamma_{u} Γu=1更新, Γ u \Gamma_{u} Γu=0不更新)
- 由于sigmoid函数的缘故,门很容易取到0值,或者说非常接近0。这非常有利于维持细胞的值。因为只会接近0,所以不会出现梯度消失的问题。这就是缓解梯度消失问题的关键,因此允许神经网络运行在非常庞大的依赖词上,比如说cat和was单词即使被中间的很多单词分割开
如果门是多维的向量,元素对应的乘积做的就是告诉GRU单元哪个记忆细胞的向量维度在每个时间步要做更新,所以你可以选择保存一些比特不变,而去更新其他的比特。比如说你可能需要一个比特来记忆猫是单数还是复数,其他比特来理解你正在谈论食物,你可以每个时间点只改变一些比特
FULL GRU(完整的GRU单元)

上式中,
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
\Gamma_{r}=\sigma\left(W_{r}\left[c^{<t-1>}, x^{<t>}\right]+b_{r}\right)
Γr=σ(Wr[c<t−1>,x<t>]+br),我们可以将
Γ
r
\Gamma_{r}
Γr理解为
c
~
<
t
>
,
c
<
t
−
1
>
\tilde c^{<t>}, c^{<t-1>}
c~<t>,c<t−1> 有多大的相关性
研究表明:1. GRU单元尝试让神经网络有更深层的连接,去尝试产生更大范围的影响,还有解决梯度消失的问题,而且非常健壮和实用的。2. GRU结构可以更好捕捉非常长范围的依赖,让RNN更加有效。
10. 长短期记忆网络LSTM(long short term memory)unit

候
选
值
:
c
~
<
t
>
=
tanh
(
W
c
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
更
新
门
(
u
p
d
a
t
e
)
:
Γ
u
=
σ
(
W
u
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
遗
忘
门
(
f
o
r
g
e
t
)
:
Γ
f
=
σ
(
W
f
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
f
)
输
出
门
(
o
u
t
p
u
t
)
:
Γ
o
=
σ
(
W
o
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
o
)
细
胞
(
c
e
l
l
)
:
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
Γ
f
∗
c
<
t
−
1
>
激
活
值
(
a
c
t
i
v
e
)
:
a
<
t
>
=
Γ
o
∗
tanh
c
<
t
>
\begin{aligned} 候选值:\tilde{c}^{<t>}&=\tanh \left(W_{c}\left[c^{<t-1>}, x^{<t>}\right]+b_{c}\right) \\ 更新门(update):\Gamma_{u}&=\sigma\left(W_{u}\left[a^{<t-1>}, x^{<t>}\right]+b_{u}\right) \\ 遗忘门(forget):\Gamma_{f}&=\sigma\left(W_{f}\left[a^{<t-1>}, x^{<t>}\right]+b_{f}\right) \\ 输出门(output):\Gamma_{o}&=\sigma\left(W_{o}\left[a^{<t-1>}, x^{<t>}\right]+b_{o}\right) \\ 细胞(cell):c^{<t>}&=\Gamma_{u} * \tilde{c}^{<t>}+\Gamma_{f} * c^{<t-1>} \\ 激活值(active):a^{<t>}&=\Gamma_{o} * \tanh c^{<t>} \end{aligned}
候选值:c~<t>更新门(update):Γu遗忘门(forget):Γf输出门(output):Γo细胞(cell):c<t>激活值(active):a<t>=tanh(Wc[c<t−1>,x<t>]+bc)=σ(Wu[a<t−1>,x<t>]+bu)=σ(Wf[a<t−1>,x<t>]+bf)=σ(Wo[a<t−1>,x<t>]+bo)=Γu∗c~<t>+Γf∗c<t−1>=Γo∗tanhc<t>
用GRU?用LSTM?
- GRU 更加简单,更容易创建一个更大的网络,它只有两个门,在计算性上也运行得更快
- 但 LSTM 更加强大和灵活,因为它有三个门。大部分人会把 LSTM 作为默认的选择来尝试
无论是GRU还是LSTM,都可以用它们来构建捕获更加深层连接的神经网络
11. 双向循环神经网络(Bidirectional RNN)
BRNN 模型可以让你在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息

上面的基本单元不仅可以是标准RNN单元,也可以是 GRU 或 LSTM 单元。
NLP(自然语言处理)问题,常用 LSTM单元的双向RNN模型。
双向RNN网络模型的缺点:你需要完整的数据的序列,你才能预测任意位置。比如构建一个语音识别系统,需要等待这个人说完,获取整个语音表达才能处理这段语音,并进一步做语音识别。
emmm,实际的语音识别通常会有更加复杂的模块…
12. 深层循环神经网络(Deep RNNs)















 5582
5582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









