







1. Introduction
1.1 传统方式
一般来说,推荐系统可以分成两类:
- 协同过滤
协同过滤主要关注用户的历史行为表现,比如用户的点击、购买等行为。主要的设想是具有相似历史行为的用户倾向于表现出相似的未来行为。
- 矩阵分解模型(Matrix Factorization Model),
- 利用多层神经感知器来替换矩阵分解中的内积,
- 考虑附加信息,例如在顺序推荐[10,115](Sequential recommendation)中的行为时间戳,社会推荐[14,99](Social Recommendation)中的用户社交网络,多行为推荐[18,101](Multi-behavior recommendation)中的多类型行为等等。
- 基于内容的推荐(也被称为点击通过率 click-through rate, CTR)
主要集中于利用用户和物品的丰富属性和特点,或者的内容的上下环境来强化推荐效果。
主流的CTR推荐系统致力习得一种高维的特征表示,例如分解机中的线性内积,DeepFM中的多层感知机,AFM中的注意力网络,AutoInt中的堆叠自注意层。
❓FM
❓DeepFM
❓AFM
❓AutoInt
1.2 基于因果联系
如今的推荐系统的基本思想是对“关联”进行建模,例如协同过滤中的行为联系(behavior correlation),或者是CTR中的特性-特性(feature-feature)、特性-行为(feature-behavior)联系。
然而,现实世界是由因果关系推动的,而不是所谓的联系,联系并不意味着存在因果关系。
推荐系统中的两种主要因果关系:
- 用户方面(user-aspect)
用户的决策行为是由因果关系推动的。
购买手机 → 购买充电器 购买手机\to 购买充电器 购买手机→购买充电器 - 交互方面(interaction-aspect)
系统的推荐策略很大程度上会影响用户的用户和系统的交互行为。
don’t like → no interaction \text{don't like}\to \text{no interaction} don’t like→no interaction
non-exposure → no interaction \text{non-exposure}\to\text{no interaction} non-exposure→no interaction
“因果”分为“因”(cause)和“果”(effect),cause对effect负部分的责任(这里不太懂)[111]。
因果推理是通过试验数据或者观察数据来进行决策以及深入利用因果联系的过程[111]。
- potential outcome framework(Rubin Causal Model)[64]
致力于计算确定的treatment的效果
- structural causal model(SCM)[57,59]
构建因果图和对应的结构方程,因果图中有一系列的变量和结构方程来描述变量之间的关系。
1.3 现有的推荐系统的问题
-
数据偏差
例如一致性偏差(conformity bias),流行偏差(popularity bias)等[45]。主流偏差,来自WSDM2022 Fighting Mainstream Bias in Recommender Systems via Local
What is conformity bias?
Conformity bias is when our deep-seated need to belong causes us to adapt our behaviours to feel like part of the group. Rather than using personal and ethical judgment, people imitate the behaviour of others in a bid to toe the party line. This type of behaviour may be unintentional but can have a powerful impact on our ability to make unbiased decisions.
What Is Conformity Bias and How Does It Affect Recruitment? -
数据缺失和数据噪声
受限于数据收集过程,收集的数据可能丢失或者有噪声。
- 例如用户只对一小部分商品产生了互动,那么大部分用户-商品的反馈信息无法被收集到。
- 或者用户进行了点击行为之后,获得的是对目标商品的厌恶情绪,这种数据会成为整体数据的噪声。

-
超越准确性的目标难以实现
推荐系统需要考虑的目标:
- 准确性
- 公平性
- 可解释性
- 透明性
- ……
这些非准确性的目标可能会影响推荐的精确性。
基于用户行为的多驱动因素(multiple driven causes under user behavior)模型是基于为每个因素分配解离化的(disentangled)并且可解释的嵌入量这种思想去构建的。
这样可以提供既精确又可解释的推荐。
另一个例子是多样化(diversity)。高度多样化的物品推荐列表与高度同质化的列表相比并不一定适合用户的兴趣,因为高度同质化的列表的因果关系可以帮助我们捕捉为什么用户会倾向于消费特定类别的项目,最终可以获得理想的精确度和多样化。
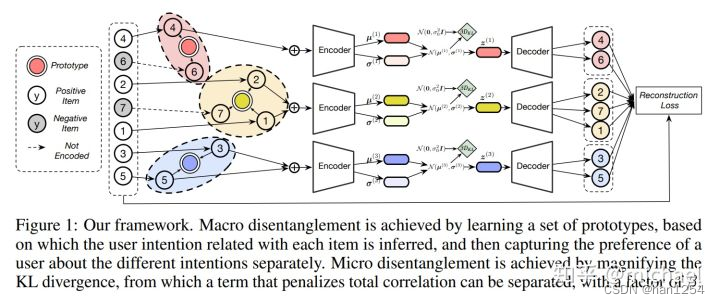
1.4 基于因果推理的方法
Recent research on recommender systems tackles these challenges with carefully-designed causality-driven methods. There has been a burst of relevant papers in the last two years, and there is a very high probability that causal inference will sweep the field of recommender systems. In this survey paper, we systematically review these early research efforts, especially on how they address the critical shortcomings with causal inference.
1.4.1 Why & How
- 首先,使用因果推理的推荐方法可以构建因果图,通过这种方法,在大部分情况下造成偏差的因素都可以视作因果图中的混杂因素(confounder),而消除混杂因素影响的方法在因果论中是很成熟的。
- 对于数据缺失的情况,因果增强模型(causality-enhanced models)可以帮助我们构建一个反事实(counterfactual)的世界,因此缺失的数据可以通过反事实解释(counterfactual reasoning)来进行收集。
- 因果推理可以很自然地帮助我们构建可解释的以及可控的模型,这样无论是对于模型本身的可解释性以及对于推荐结果的可解释性都是可以达成的。
- 由于模型是可控的,所以如多样性、公平性等这些目标都是可以达成的。
1.4.2 基于因果推理的方法分类
-
数据去偏
对于流行偏差或者曝光偏差,可以将它们视为混杂因素(为什么可以视为混杂因素?是否有论文支撑?),使用后门调整来解决。
对于一致性偏差,可以视为一种冲突效应(collider effect) -
数据增强以及数据去噪
双重数据缺失问题包括- 有限的用户数据收集
反事实推理(counterfactual reasoning)可以生成未收集的数据,对数据进行加强,从而解决数据丢失的问题。 - 推荐模型中因果效应的缺失
利用IPW模型可以评估推荐系统中的因果效应。
- 有限的用户数据收集
-
实现可解释性、多样性和公平性
基于可解释的模型,可以通过控制模型避免折中权衡来实现高度多样性。通过控制模型针对特定用户群体的公平来实现公平推荐。
2. 研究背景
2.1 因果推理
Structural Causal Models, SCM_Jude Pearl[59]
SCM将变量之间的因果关系抽象出来,构建结构方程,然后通过因果推理来估计交互或者反事实的效果[59]。
-
因果模型
- 因果图(Causal graphs)
利用有向无环图DAG来描述因果关系,节点代表变量,边指代因果关系。
- 结构方程(Structural functions)
In general form, a functional causual model consists of a set of equation of the form:
x i = f i ( p a i , u i ) , i = 1 , ⋯ , n x_i=f_i(pa_i, u_i), i=1,\cdots, n xi=fi(pai,ui),i=1,⋯,n
where p a i pa_i pai stands for the set of variables that directly determine the value of X i X_i Xi and where the U i U_i Ui reprensent errors(or “disturbances”) due to omitted factors.
<Causality 2nd edition> p27
- 因果图(Causal graphs)

-
三种典型的DAGs
在图三中有三种经典的结构:链形、叉形、和冲突形- 链形:如图三(a),用户特点影响用户的偏好,用户的偏好又会影响用户的点击行为;
- 叉形:如图三(b),商品的质量会影响商品的价格和用户的喜好;
如果我们单纯地忽略Z的影响,则会在X和Y之间创造出一种原本无关的联系,电商平台会误以为是高价格导致的用户偏好,但是很显然这种关系是错误的。
- 冲突形:如图三©:用户的偏好和商品的流行程度会共同影响用户的点击概率。
Conditioning on 𝑍 will lead to correct correlation between 𝑋 and 𝑍. That is,users’ behaviors on two items with the same popularity level are only affected by their preferences.
-
反事实?
反事实推理衡量再treatment变量与现实中的treatment不一致的时候情况会变成什么样子。
Potential outcome framework_Rubin[64]
ITE: Individual Treatment Effect
ATE:Average Treatment Effect
A E T = E i [ Y 1 i − Y 0 i ] = 1 N ∑ i = 1 N ( Y 1 i − Y 0 i ) AET = \mathbb{E}_i[Y_1^i-Y_0^i]=\frac{1}{N}\sum\limits_{i=1}^N(Y_1^i-Y_0^i) AET=Ei[Y1i−Y0i]=N1i=1∑N(Y1i−Y0i)
隐输出框架既不考虑描述因果关系的因果图也不对因果效应提出解释。
衡量因果效应,挖掘因果关系
通过设置随机试验来衡量因果效应。随机地将测试者分成Treatment组和受控组,就可以消除未观察到的混杂因素。
随机测试保证了协变量平衡以及交换性。可以通过比较两个分组直接获得因果效应。
例如A/B测试。
然而直接上线模型对用户进行分组测试可能会影响企业利润,所以使用现有的观测到的数据来衡量因果效应是很重要的。一般情况下,可以使用SCM来将因果衡量转换成统计测量。通过可观测数据和可识别因果机制来计算直接因果效应。
一个经典的方法是后门调整(backdoor adjustment):
P ( y ∣ d o ( t ) ) = ∑ P ( y ∣ t , w ) P ( w ) P(y|do(t))=\sum P(y|t,w)P(w) P(y∣do(t))=∑P(y∣t,w)P(w)
backdoor criterition
A set of variables W W W satisfies the backdoor criterition relative to T T T and Y Y Y if the following are true:
- W W W blocks all the backdoor path from T to Y
- W does not contain any descendants of T
<Introduction to Causual Inference from a Machine Learning Perspective>p37
后门路径的调整方法强调那些可观测的混杂变量,但是当混杂变量不可观测的时候,前门调整方法(Frontdoor adjustment)就显得尤为重要。
前门法则:
- 从T到Y的所有直接因果路径都通过M
- 从T到M以及从M到Y不存在后门路径
这就可以说节点集合M符合前门法则,可以使用前门调整方法。
对于所有的 m ∈ M m\in M m∈M,
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ m , t ′ ) P ( t ′ ) P(y|do(t))=\sum\limits_m P(m|t)\sum\limits_{t'}P(y|m,t')P(t') P(y∣do(t))=m∑P(m∣t)t′∑P(y∣m,t′)P(t′)
由于同时设定
W
W
W内的所有元素是不太现实的,我们可以使用如下的倾向分数(propensity score)
e
(
W
)
=
P
(
T
=
1
∣
W
)
e(W)=P(T=1|W)
e(W)=P(T=1∣W)
这个分数指示的是当任意给定一组 W W W之后受到treatment的概率。通过IPW(inverse propensity weighting)我们可以计算新的因果效应
τ ^ = 1 n 1 ∑ i : t i = 1 y i e ( w i ) − 1 n 2 ∑ j : t j = 0 y i e ( w j ) \hat\tau =\frac{1}{n_1}\sum\limits_{i:t_i=1}\frac{y_i}{e(w_i)}-\frac{1}{n_2}\sum\limits_{j:t_j=0}\frac{y_i}{e(w_j)} τ^=n11i:ti=1∑e(wi)yi−n21j:tj=0∑e(wj)yi
识别因果模型的方法[22]
- 传统的识别因果关系的方法是进行条件独立性测试,并且附带如可信度等其他额外的假设[79]
- 基于评分的算法[28,73]可以用来松弛严格的因果发现和挖掘,评分算法可以通过与可观测数据之间的比较来衡量已发现的因果图的质量,
- 最近机器学习方法[125],使用强化学习来获得最优的DAG
2.2 推荐系统
history interactions->future interactions
input: Y ∈ R ∣ U ∣ × ∣ I ∣ Y\in \mathbb{R}^{|\mathcal{U}|\times |\mathcal{I}|} Y∈R∣U∣×∣I∣
output: f ( ⋅ , ⋅ ) , ( u , i ) → f R f(\cdot,\cdot),(u,i)\stackrel{f}\to \mathbb{R} f(⋅,⋅),(u,i)→fR
- 协同过滤CF
只考虑用户-物品交互数据
通过附加数据强化行为数据:- 社交网络——社会化推荐[15,100]
- 行为序列数据——序列推荐[7,126]
- 多行为推荐[35,119]
- 跨域推荐[17,31]
- 点击通过率CTR
输入:精确的物品和用户特征
例如用户画像,商品特点。
主流方法是集中于将高维的交叉特征映射到用户-物品交互数据,使用了多层感知机[20]、神经网络[20]、自注意层[77]等。
2.2.1 模型设计
CF
标准方式是用隐向量来表示用户和物品,或者说,嵌入向量
用户的隐向量矩阵为 P ∈ R d × ∣ U ∣ \mathbf{P}\in \mathbb{R}^{d\times |\mathcal{U}|} P∈Rd×∣U∣
物品的隐向量矩阵为 Q ∈ R d × ∣ I ∣ \mathbf{Q}\in \mathbb{R}^{d\times |\mathcal{I}|} Q∈Rd×∣I∣
使用某种函数来衡量 p u p_u pu和 q i q_i qi之间之间的相似度
- 基于矩阵分解
- 基于神经网络
- 基于图神经网络
常见的CF模型
MF[40]:
使用内积来计算相似度: s ( u , i ) = p u T q i s(u,i)=\text{p}_u^T\text{q}_i s(u,i)=puTqi
NCF[27]:

为了结合非线性建模能力,NCF生成一种相似函数,并且根据如下方式来引入多层感知机:
s
(
u
,
i
)
=
h
T
(
p
u
G
⊙
q
i
G
)
+
ϕ
(
[
p
u
M
,
q
i
M
]
)
s(u,i)=\text{h}^T(p_u^G\odot q_i^G)+\phi([\text{p}_u^M,\text{q}_i^M])
s(u,i)=hT(puG⊙qiG)+ϕ([puM,qiM])
整个系统分成了GMF、MLP和NeuMF三个部分。
其中 p u G p_u^G puG和 q i G q_i^G qiG代表着GMF初始阶段通过用户和物品id的独热码生成的embedding, p u M p_u^M puM和 q i M q_i^M qiM表示MLP模块中,用户和物品id的embedding
ϕ G M F = p u G ⊙ q i G ϕ M L P = a L ( W L T ( a L − 1 ( ⋯ a 2 ( W 2 T [ p u M q i M ] + b 2 ) ⋯ ) ) + b L ) \phi^{GMF}=\text{p}_u^G\odot q_i^G\\\phi^{MLP}=a_L(\text{W}_L^T(a_{L-1}(\cdots a_2(\text{W}_2^T\begin{bmatrix}p_u^M\\q_i^M\end{bmatrix}+b_2)\cdots))+b_L) ϕGMF=puG⊙qiGϕMLP=aL(WLT(aL−1(⋯a2(W2T[puMqiM]+b2)⋯))+bL)
NGCF[91]
Neural Graph Collaborative Filtering,神经图协同过滤。
这种推荐模型是基于图神经网络(Graph Neural Network, CNN)的一种模型。主要思想是认为在获取用户和物品的embedding的时候,不应该只考虑分离的特征,还应该将用户和商品的交互考虑进去。

为了完成这个目标,文中使用了一种embedding传递层,第 l l l层的用户和商品的embedding传递函数如下:
p u l = Agg ( q i l − 1 ∣ i ∈ N u ) q i l = Agg ( p u l − 1 ∣ u ∈ N i ) \text{p}_u^l=\text{Agg}(\text{q}_i^{l-1}|i\in \mathcal{N}_u)\\\text{q}_i^l=\text{Agg}(\text{p}_u^{l-1}|u\in \mathcal{N}_i) pul=Agg(qil−1∣i∈Nu)qil=Agg(pul−1∣u∈Ni)
这里 Agg ( ⋅ ) \text{Agg}(\cdot) Agg(⋅)是收集节点相邻信息的聚合函数。
s ( u , i ) = ( [ p u 0 , ⋯ , p u L ] ) T [ q i 0 , ⋯ , q i L ) s(u,i)=([p_u^0,\cdots,p_u^L])^T[q_i^0,\cdots, q_i^L) s(u,i)=([pu0,⋯,puL])T[qi0,⋯,qiL)
E ( L ) = LeakyReLU ( ( L + I ) E ( l − 1 ) W 1 ( l ) + L E ( l − 1 ) ⊙ E ( l − 1 ) W 2 ( l ) ) \text{E}^{(L)}=\text{LeakyReLU}((\mathcal{L}+\text{I})\text{E}^{(l-1)}\text{W}_1^{(l)}+\mathcal{L}\text{E}^{(l-1)}\odot \text{E}^{(l-1)}\text{W}_2^{(l)}) E(L)=LeakyReLU((L+I)E(l−1)W1(l)+LE(l−1)⊙E(l−1)W2(l))
L = D − 1 2 A D − 1 2 \mathcal{L}=D^{-\frac{1}{2}}AD^{-\frac{1}{2}} L=D−21AD−21
A = [ 0 R R T 0 ] A=\begin{bmatrix}0&R\\R^T&0\end{bmatrix} A=[0RTR0]
其中, R ∈ R N × M \text{R} \in R^{N\times M} R∈RN×M是用户-商品交互矩阵,D是对角节点度数矩阵。
CTR
常见的CTR预测流程是将特征映射到用户-商品交互信息中。输入的特征信息为如下表示:
x u , i = [ x u , i 1 , ⋯ , x u , i M ] \text{x}_{u,i}=[\text{x}_{u,i}^1,\cdots,x_{u,i}^M] xu,i=[xu,i1,⋯,xu,iM]
M表示特征域的数量。此外,原始的特征数据可以通过一定方式转换成embedding:
v
u
,
i
k
=
V
k
x
u
,
i
k
,
k
=
1
,
⋯
,
M
\text{v}_{u,i}^k=\text{V}^k\text{x}_{u,i}^k,k=1,\cdots,M
vu,ik=Vkxu,ik,k=1,⋯,M
V k ∈ R d k × ∣ F k ∣ \text{V}^k\in \mathbb{R}^{d^k\times |\mathcal{F}^k|} Vk∈Rdk×∣Fk∣
用户和商品之间的相似性可以通过某种函数来进行计算:
s ( u , i ) = g ( [ v u , i 1 , ⋯ , v u , i M ] ) s(u,i)=g([v_{u,i}^1,\cdots, v_{u,i}^M]) s(u,i)=g([vu,i1,⋯,vu,iM])
相关的模型有
FM[62]、DeepFM[20]、AutoInt[77]
目标函数
point-wise
着重于预测用户-商品的交互,常用的是Logloss函数。
L = − 1 ∣ O ∣ ∑ ( u , i ) ∈ O y u , i log ( y ^ u , i ) + ( 1 − y u , i ) log ( 1 − y ^ u , i ) \mathcal{L}=-\frac{1}{|\mathcal{O}|}\sum\limits_{(u,i)\in \mathcal{O}}y_{u,i}\log (\hat y_{u,i})+(1-y_{u,i})\log(1-\hat y_{u,i}) L=−∣O∣1(u,i)∈O∑yu,ilog(y^u,i)+(1−yu,i)log(1−y^u,i)
pair-wise
BPR[63]损失函数
L = − 1 ∣ Q ∣ ∑ ( u , i , j ) ∈ Q log σ ( y ^ u , i − y ^ u , j ) \mathcal{L}=-\frac{1}{|\mathcal{Q}|}\sum\limits_{(u,i,j)\in \mathcal{Q}}\log \sigma (\hat y_{u,i}-\hat y_{u,j}) L=−∣Q∣1(u,i,j)∈Q∑logσ(y^u,i−y^u,j)
3 因果推断的必要性

3.1 数据偏差问题
- 交互数据偏差
- 流行度偏差[96,121](popularity bias)
- 一致性偏差(conformity bias)
- 曝光偏差(exposure bias)
流行度偏差:

- 属性偏差[88]
属性偏差可能误导对用户喜好的评估。对用户历史交互数据的训练可能会导致强调某些属性。例如视频推荐,用户可能会被有吸引力的标题抓住眼球并产生交互,但是视频内容很可能是不符合用户的喜好的。
因果推理用于除偏的必要性
因果理论让我们通过推荐数据的生成过程来找出数据偏差的根本原因,并且通过因果推荐建模来消除或者弱化这种影响。
推荐系统中主要的偏差效应出现在后门路径中,混杂因素的存在使得推荐分数比输入X原本可以造成的结果更高。例如由于用户的从众心理的存在,用户会无意识地趋向于与已经存在的流行商品进行交互,未排除这个混杂因素的系统会默认用户对流行商品的偏好,如果不排除商品流行程度的影响,则可能会使得流行商品被过度推荐。
利用因果推理去偏的关键是构建treatment和outcome之间的因果关系而不是相关性。
3.2 推荐系统中的数据缺失问题
由于用户-商品的反馈数据只记录了用户对一小部分的商品的交互数据,所以很难完整地表示出用户的真实喜好,所以最后获得的推荐一般情况下都是次优解。
Within the area of recommender systems, most existing studies assume that the observed rating data are missing-completely-atrandom (MCAR). Generally, this assumption does not hold because real-world recommender systems are subject to selection bias. Selection bias occurs primarily due to the following two reasons.
- First, the probability of observing each rating is highly dependent on a past recommendation policy. For example, if the observed rating dataset is collected under the most popular policy, a policy that always recommends some of the popular items to all users, the probability of observing ratings of such popular items may be
large. This leads to the non-uniform missing mechanism, and the MCAR assumption is violated.- Second, user self-selection happens, as users are free to choose the items that they wish to rate. For example, in a movie recommender system, users usually watch and rate movies that they like and rarely rate movies that they do not like. Another example is a song recommender system, in which users tend to rate songs that they like or dislike and seldom rate songs they feel neutral about. These findings suggest that most rating datasets collected through real-world recommender systems are missing-not-at-random (MNAR).
Asymmetric Tri-training for Debiasing Missing-Not-At-Random Explicit Feedback
由于系统原有的推荐策略、用户自身拒绝评分以及用户和商品的特征数据丢失等原因,对用户的喜好进行建模显得更加困难。
Steck[80]计算出了缺失评分的预测误差。Schnabel等人和Thomas等人[71,83]基于收集某个评分记录的概率来设置评分的权重。但是这些方法的准确性不高,而且泛化能力也比较差。
因果推论的方法可以提供对于数据是如何产生的因果解释,这些解释可以视作数据驱动的模型的前置知识。然后数据缺失的不良影响就可以被削弱。
3.3 数据噪声问题
在现实生活中收集到的用户历史数据可能是不正确的,或者说含有噪声的。
因果论工具提供了更加完整的以及可解释的建模方式,帮助我们能够检测噪声信息。更进一步来讲,可以使用反事实解释,通过设想不存在噪声的结果,来生成可信的标签。
3.4 超精度问题
可解释性
我们应该去理解为什么商品会被推荐到这个人眼前,而另一件商品则不会。这使得推荐更加透明也更加可信。
而可解释性又可以分成:模型可解释和结果可解释
- 模型可解释
- 结果可解释
目前主流的推荐方式主要集中在aspect感知可解释推荐,关于aspect的解释可以看该文章:《Aspect-Aware Latent Factor Model: Rating Prediction with Ratings and Reviews》阅读笔记
Aspect:在本文中aspect是一种高层次的语意表示,是用户在review中表达出的item属性,例如对于餐厅来说,食物和服务都可以当作aspect。
比如可以通过分解方法来习得用户在给定的不同的aspects上的喜好,从而让推荐模型得到aspect感知的解释。
但是传统的可解释方式缺点在于,这种解释还是建立在correlation上面的,单纯的联系无法确定某个因素是否是真正起作用的。故而习得的效果也有可能是虚假的。
此外,对于推荐模型的解释也需要构建不同部分和推荐结果之间精确的因果关系。推荐结果的解释应该充分考虑不同的决策因素或者说原因,如何导致我们的行为。
多样化推荐和信息茧房
信息茧房(Filter Bubble)是形容用户倾向于根据自己的线上个性与多元化内容隔离开的现象。在这种情况下,用户只能被置于一个信息内容和类别相对固定的环境中。
Passe等人[56]将这种现象归因于同质化(homogenization),这意味着用户的行为和兴趣最终会趋于统一。
Gabriel Mahcado Lunardi等人[50]从实际经验中分析了协同过滤方法下信息茧房的形成过程。人类的天性中就有追求舒适区以及与它们感兴趣的或者认同的观点或物品相处的特点,长此以往,这将会狭隘化用户的眼界,过度单一化用户的思想。所以需要打破信息茧房从而改进推荐的多样性。
偏差反馈循环(biased feedback loop)是造成信息茧房的最主要的原因之一。持续使用带有偏差的数据进行学习训练将会逐渐加重同质化现象。
当我们追求精确推荐的时候,多样化将会被削弱,这也是一个两难的抉择。
因果推荐提供了应对这样的挑战的机会。首先,因果论可以减弱偏差和数据缺失的影响。其次,使用了因果论的模型可以使用因果关系来理解用户对特定商品产生交互的原因,这也可以帮助模型在已经存在的类别之外推荐符合用户需求的商品。
公平性
从用户角度来看,公平性也就是说用户是因自己的性别、年龄等因素从而被不公平地对待。一些工作[24]试图利用基于联系的方法来解决不公平推荐问题。但是研究指出这些方法有一些严重缺点和欠考虑之处[39,41]。另外一些工作从因果的角度重新审视了这个问题,这可以让我们更好地理解随着输入变量的变化,输出是如何随着变化的[1,38]。
从商品角度来看,商品的公平性被定义为在推荐的过程中,每个商品是否被公平地对待。造成商品的不公平推荐的原因可能包括偏差,以及特定商品或者特性的缺失。一些工作[19,72]实现了非偏学习(unbiased learning)或者启发式排序调整(heuristic ranking adjustment)
解除偏差问题类似于回答在反事实的世界中,如果用户不属于某个特定的类别或者一个商品没有某种特定的属性,那么推荐结果还会保持相同吗?又或者说,推荐会变成什么样子呢?反事实的世界和真实世界之间的差异是推荐模型进行公平评估的关键。因此基于因果推理的方法,特别是反事实方法,可以从全新的角度提升推荐的公平性。

4 因果推荐的现有工作进展
4.1 解决数据偏差问题
偏差的产生大部分情况下是由于混杂因素的影响。为了减弱混杂因素的作用效果,这里主要有两种解决方式:
- Structure Causal Model, SCM
- Potential Outcome Framework, POF
4.1.1 如何去除混杂效应
SCM
使用SCM来进行消除混杂因素影响主要有两类,一个是后门调整,一个是前门调整。为了解决推荐系统中的数据偏差,现有的工作经常是对数据生成过程中的因果关系进行检查,识别出混杂因素,使用后门调整来通过介入的方法[59]阻断所有混杂因子产生的效应。
张等人的工作[121]将流行偏差归因于商品流行度产生的混杂影响,流行度同时影响了商品的曝光和可观察的交互情况。在训练过程中他们使用后门调整方法用来移除了混杂的流行度偏差,并且设计了一种推理机制来利用流行度偏差。
This work studies an unexplored problem in recommendation — how to leverage popularity bias to improve the recommendation accuracy.
The key lies in two aspects:
- how to remove the bad impact of popularity bias during training, and
- how to inject the desired popularity bias in the inference stage that generates top-𝐾 recommendations
Causal Intervention for Leveraging Popularity Bias in Recommendation
除此之外,王等人[87]发现了偏差放大问题(bias amplification issue),在用户的历史交互数据中的大部分商品类都会被过度推荐。例如,如果用户曾经和大量的动作电影产生过交互,那么推荐系统则会倾向于向他们推荐更多的动作电影。

在论文中,王等人发现了失衡的商品分布是真正的混杂因素。

然后作者还提出了一种帮助减弱偏差放大效应的近似后门调整方法。
然而,在实际中,混杂因素可能是很难被观测到的(比如用户在做出于商品的交互时的体温),此时前门调整策略则是一个默认的选项[59]。Xu等人[108]做出了一些试探性的工作来通过前门调整策略消除全局和个人混杂因素。Zhu等人[127]给出了应用前门调整的更加详细化的情景分析。
Potential Outcome Framework
从隐输出框架的角度来看,使用因果论来去偏的目的是构建一个无偏的学习目标。让 O \mathcal{O} O代表曝光操作,在其中 o u , i = 1 o_{u,i}=1 ou,i=1表示商品 i i i被推荐给了用户 u u u。根据IPW的定义[46](这里我推荐这篇博客Solving Simpson’s Paradox with Inverse Probability Weighting),我们可以通过最小化如下的目标函数来学习一个推荐器:
1 ∣ O ∣ ∑ ( u , i ) ∈ O o u , i l ( y u , i , y ^ u , i ) p ^ u , i \frac{1}{|\mathcal{O}|}\sum\limits_{(u,i)\in \mathcal{O}}\frac{o_{u,i}l(y_{u,i},\hat y_{u,i})}{\hat p_{u,i}} ∣O∣1(u,i)∈O∑p^u,iou,il(yu,i,y^u,i)
l ( ⋅ ) l(\cdot) l(⋅)表示推荐的损失函数, p ^ u , i \hat p_{u,i} p^u,i表示倾向概率(propensity),或者说 p ( y u , i ∣ d o ( ( u , i ) ) ) \text{p}(y_{u,i}|do((u,i))) p(yu,i∣do((u,i)))。作为最初的尝试,Tobias等人[72]使用这种目标函数去学习一种非偏矩阵分解模型,对倾向概率的估计使用了一种独立的逻辑回归模型(由于混杂因素可能不只有一种,一般情况下,结果y是离散的,所以这符合逻辑回归模型的目标)。
在这样的浅层模型的基础上[72],张等人将倾向模型和推荐模型的学习结合形成了一种多任务学习框架(multi-task learning framework)[118],这样的方法取得了比单独学习某个模型更好的效果。
Wang等人[94]迈出了处理序列推荐系统中的曝光偏差的关键第一步,他们提出了一种基于IPW的方法USR来消除序列行为中的混杂因素。
然而,评估正确的趋向分数是不太现实的,一般情况下可能会存在着高方差的问题。为了消除这个问题,一系列研究[23,66,92]通过使用误差插补模型(error imputation model)扩充上一个等式的方法来追寻一种双鲁棒的模型评估器,扩充后的等式如下:
1 ∣ U ∣ ⋅ ∣ I ∣ ∑ ( u , i ) ( e ^ u , i + o u , i ( l ( y u , i , y ^ u , i ) − e ^ u , i ) p ^ u , i ) \frac{1}{|\mathcal{U}|\cdot |\mathcal{I}|}\sum\limits_{(u,i)}(\hat e_{u,i}+\frac{o_{u,i}(l(y_{u,i},\hat y_{u,i})-\hat e_{u,i})}{\hat p_{u,i}}) ∣U∣⋅∣I∣1(u,i)∑(e^u,i+p^u,iou,i(l(yu,i,y^u,i)−e^u,i))
这里的讲述过于笼统,我们来看Enhanced Doubly Robust Learning for Debiasing Post-Click Conversion Rate Estimation这篇论文中的具体方法:
L D R ( R ^ ) = 1 D ∑ ( u , i ) ∈ D e ^ u , i + o u , i ( e u , i − e ^ u , i ) p ^ u , i \mathcal{L}_{DR}(\hat{R})=\frac{1}{\mathcal{D}}\sum\limits_{(u,i)\in \mathcal{D}}\hat e _{u,i}+\frac{o_{u,i}(e_{u,i}-\hat e_{u,i})}{\hat p_{u,i}} LDR(R^)=D1(u,i)∈D∑e^u,i+p^u,iou,i(eu,i−e^u,i)
o u , i o_{u,i} ou,i表示是否有交互,1为有交互,0为无交互。
当 e ^ u , i \hat e _{u,i} e^u,i预估正确的时候,目标函数可以近似看作 1 D ∑ ( u , i ) ∈ D e ^ u , i \frac{1}{\mathcal{D}}\sum\limits_{(u,i)\in \mathcal{D}}\hat e _{u,i} D1(u,i)∈D∑e^u,i
当 p ^ u , i \hat p_{u,i} p^u,i预估正确的时候, L D R ( R ^ ) = 1 D ∑ ( u , i ) ∈ D e ^ u , i + o u , i ( e u , i − e ^ u , i ) p ^ u , i = 1 D ∑ ( u , i ) ∈ D e ^ u , i + o u , i e u , i p ^ u , i − o u , i e ^ u , i p ^ u , i = 1 D ∑ ( u , i ) ∈ D e ^ u , i ( p ^ u , i − o u , i p ^ u , i ) + o u , i e u , i p ^ u , i \mathcal{L}_{DR}(\hat{R})=\frac{1}{\mathcal{D}}\sum\limits_{(u,i)\in \mathcal{D}}\hat e _{u,i}+\frac{o_{u,i}(e_{u,i}-\hat e_{u,i})}{\hat p_{u,i}}\\=\frac{1}{\mathcal{D}}\sum\limits_{(u,i)\in \mathcal{D}}\hat e _{u,i}+\frac{o_{u,i}e_{u,i}}{\hat p_{u,i}}-\frac{o_{u,i}\hat e_{u,i}}{\hat p _{u,i}}\\=\frac{1}{\mathcal{D}}\sum\limits_{(u,i)\in \mathcal{D}}\hat e _{u,i}(\frac{\hat p_{u,i}-o_{u,i}}{\hat p_{u,i}})+\frac{o_{u,i}e_{u,i}}{\hat p_{u,i}} LDR(R^)=D1(u,i)∈D∑e^u,i+p^u,iou,i(eu,i−e^u,i)=D1(u,i)∈D∑e^u,i+p^u,iou,ieu,i−p^u,iou,ie^u,i=D1(u,i)∈D∑e^u,i(p^u,ip^u,i−ou,i)+p^u,iou,ieu,i
p ^ u , i \hat p_{u,i} p^u,i和真实的 o u , i o_{u,i} ou,i相近,目标函数仍然适用。
如果你对双鲁棒性不太熟悉的话,可以查看该电子书来进行学习:
Causal Inference for the Brave and True
其中利用了真实案例来说明了双鲁棒性在实际应用中的效果是多么出色,任意一个预估函数出现问题,对整体结果的影响并不大。
其中, e ^ u , i \hat e_{u,i} e^u,i是误差插补模型的输出,该模型的输入是用户-商品特征。为了学习插值模型(imputation model)的参数,使用了一种联合学习框架[92]来优化:
1 O ∑ ( u , i ) ∈ O ( l ( y u , i , y ^ u , i ) − e ^ u , i ) 2 p ^ u , i \frac{1}{\mathcal{O}}\sum\limits_{(u,i)\in \mathcal{O}}\frac{(l(y_{u,i}, \hat y_{u,i})-\hat e_{u,i})^2}{\hat p_{u,i}} O1(u,i)∈O∑p^u,i(l(yu,i,y^u,i)−e^u,i)2
同时,一系列研究[8, 93]旨在探索数据集成的策略,因为RCT试验(randomized control trial)的试验数据十分费钱。
4.1.2 如何处理冲撞

另一个基于SCM技术的去重方法是“反事实推理”,它为去偏推荐消除了特定路径的因果效应。反事实推理可以评估特定路径的因果效应,并且消除部分用户/商品特征的因果效应。它可以设想一种没有沿着特定路径传输某些特征的反事实世界,并且通过比较事实和反事实世界之间的差异来衡量特定路径的因果效应。例如王等人的工作[88],就建立了一种反事实推理,来去除曝光特征的影响(例如具有吸引力的标题),以此来减弱一些钓鱼标题的问题。此外,Wei等人[96]减少了从商品节点到排序评分之间的直接因果效应,从而缓解了流行性偏差。Xu等人[107]提出了一种对抗组件(adversarial component)来捕捉反事实曝光机制并且在最坏情况下通过在两个模型之间的最小-最大博弈来优化候选模型。

4.2 解决数据缺失和噪声问题
用户的交互数据过少,或者数据收集时间过于紧凑以至于无法得到真正的回报。同时,很多对推荐造成影响的因素没有被记录。
解决的方法包括生成反事实数据来增加不充足的训练数据,或者生成反事实奖励来调整噪声数据。Uplift建模方法被用来衡量推荐的因果效应。
4.2.1 数据缺失问题
用户和商品之间的交互是事实数据,表示在推荐平台上真实发生的事件并且会直接影响用户的喜好。然而,事实数据经常是缺失的。最自然的想法是去生成更多的并未真实出现的数据来增加训练数据。这些强化的主要任务目标是回答在反事实世界中的问题:“如果……,那么将会发生……”,在计算机视觉[16]和自然语言处理领域[128]已经开始尝试使用这种方法。对于推荐系统来说,反事实数据增强的目标是期望在与现实不同的情况下生成新的数据。
现有的方法回答了以下几个方面的反事实问题:
- 协同过滤
用户被提供一组排好序的商品,他们将会与这些商品发生交互。数据增加(Data augmentation)可以用来生成未被看到的推荐列表的反馈,那么这个反事实问题就是:“如果推荐系统提供了另外的不同的推荐列表,给定用户的反馈会是什么样子?”[110]
- 序列化推荐
推荐系统根据历史交互的序列信息来对用户进行推荐。用户的交互数据被视作按照时间戳排序的序列。反事实问题是:“如果用户的历史交互序列数据不同,他们接下来又会如何表现?”[95,116]
- 基于特征推荐
除了交互数据外,用户画像和商品特征也被纳入考虑中。这种推荐模式下,数据强化的目标是回答:“如果给定用户的特征级别的偏好改变,那么他或者她的反馈又会发生怎样的变化?”[106]。Wang等人[90]深入考虑了分布外(out-of-distribution)推荐的问题,也就是说,the data in another distribution is missing.
作者提出使用一种变分自动编码机来习得用户在反事实分布下的表现。最近的工作[52]提出可以在商品与知识图谱的特定联系发生改变时使用反事实生成器来获得用户-商品交互数据。反事实生成器和推荐按器可以进行联合训练并且相互强化。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9k0jUOE5-1663200054765)(./FILES/causal-inference-in-recmmender-systems.md/97262b79.png)]
反事实数据强化基本遵循建模、介入和推断这三步,上图很好地解释了这个过程,接下来分别介绍这三步:
建模:
这一步通过捕获数据生成过程,这个模型既可以是推荐系统自身的,也可以是分离的模型。一帮情况下,这个模型是通过训练拟合事实数据获得的参数模型。给定特定在现实数据中存在的用于和商品,模型的作用类似于模拟器,模拟器通过可观测的交互数据训练获得并且可以生成未观测的数据。例如Yang等人[110]首次构建了一个结构化的因果模型来表达推荐的过程并且使用了用户和商品embeddings之间的内积实现了SCM。Xiong等人[106]使用了多层神经网络来提取用用户和商品的特征向量作为输入,然后使用了例如element-wise product或者注意力机制(attention)等合并操作来融合用户和商品的特征级别的特点。Zhang等人[116]以及Wang等人[95]提出了模型不可知论(model-agnostic)反事实数据强化,因此该模型可以作为拿来就可以用的(off-the-shelf)序列推荐模型。当模拟器训练结束后,对齐输入与事实相反的事例,然后观察记录模拟器的反事实结果输出。
介入:
将输入设置为与事实数据不同的值。这一步通过启发式的或者另一种基于学习的模型来产生反事实实例。
基于启发式的反事实介入一般是通过随机化来实现的,在[95]中,利用随机项目来替换掉一个随机索引中的某个项目可以生成一个反事实交互序列。在[116]中,
将可有可无和不可或缺的项替换为随机项,分别构建反事实的正序列和负序列。
相反,基于学习的的反事实介入旨在构建包含信息更加丰富的样例。其产生的样例对模型的优化有更多的重要性。例如,在[110]中,一个反事实推荐序列通过选择有更大损失值的商品来产生。在[95]和[106]中,在决策边界的商品和特征级别偏好被选择,然后通过微小调整来分别构造更加有效的反事实交互序列和输入特征。
推理:
推理阶段,通过上述的反事实输入和模拟器生成输出。在[110]中,反事实世界中介入的推荐序列通过构建的SCM的推理来获得其中可能被点击的商品。在[116]和[95]中,介入交互序列被送入序列主干模型,获得的输出最终成为反事实用户embeddings[116],或者它们被用来生成反事实的下一个商品。
4.2.2 数据噪声
推荐系统的交互中,由于数据收集的窗口过小,导致数据正确的变化情况没有被观察到。例如用户的反馈迟于用户和商品之间的交互。在现实生活中,用户将商品放入购物车之后,可能过了好几天才会购买。实时推荐算法中,当完整的reward被观察到之前,交互数据已经被用来构建了推荐结果,但是用户是否会购买并未可知。Zhang[120]尝试通过因果推理的方法解决这种延迟反馈问题。他们使用了重要性采样[4,113]来对原始reward数据进行重加权(re-weight)并且获得了在反事实世界中的调整的reward。
此外,噪声数据可以通过结合可靠反馈(比如ratings)来进行消除。然而可靠反馈往往更加稀疏,这导致了不充足的训练样例。为了解决这个问题,Wang等人提供了一种碰撞推理策略[86],利用预测可靠反馈的碰撞效应[59],方便用户提供稀疏可靠反馈。
4.2.3 因果效应评估
一些商品即使不被推荐出来,用户也会买;一些商品只有被推荐了才会被购买,用户看不到则不会被购买。那么这种商品的被购买概率是通过推荐系统进行提升的,这种效果被称为uplift。
近年来一些研究[68-70,105]尝试从uplift的角度探究推荐系统的因果效应。Sato等人[69]使用potential outcome framework来获得推荐系统的ATE。所有的交互根据treatment(推荐)和effect(反馈)分成了四类,然后使用ULO,一种取样方法,来习得每种取样的uplift。IPW方法被用来实现无偏离线学习[70]以及线上因果推荐评估[68]。Xie等人[105]提出通过将treatment视作额外的embedding,利用张量分解来评估uplift,并且他们使用回归不连续设计(regression discontinuity design,RDD)分析来模拟随机试验。Xiao等人[104]提出了一种双鲁棒评估器,并且提出了一个深度变分信息瓶颈(deep variational information bottlneck)方法来辅助调整因果预估。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bXijffVj-1663200054766)(./FILES/causal-inference-in-recmmender-systems.md/4607b1f2.png)]
4.3 超精度推荐系统
无因果的推荐系统可能会陷入一味地实现高精确度的深渊中,其他的重要目标则被忽略了,比如可解释性、公平性、多元性等。
4.3.1 可解释推荐系统
反事实学习
Tan等人[82]基于反事实解释提出了CountER可解释推荐模型,这个模型利用事实和反事实世界中的差异来解释模型推荐。他们提出了一个优化任务,目的是找到一个与原始项目距离最小的项目,以逆转反事实世界中的推荐结果。CountER也使用了因果发现技术来从历史交互和推荐的项目中提取因果关系,用以增强解释。
因果图导向表示学习
Zheng[123]等人提出,基于因果图来构建推荐模型。作者预先定义了表示用户行为(effect)如何从用户的两部分偏好(causes)——长期偏好和短期偏好中生成的这种因果关系。长期偏好指的是那些稳定的并且固有的兴趣喜好,而短期偏好指的是动态的并且暂时的喜好。作者对这两种方式的演进方式也做了定义。基于预定义的因果关系,作者提出将两种解纠纷(disentangled)embeddings分配给两部分的偏好。提取的自监督信号也使得推荐模型可解释性更强。Si等人[76]提出将模型参数分解成因果部分以及非因果部分,通过这种方式来强化推荐模型的可解释性。它通过使用用户的搜索特性作为指导变量(instrumental variable)来构建一个模型启发式框架(model-agnostic)。
因果发现
Xian等人[102]提出使用知识图谱来进行可解释推荐。事实上,知识图谱中的路径已经被广泛地用来生成解释。例如,用户购买AirPods可能是因为他或者她以前买过IPhone,而通过has_brand关系以及Apple Brand节点,AirPods和IPhone在知识图谱中都是可达的。基于知识图谱和用户的交互历史,作者提出要通过强化学习来提取因果关系。优化强化学习的策略函数来通过知识图谱的路径明确地选择商品,保证了精确性和可解释性。
Tran等人[84]研究了可解释的工作技能推荐问题。知道为了获得某项工作自己需要习得哪些技能是很重要的。作者提出了基于就业状况标签不同特征(different features with the employment-status label)的因果发现方法。然后提出了一种因果解释方法,这种方法找出了最重要的特征,这些特征的改动很可能使得用户获得职位。因此,这个特征就是关于就业的解释。
4.3.2 多样化和信息茧房
因果推论可以更好地对因果效应或者用户决策因子(user-decision factor)进行理解和建模。
反事实学习
Wang等人[89]提出了在用户控制的帮助下消除信息茧房的因果推荐框架。用户可以通过不同粒度的主动控制命令来寻找茧房外的内容。此外,作者提出了反事实学习方法来生成在反事实世界中新的用户embeddings,从而移除用户的过时特征的表示。通过构建反事实表示,推荐可以保持准确性和多样性、
后门调整
Wang等人[87]认为失衡的商品分布可以作为用户embeddings和预测得分之间的混杂因素,这将导致同质化的推荐。作者在训练数据中使用后门调整来阻挡失衡商品类别分布的影响,部分消除了信息茧房的效应。这个启发式模型可以被用于不同的推荐模型中,包括CF和CTR。
4.3.3 公平性
例如,为了判断在特定的用户画像下推荐系统是否公平,反事实的问题则是:如果用户画像发生改变,推荐结果是否会变化?Li等人[44]提出,反事实公平性即当调整给定的特征值时,推荐的可能性分布保持一致。作者提出了用户对公平推荐的需求,并且问题的关键是获得特征独立的用户embeddings。作者提出了一种过滤模块,该模块在embedding层之后,用以移除与敏感特征有关的信息,最终获得过滤的embeddings。作者然后提出了预测组件来预测敏感特征,使用了强化学习的方法以及主流的推荐损失函数。















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









