







文章目录
参考
加州大学伯克利分校的 AI 公开课
使用的教材:人工智能:一种现代的方法
搜索算法
- 基于树的搜索算法都是通过扩展 fringe (边缘节点)来搜索整个状态空间的
- 所谓的 fringe 就是叶子节点,也被称为:cadidate expansion (候选扩展节点);
- 首先要确定当下所有的叶子节点,然后根据不同的搜索策略(深度,广度还是uniform )进行 explore。
- 对于某个叶子节点,如果它能够继续被探索,那就证明这条路还没走到头,如果对于当下所处的叶子节点不能进行探索操作,那么就代表这条路走下去已经是死胡同了,解不可能存在于当下节点的扩展当中。
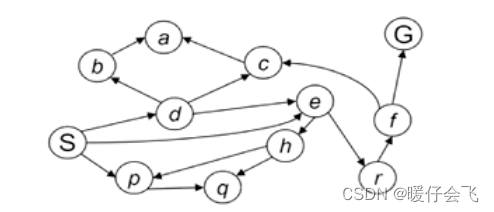
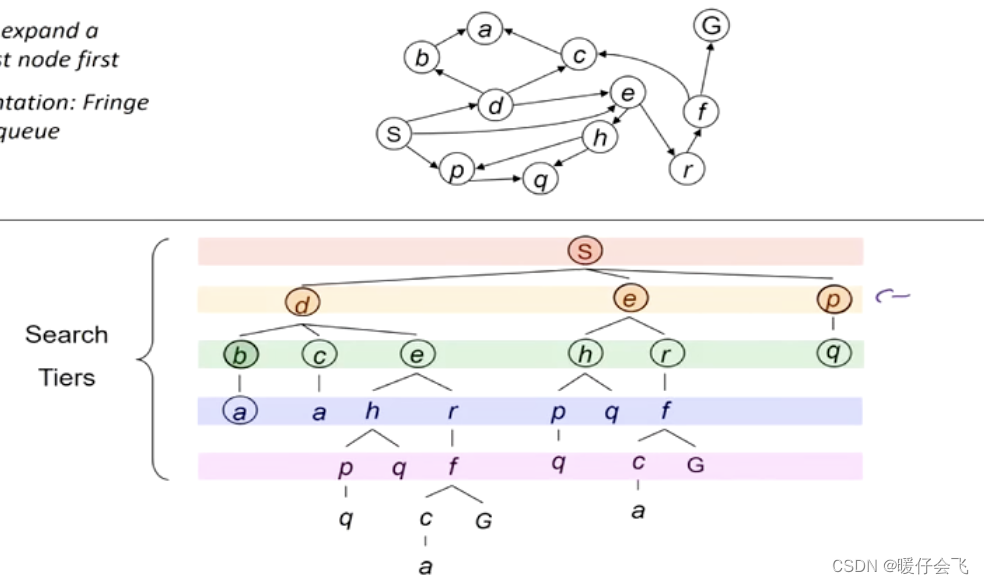
- 对于这样一张图,S 是起点, G 是终点。采用随机策略(这里还没有采用深度或者宽度或者uniform,只是对处在 fringe 的节点随机进行扩展)来对 fringe 进行扩展的步骤如下所示:
- 最开始的 fringe 只有一个 S
- 对 S 进行扩展,得到:
- S -> d
- S -> e
- S -> p
- 这时候 fringe 变成了 d, e, p 而 s 从 fringe 中移除;
- 接下来对 d 进行扩展:
- S -> d -> b
- S -> d -> c
- S -> d -> e
- 同时 fringe 变成了 b, c, e, p;同时 d 从 fringe 中移除
- 接下来选择 e 进行扩展:
- S -> d -> e -> h
- S -> d -> e -> r
- 同时 fringe 变成了 b, c, h, r, e, p;同时 e 从 fringe 中移除(但是中间分支的 e 依然还在 fringe,中,他依然可以被探索)
- 。。。。
- 最终就是上图中展示的路径。
下面来讨论选择何种方式来扩展当前的节点。
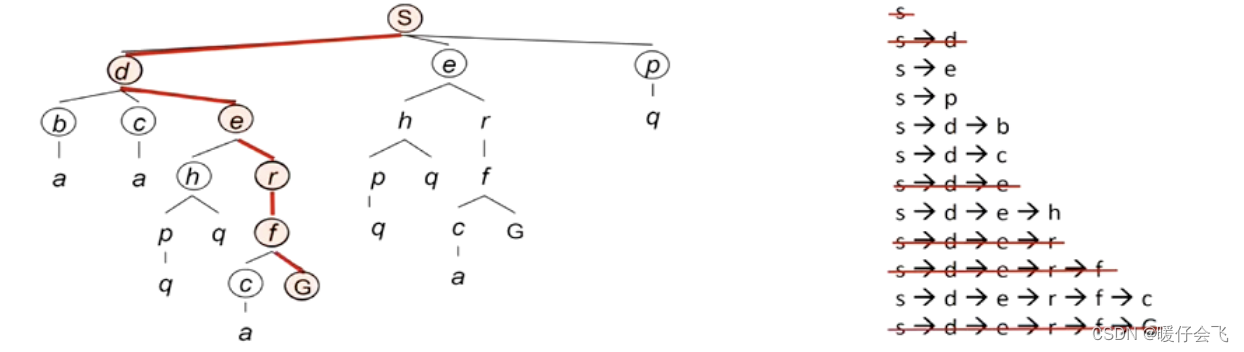
深度优先搜索 depth-first search
- 最开始也是从 S 开始,fringe 只有 S 一个节点;通过扩展 S 节点,目前有 d, e, p 三个节点加入了 fringe,作为下一步的可扩展节点
- 深度有限遍历会优先选择最深的候选节点,但是 d, e, p 现在深度是相同的,因此按照字母的排序,首先扩展 d,这之后,fringe 节点变成了 5 个,从左到右依次是:b, c, e, e, p
- 同样的步骤,下一个探索的将会是 b 节点,而 a 将被加入 fringe 中,fringe 更新成: a, c, e, e, p
- 对于当前 s -> d -> b -> a 的路径,发现 a 不能继续扩展,所以这条路走到头了
- 因此现在开始扩展 c,s-> d -> c-> a 发现这条路也不能扩展,因此 fringe 中只剩 e,e,p 了
- 扩展 e,fringe 更新为:h, r, e, p
- 延续这个过程,一直到找到 G 节点,返回最终路径
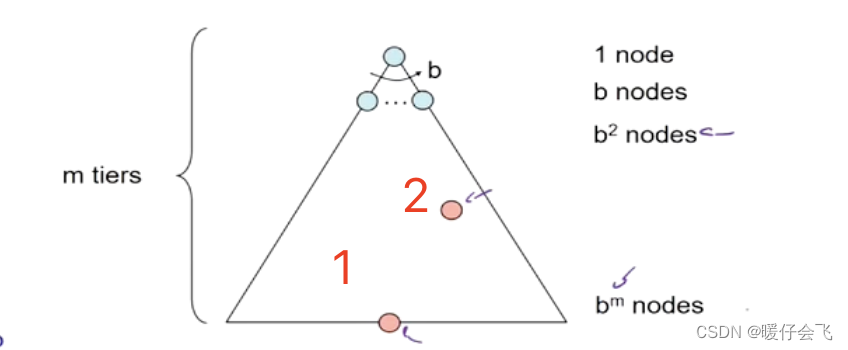
性能分析
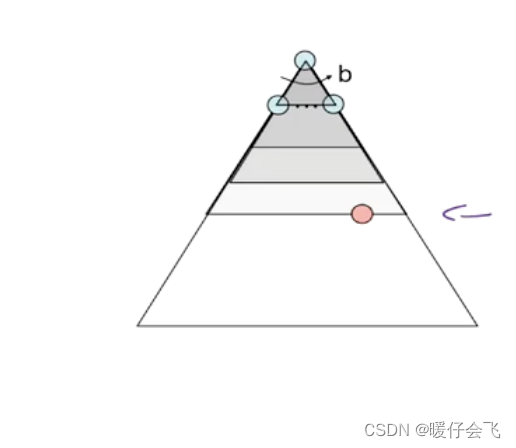
- 假设一棵树的分支因子是 b:即在每个节点都有最多 b 个分支
- 树的最大深度是 m
- 假设这棵树中解的路径有两个,图中两个粉色的点
- 下面所有的性能分析都基于一个假设:树不能是无限的,也就是说不能出现循环的情况,那样的情况分析性能没有意义。
完整性 complete
- 完整性的定义:当解存在的时候,是否保证能够找到解
- 对于深度优先的策略,符合完整性
最优性 optimal
- 当解存在的时候,是否能够找到 cost 最小的解(找到最优解)
- 深度优先不满足最优性,因为当从左到右遍历的时候发现了解1,就会直接返回解的路径;因此并不能保证找到最优解
时间复杂度
- 找到解所消耗的最大时间
- 在深度优先的策略中,最坏的情况是解出现在最右下角的那个地方,这个时候,树的所有节点都会遍历一遍,因此复杂度是 O ( b m ) O(b^m) O(bm)
空间复杂度
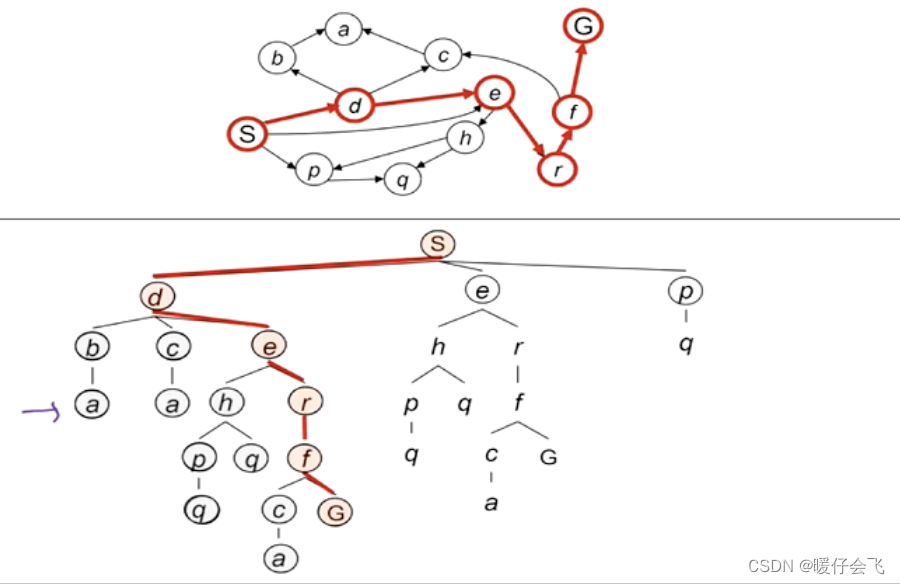
- 在搜索的过程中,最多将多大规模的节点保存在内存中;也就是 fringe 的点的个数最多有多少。
- 拿这个图举例:
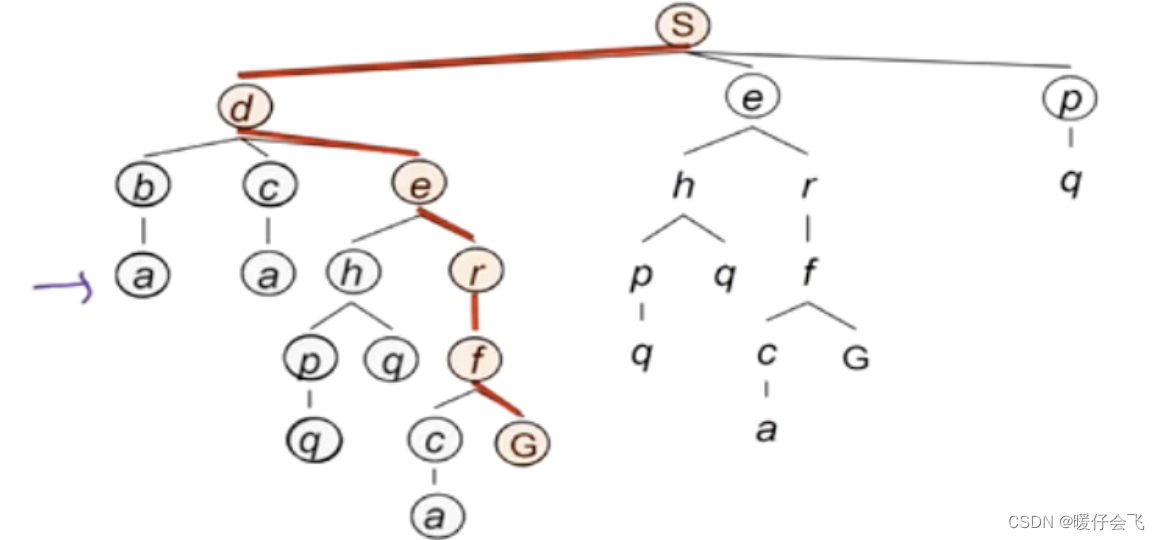
- 最多的时候,就是对于 s-d-e-r-f-g,所有被放在 fringe 中的节点,一共就是 b,c,h,c,e,p;所以最大是当前探索的路径长度 d d d * (分支因子-1) 的规模,而路径长度在上面也说了,最差是 m m m,分支因子是 b b b 所以最坏的空间复杂度是 m × ( b − 1 ) m\times (b-1) m×(b−1) 即 O ( b m ) O(bm) O(bm)。
广度优先搜索 breadth-first search
- 一种层层剥离的感觉,知道横向在某一层中找到解
性能分析
完整性 complete
- 对于广度优先的策略,符合完整性
最优性 optimal
- 广度优先在一定条件下满足最优性,因为在某一层中遍历的时候发现了解,这个时候就能保证这个解是在最浅的分支上。但是当且仅当树的深度是 cost 的时候才能满足最优性,也就是说如果这个时候 cost 是距离或者是别的什么标准,就不能盲目的说广度优先的解是最优的。广度优先只能保证能找到最“浅” 的解。
时间复杂度
- 在广度优先的策略中,最坏的情况是解出现在最右下角的那个地方,这个时候,树的所有节点都会遍历一遍,因此复杂度是 O ( b m ) O(b^m) O(bm),但多数情况下其实并不会到达最深的那一层,因此对于广度优先遍历,我们假设解出现的深度为 d d d 那么这个他的时间复杂度是 O ( b d ) O(b^d) O(bd)
空间复杂度
- 由于广度优先是一层层遍历,所以 fringe 永远是最后一层的节点数量-1,因此,空间复杂度是: O ( b d ) O(b^d) O(bd)
BFS V.S. DFS 动画演示
无障碍情况
BFS
DFS
有障碍情况
BFS
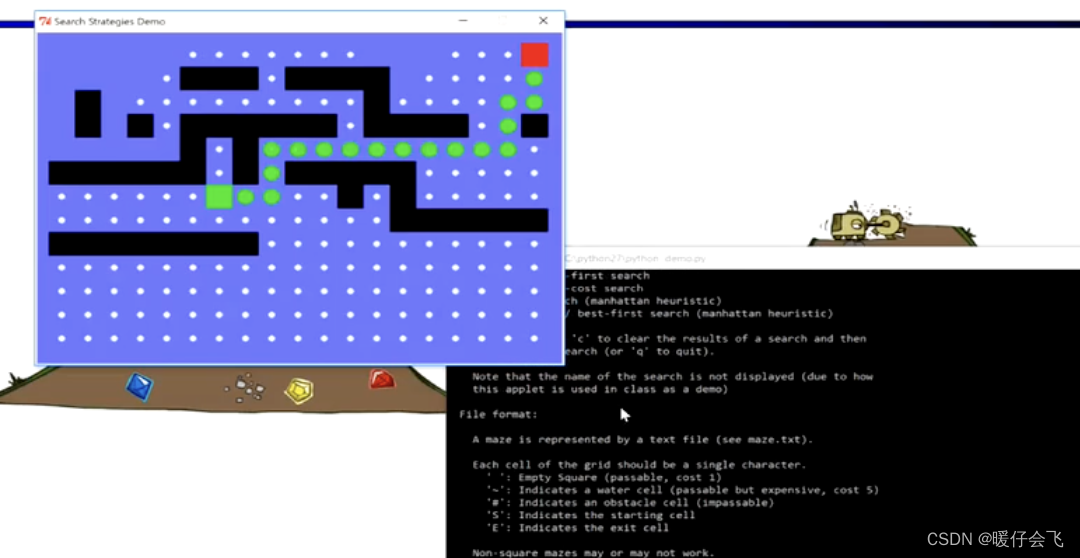
DFS
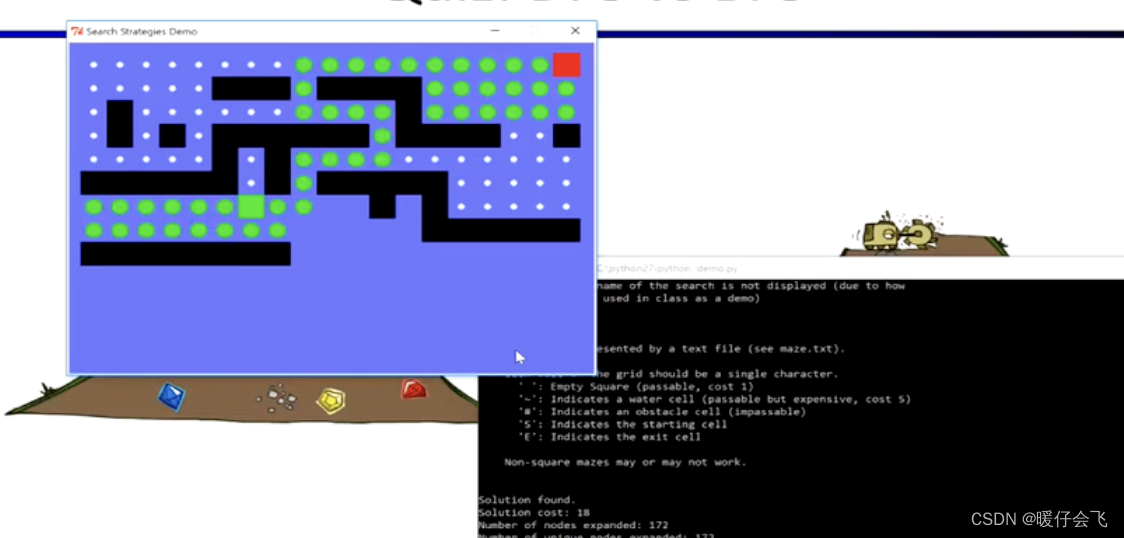
何时 BFS 优于 DFS
- 当在较浅的层存在解
- 当我们一定要寻找最优解
何时 DFS 优于 BFS
- 当解都处于较深的层
- 当内存有限制
迭代深度搜索 (Iterative Deepening )
- 永远执行深度搜索;但是限制深度,到达设定的深度或者找到解就停下来
- 如果找不到解,那么重新设置深度,再重复上述步骤
- 直到找到解为止
- 这看起来是一种计算冗余的方式,但是其实是高效的;永远不会存在内存问题
- 而且由于搜索的最后一层才是数据量暴增的地方,因此,通过这样的方式引入的冗余其实是很小的。
Uniform Cost Search(引入 cost)
-
如果不同的步骤之间的 cost 是不同的,那么最优解就是通过 cost 进行衡量的,而不是树的深度。
-
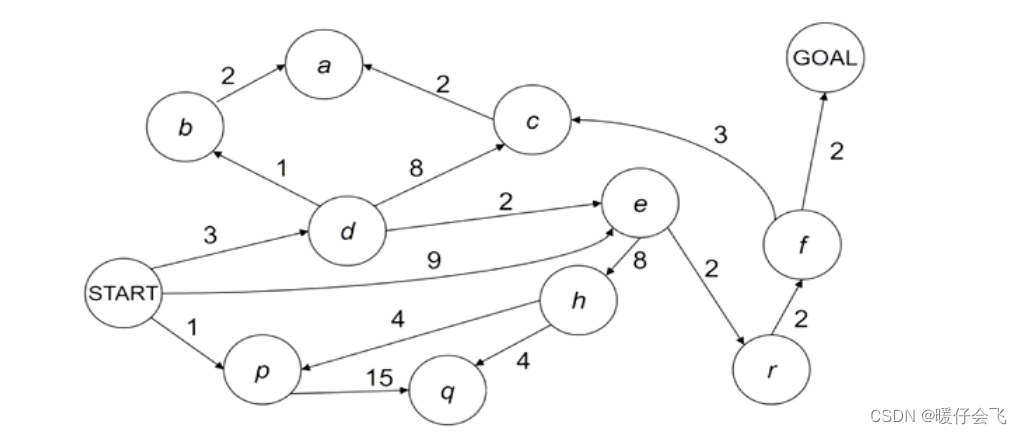
下面的例子中,假设从起点出发到达终点,路径上的数字就是两个点之间的距离(cost)。我们希望最后的路径的 cost 最小。
-
从 fringe 中每次挑出 cost 最小的节点进行扩展。注意:这里说的 “cost 最小的节点”指的是从起点到 fringe 节点的累积 cost,而不是单条箭头上的 cost,例如从 start 到 d 的cost 是 3,start 到 b 的cost 是 4
-
基于此,我们可以得到下面的结果:
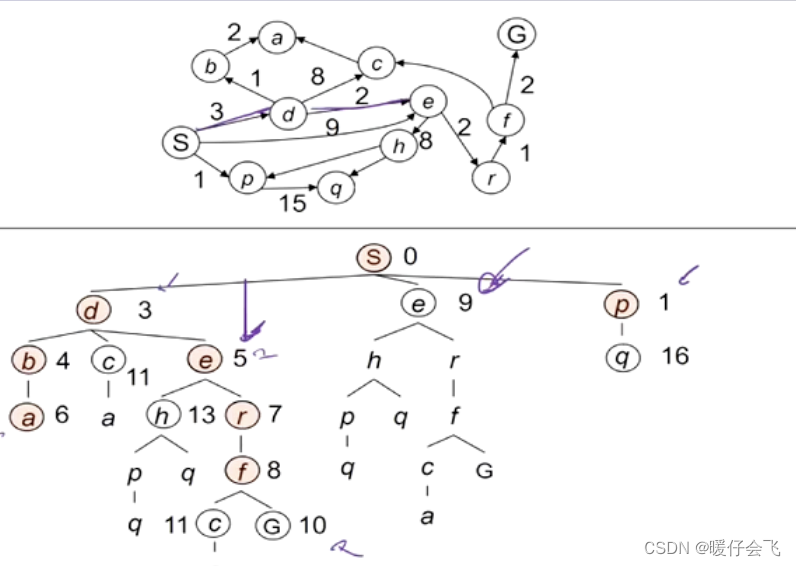
-
首先扩展 S, fringe 中加入 d, e, p 然后选择累积 cost 最小的 d,fringe 更新为 b, c, e, e, p
-
根据累计的 cost 不断下去最终形成了 s - d - e - r - f
-
然后重点来了虽然 G 就是 f 的子节点,但是由于从 f-g 并不是当前的最小 cost,所以依然不会选择 g 这个节点去扩展而得到解。这就是为什么在这个算法中要 “先算 cost 再扩展” 的原因。因此在当前的情况下 fringe 是 c, h, c, g, e, q 而 cost 最小的是 cost=9 的 e 节点,因此扩展 e节点
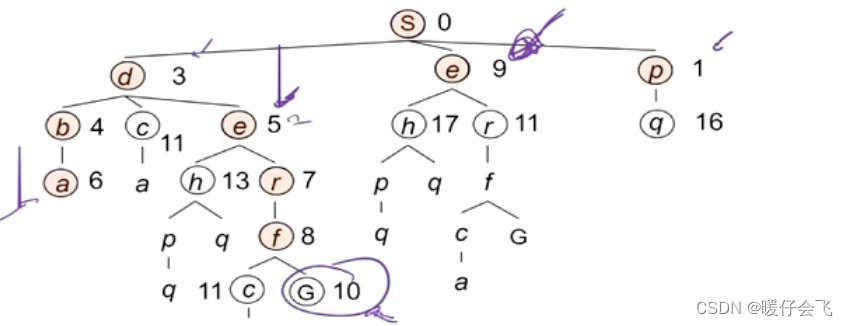
-
扩展完 e 之后,接下来应该扩展 g 了,然后形成最优路径 s - d - e - r - f - g
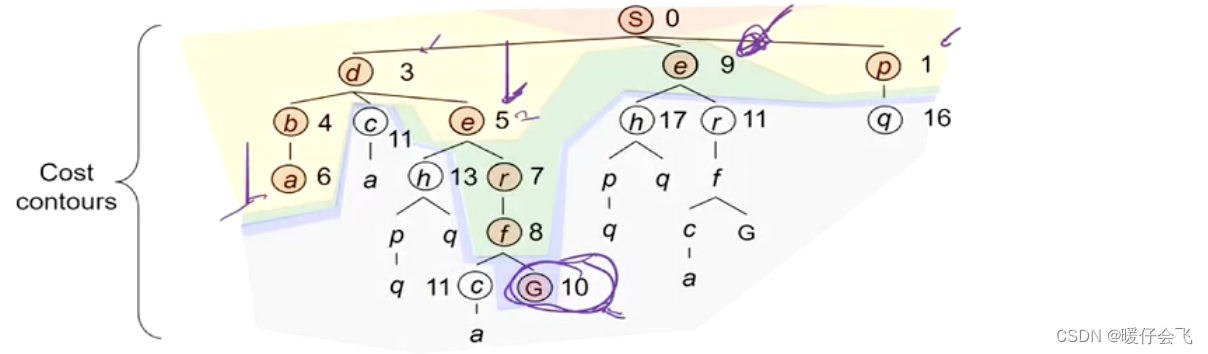
性能分析
完整性 complete
- 假设树是有限的,并且没有两个点之间的 cost 是负数,那么就满足完整性
最优性 optimal
- 满足最优性
时间复杂度
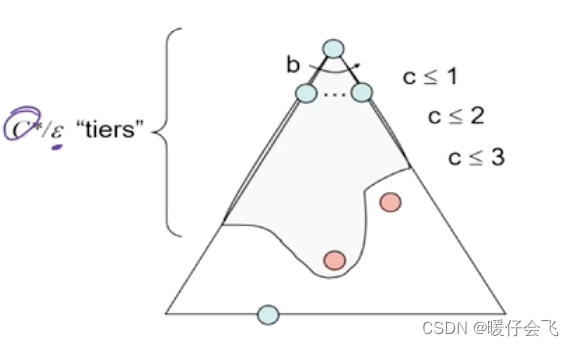
- 假设最优解的 cost 一共是 C ∗ C^{*} C∗,每一步的最小 cost 是 ϵ \epsilon ϵ;那么到达最优解之前走的步数最多是 C ∗ / ϵ C^{*}/\epsilon C∗/ϵ;所以复杂度最多是 O ( b C ∗ / ϵ ) O(b^{C^{*}/\epsilon}) O(bC∗/ϵ)
空间复杂度
- 空间复杂度取决于 fringe 中的节点数量,而在 uniform-cost search 中 fringe 中节点的个数取决于深度,下图中紫色标出的线就是 fringe 中的节点数量,因此量级也是
O
(
b
C
∗
/
ϵ
)
O(b^{C^{*}/\epsilon})
O(bC∗/ϵ)
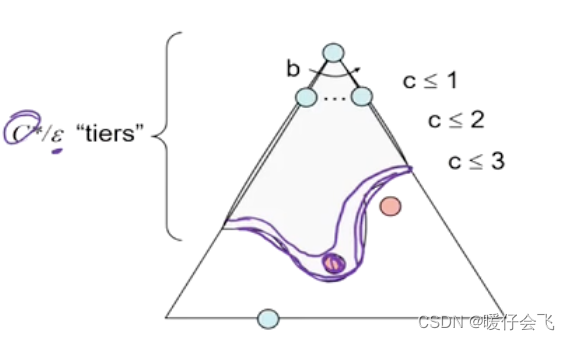
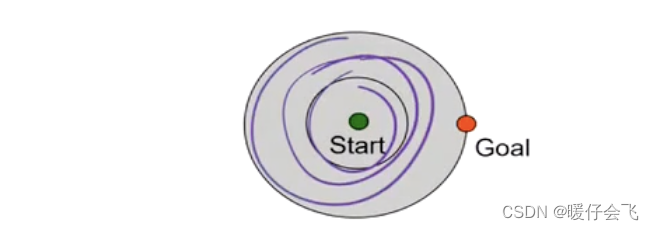
局限性
- 将所有的方向都看成等价的
- 对于目标节点的方向没有任何信息,因此只能是一圈圈往外扩展去寻找解
Uniform-Cost V.S. BFS V.S. DFS
- 在有一些障碍的情况下比较 BFS 和 uniform-cost search 的行为
- 蓝色的部分表示有水,经过这些水的代价不同,经过浅蓝色的地方 cost 比较低,深蓝色的地方 cost 比较高

Uniform-cost search
- 在浅水区的步骤更多

BFS
- 广度有限搜索忽略了 cost,把深水区和浅水区看成相同的,因为它关心的是树的 “最浅”,而不是 cost

DFS
- DFS 也是忽略了所有的浅水区和深水区


















 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











