






Causal Inference in Recommender Systems: A Survey and Future Directions 推荐系统中的因果推理
读者总结:本文主要讲述了因果推理在推荐系统中的应用,对于推荐系统中的常见的问题比如说推荐中的偏差,推荐中的数据缺失和数据噪音,推荐中的公平性、可解性、透明性,如何利用因果推理进行解决。本文主要讲了因果推理在其中的作用,第二章主要介绍了什么是推荐和因果推理,第三章介绍了因果推理在推荐中的作用,最后第四章和第五章主要讲述了现有的工作和未来的一些工作。
链接: https://www.aminer.cn/pub/630c2e3090e50fcafdb6ced2?f=cs
1. Introduction
一般来说,推荐系统的目标是通过拟合历史行为,以及收集的用户配置文件、项目属性或其他上下文信息来学习用户偏好。在这里,交互主要是由之前的推荐系统引起的,很大程度上受推荐策略的影响。然后,推荐系统从候选项目池中筛选,并选择符合用户个性化偏好和需求的项目。一旦部署,系统就会收集新的交互来更新模型,这样整个框架就形成了一个反馈循环。
一般来说,推荐系统可以分为两类:
•协同过滤(CF) :协同过滤关注用户的历史行为协同过滤的基本假设是具有相似历史行为的用户倾向于具有相似的未来行为。例如,最具代表性的矩阵分解模型(MF)使用向量来表示用户和项目,然后使用内积来计算用户和项目之间的相关性分数。
•基于内容的推荐(又称点击率(CTR)预测,简称CTR预测) : CTR预测侧重于利用用户、项目或上下文的丰富属性和特征来增强推荐。主流的CTR预测任务是通过适当的特征交互模块来学习高阶特征,如Factorization Machine (FM)中的线性内积、DeepFM中的多层感知器、AFM中的注意网络、AutoInt中的堆叠自注意层等。
然而,现实世界是由因果关系而不是相关性驱动的,而相关性并不意味着因果关系。推荐系统中广泛存在两种因果关系:用户方面和交互方面。用户方面的因果关系是指由因果关系驱动的用户决策过程。例如,用户可能会在购买手机后购买电池充电器。
相关性指的是随着一边的增长,另一边出现增长或者下降的趋势,而因果关系是后者可以作为前者的原因,这种因果关系是不可逆转的
交互方面的因果关系是指推荐策略在很大程度上影响用户与系统的交互。例如,未观察到的用户-物品交互并不意味着用户不喜欢该物品,这可能只是由于未暴露造成的
讲述推荐系统中存在的一些问题
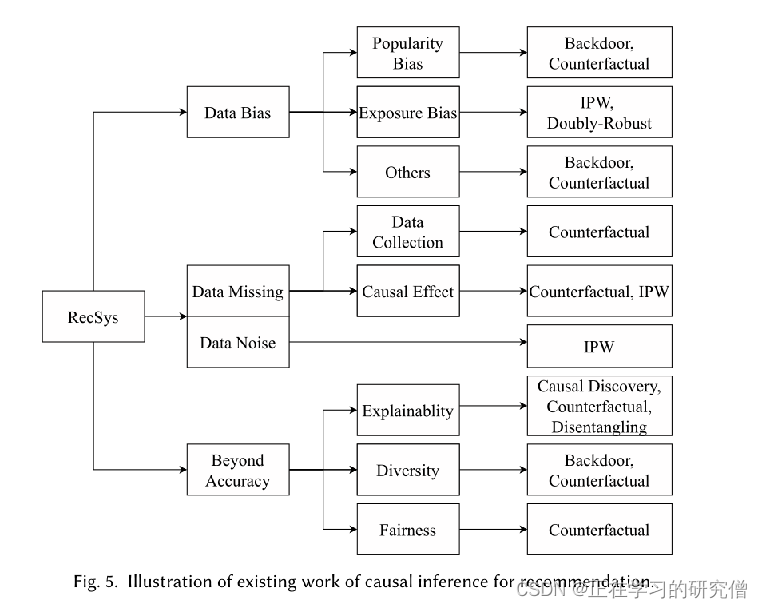
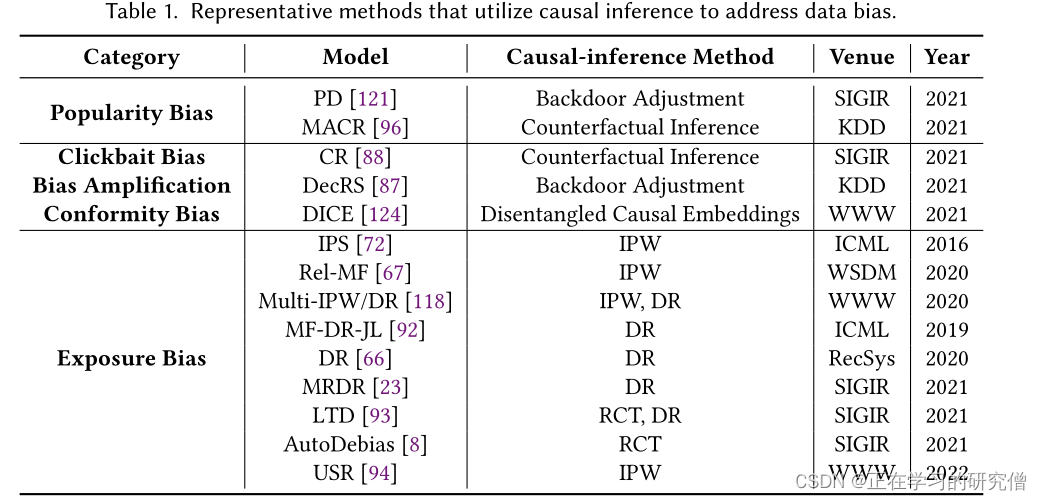
•数据偏差的问题。收集到的数据,如最重要的用户-物品交互数据,是观察性的(而不是实验性的),导致偏差包括从众偏差、流行偏差等。对于非因果推荐系统,模型不仅学习到期望的用户偏好,而且学习到数据偏差,从而导致推荐性能较差。
•数据缺失甚至数据噪声的问题。在推荐系统中,收集到的数据受到收集过程的限制,导致数据缺失或有噪声。例如,尽管存在大规模的道具池,但用户只与一小部分道具进行交互,这意味着无法收集到大量未被观察到的用户-道具反馈。此外,有时观察到的隐性反馈甚至是嘈杂的,并不能反映用户的实际满意度,例如电子商务网站上的一些点击行为以差评结束,或者一些错误的行为。
•超精度目标很难实现。除了准确性,推荐系统还应该考虑其他目标,如公平性、可解释性、透明度等。
改进这些超精度目标可能会损害推荐的准确性,从而导致进退两难。例如,考虑用户行为下的多个驱动原因的模型,基于将每个原因分配为可解纠缠和可解释的嵌入,可以很好地提供准确和可解释的推荐。另一个例子是多样性。与高同质性列表相比,高多样性的项目推荐列表可能无法符合用户的兴趣,而高同质性列表的因果关系可以帮助捕获用户消费特定类别的项目的原因,从而实现准确性和多样性
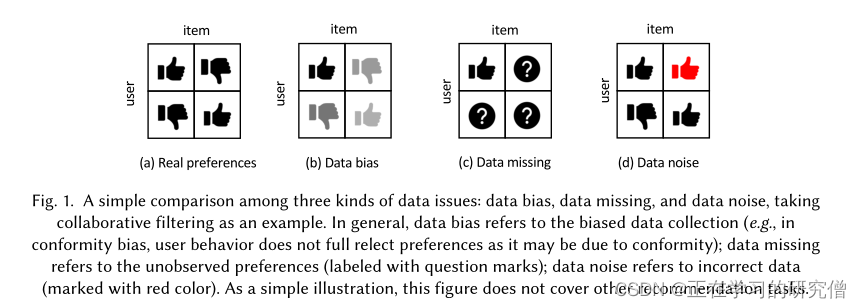
对于b图存在数据偏差就会影响用户对商品的评分(我理解的是小手的颜色的深浅)
对于c图存在数据缺失就会影响用户不会对商品做出评分(没评分就是打了问好)
对于d图存在数据噪声就会影响用户打错分(红色的小手就是打错分)
如何利用因果推理进行解决
1.首先,使用因果推理的推荐方法可以构建因果图,通过这种方法,在大部分情况下造成偏差的因素都可以视作因果图中的混杂因素(confounder),而消除混杂因素影响的方法在因果论中是很成熟的。
(三种最基本的因果图)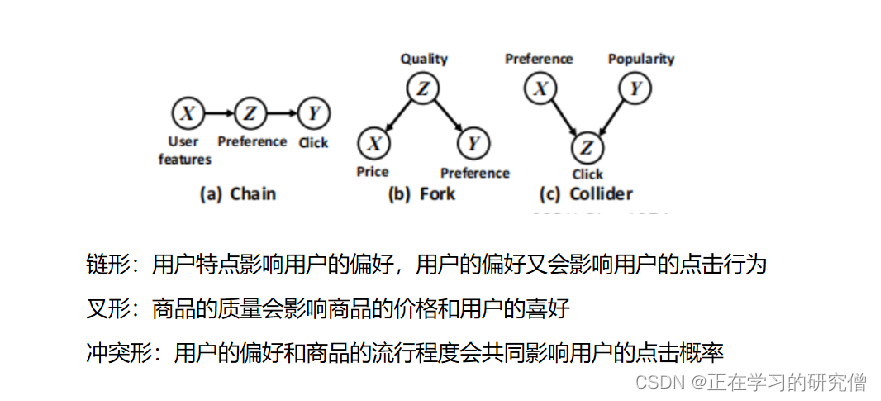
在这三个因果图中我们还要探索其中的相关性
对于链形如果我们观察Z,就是说让Z固定到某个值,那么X,Y就是不相关的,忽视Z,X,Y就是相关的
对于叉形如果我们观察Z,就是说让Z固定到某个值,那么X,Y就是不相关的,忽视Z,X,Y就是相关的
对于对撞如果我们观察Z,就是说让Z固定到某个值,那么X,Y就是相关的,忽视Z,X,Y就是不相关的(可以举例X是生病,Y是出差,Z是教师是否出勤,如果我们观察到某一个老师是否出勤,那么X和Y就是相关的)
2.对于数据缺失的情况,因果增强模型(causality-enhanced models)可以帮助我们构建一个反事实(counterfactual)的世界,因此缺失的数据可以通过反事实解释(counterfactual reasoning)来进行收集。
3.因果推理可以很自然地帮助我们构建可解释的以及可控的模型,这样无论是对于模型本身的可解释性以及对于推荐结果的可解释性都是可以达成的。
4.由于模型是可控的,所以如多样性、公平性等这些目标都是可以达成的。
后门路径指的是通过控制其他变量来测量自变量和因变量之间因果关系的路径。具体来说,当我们想要估计自变量 X 对因变量 Y 的因果效应时,如果存在某些中介变量或共同因素 Z 影响了 X 和 Y,我们就需要通过控制 Z 来消除其影响,从而估计出 X 对 Y 的直接因果效应
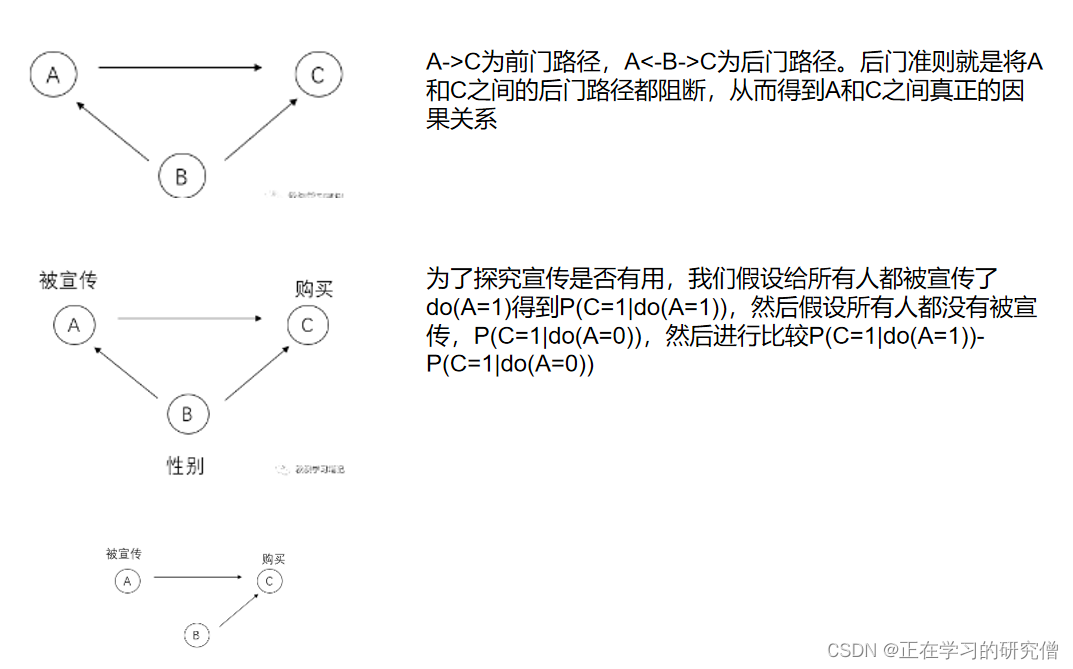
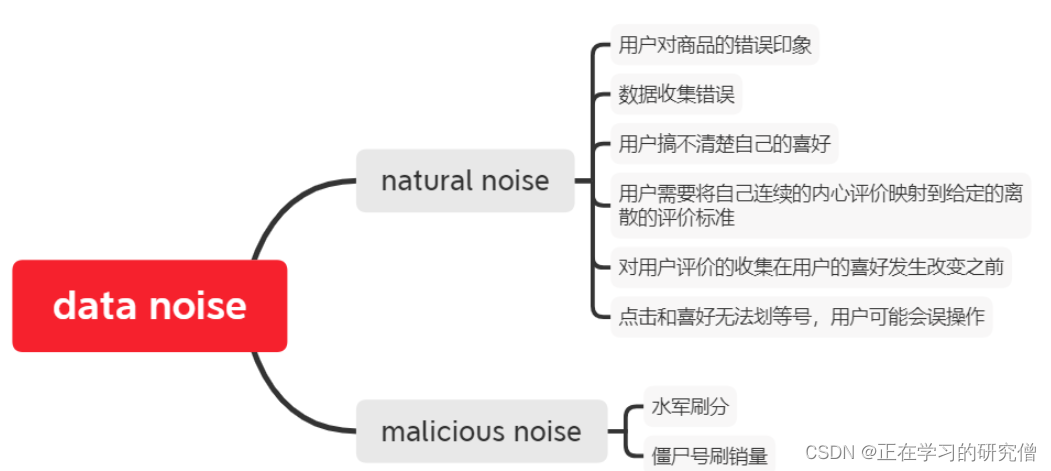
数据噪音的造成
[参考文档]https://blog.csdn.net/qq_42898299/article/details/126863704

















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









