









什么是 Instance-based learning
-
对于一个机器学习系统,输入有下面三个方面的内容组成:
- 样本 (instance)
- 特征(attributes / Features)
- 标签 (classes / labels)
-
每个样本可以看做是一个包含 n n n 个特征的元组同时拥有一个表明类别的标签(对监督学习来说)
-
机器学习的目的是根据数据提供的 label 标签,试图构建一个模型,这个模型可以代表整个数据集的输入和输出关系。
-
instance-based learning:
- 需要将进行标注的 instance 保存在内存中
- 直接从 instance 中学习(而不建立任何的模型)
- 也称为 memory-based learning
如何比较样本(Comparing Instances)
- 对于每个 instance,因为它的特征是一个
n
n
n 元组,那么我们总是可以把这个
n
n
n 元组看成是一个向量
f
⃗
\vec{f}
f
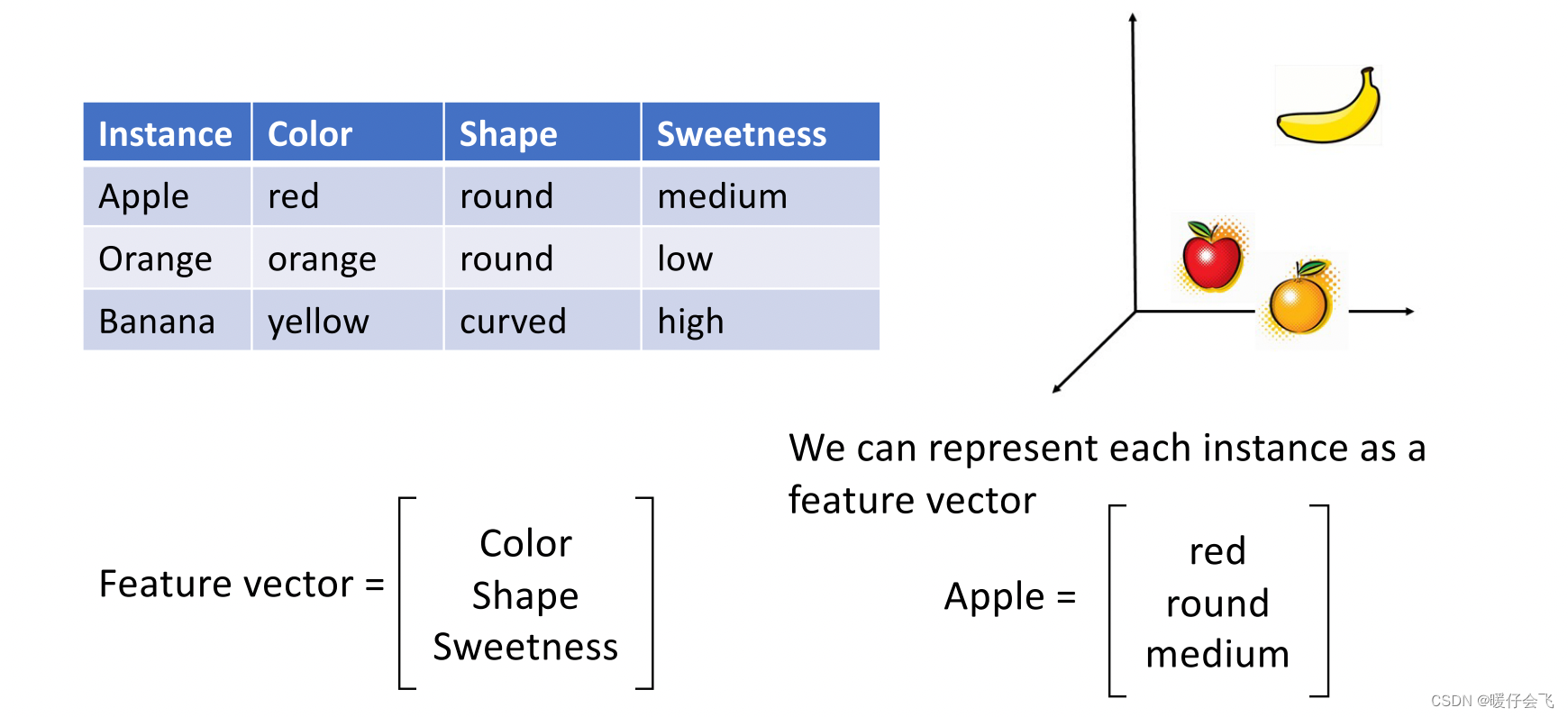
特征向量 (Feature Vectors)
-
特征的类型 有如下几种:
- nomial / categorial / discrete: 比如颜色特征有红色、蓝色 这种离散的非数值特征可以表征 instance 的某个特点
- ordinal : 这类特征是有严格顺序的,例如酒店的星级,不仅仅是 1,2,3,4 星单独的数字,而且还包含着 4 星比 1星好;类似的还有描述温度程度的特征 cool < mild < hot
- numeric / continuous: 这种是连续的数值特征:例如身高、体重、年龄
-
特征向量根据之前的描述,我们可以看做一个 n n n 元组,那么我们可以将描述这个向量的 n n n 维空间看做是向量的特征空间。通过这种方式,我们可以衡量任意两个具有相同维度的特征向量的相似度、长度等很多指标来实现对向量定量计算和判断的目的。
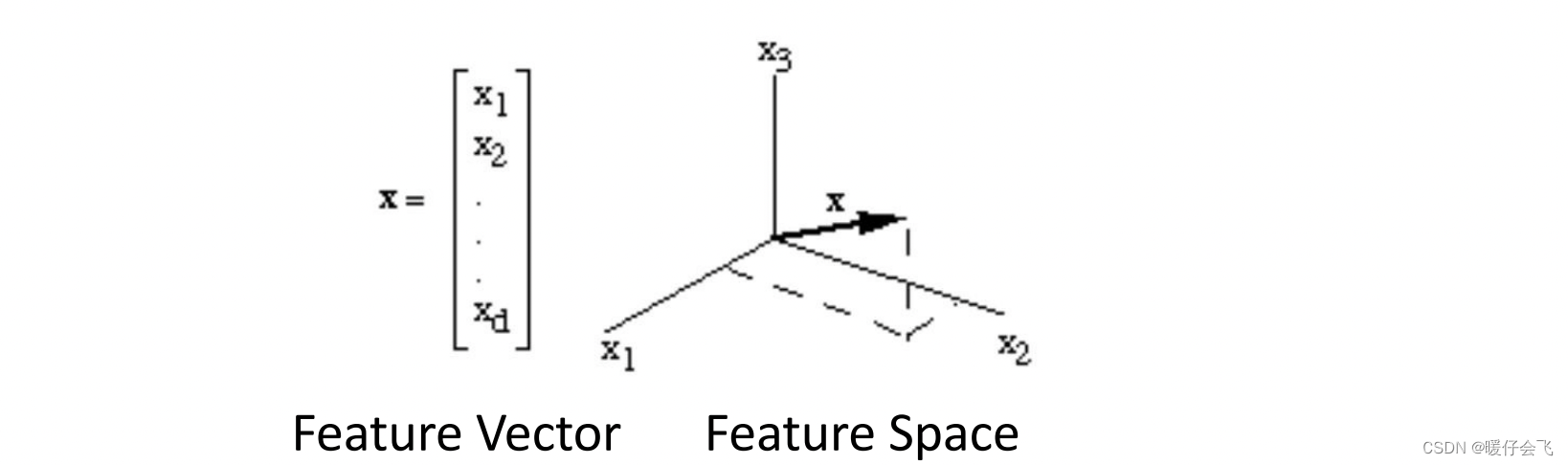
特征向量的度量(Similarity / Distance)
相似度 (Similarity)
- 两个向量的相似度:
- 衡量两个向量之间有多像
- 值越大代表相似度越高。通常相似度的取值范围在 [ 0 , 1 ] [0,1] [0,1] 之间
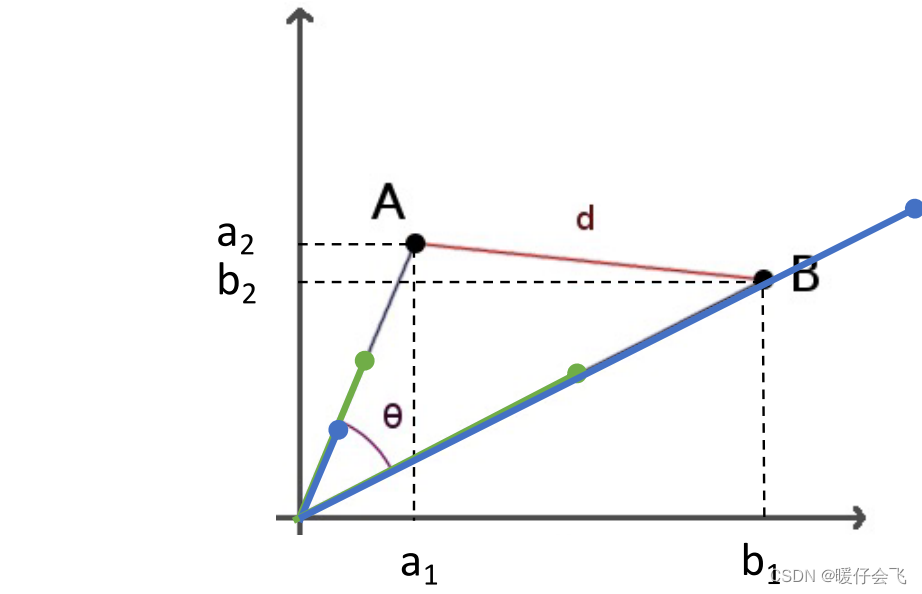
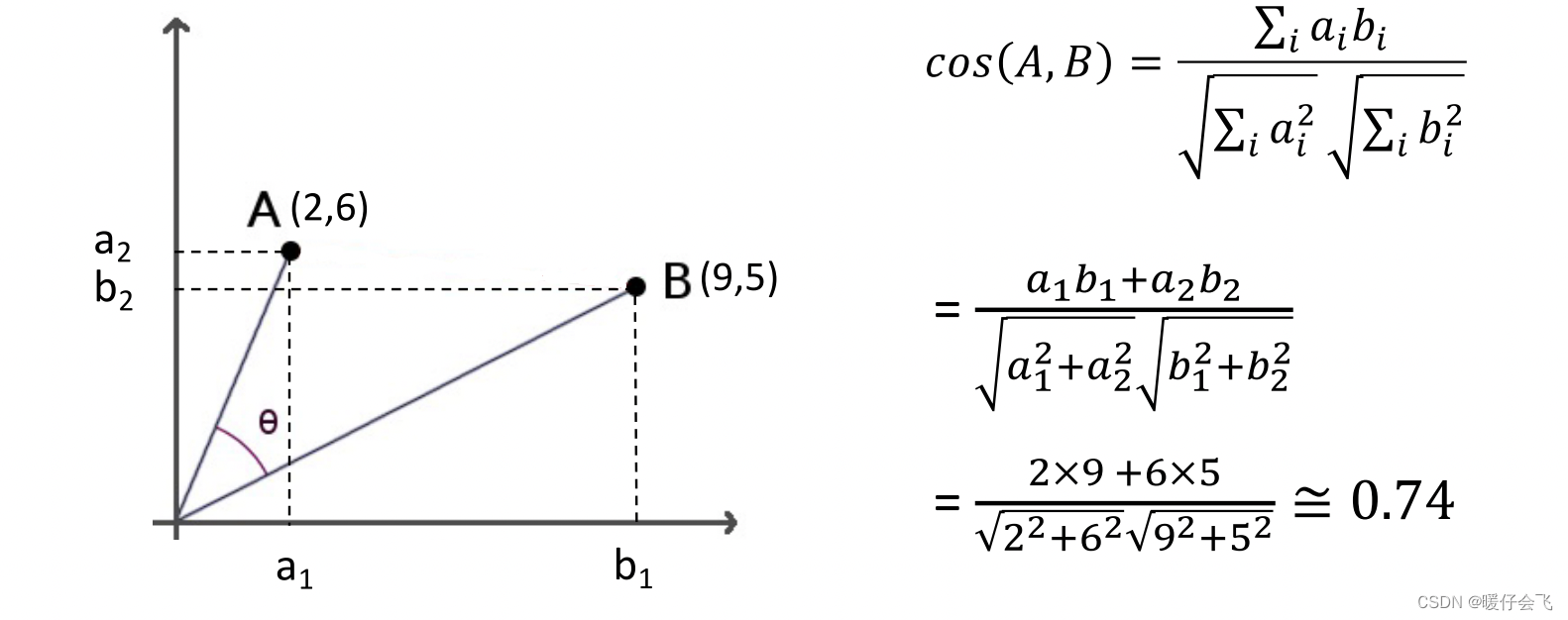
余弦相似度(Cosine Similarity)
- 给定两个instance,他们的特征向量分别是
a
⃗
,
b
⃗
\vec{a}, \vec{b}
a,b,可以通过计算两个特征向量的角度作为余弦相似度
c o s ( A , B ) = ∑ i a i b i ∑ i a i 2 ∑ i b i 2 = a ⃗ ⋅ b ⃗ ∣ a ⃗ ∣ ∣ b ⃗ ∣ ( 1 ) cos(A,B)=\frac{\sum_ia_ib_i}{\sqrt{\sum_ia_i^2}\sqrt{\sum_ib_i^2}}=\frac{\vec{a} \cdot \vec{b}}{|\vec{a}||\vec{b}|}~~~~~~~~~~~~(1) cos(A,B)=∑iai2∑ibi2∑iaibi=∣a∣∣b∣a⋅b (1)
距离(Distance)
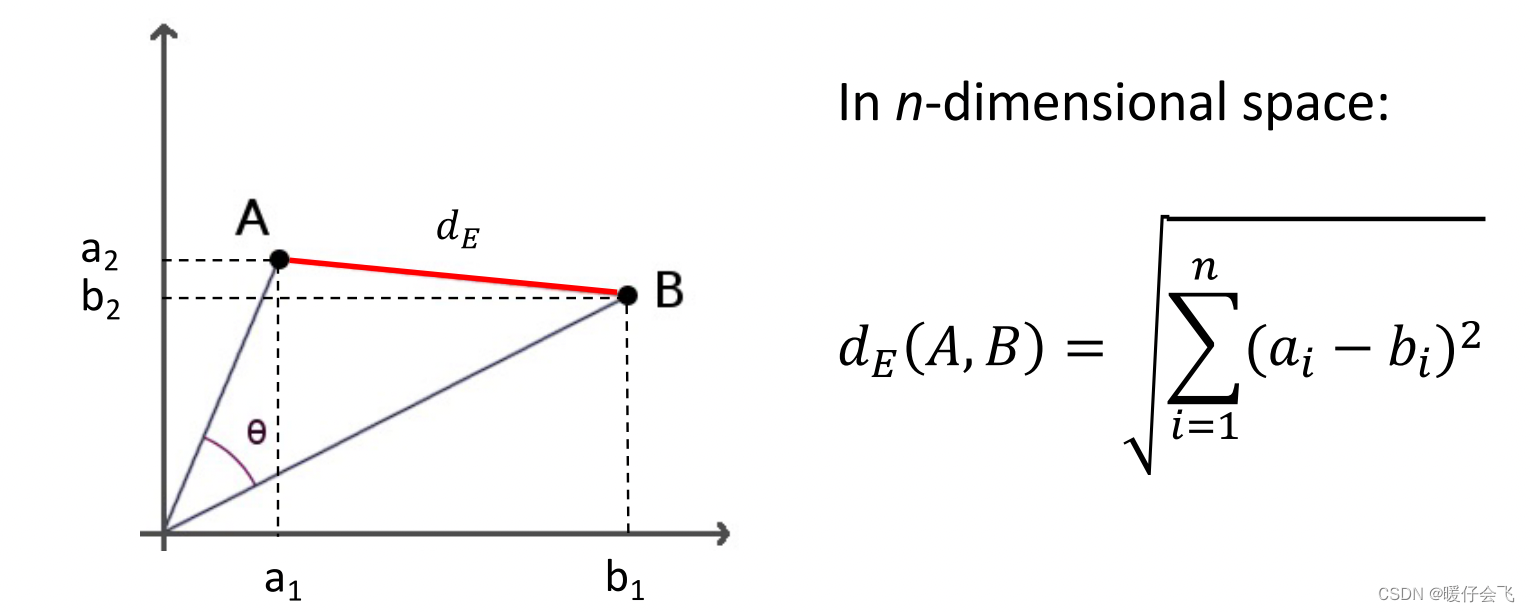
- 两个向量之间的距离 distance :
- 衡量两个向量之间有多 不像
- distance 越小表明两个向量越像
- 两个向量的最小距离是 0
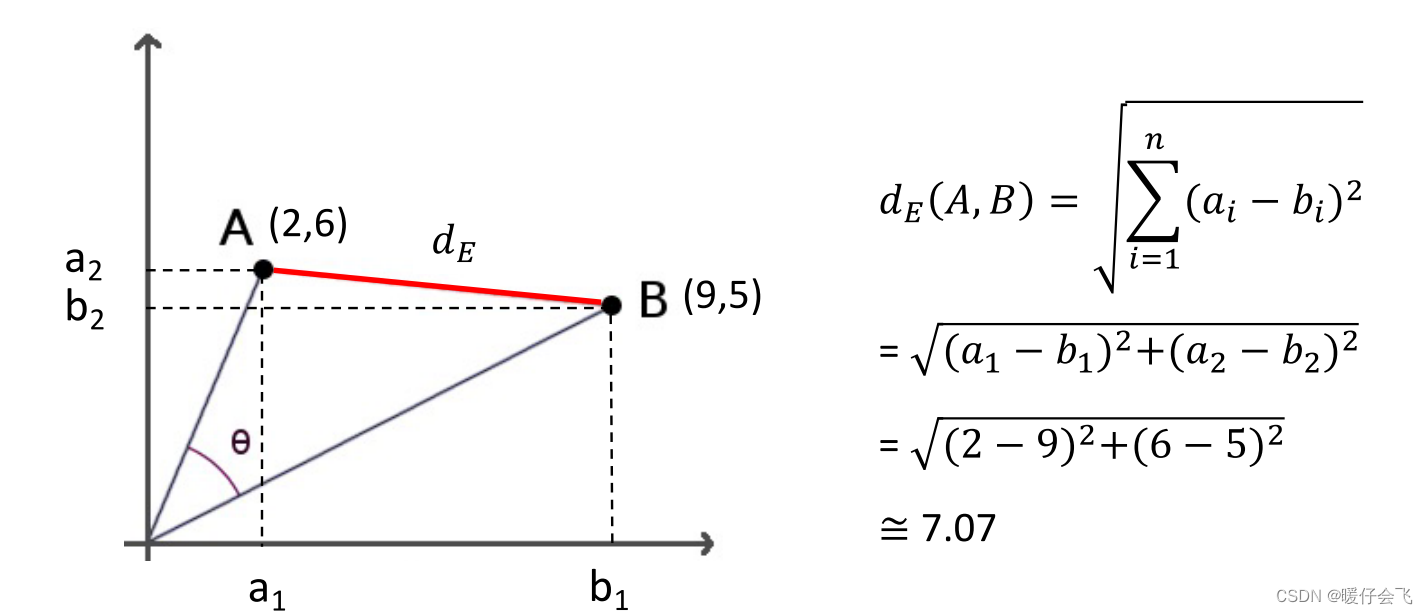
欧几里得距离 (Euclidean Distance)
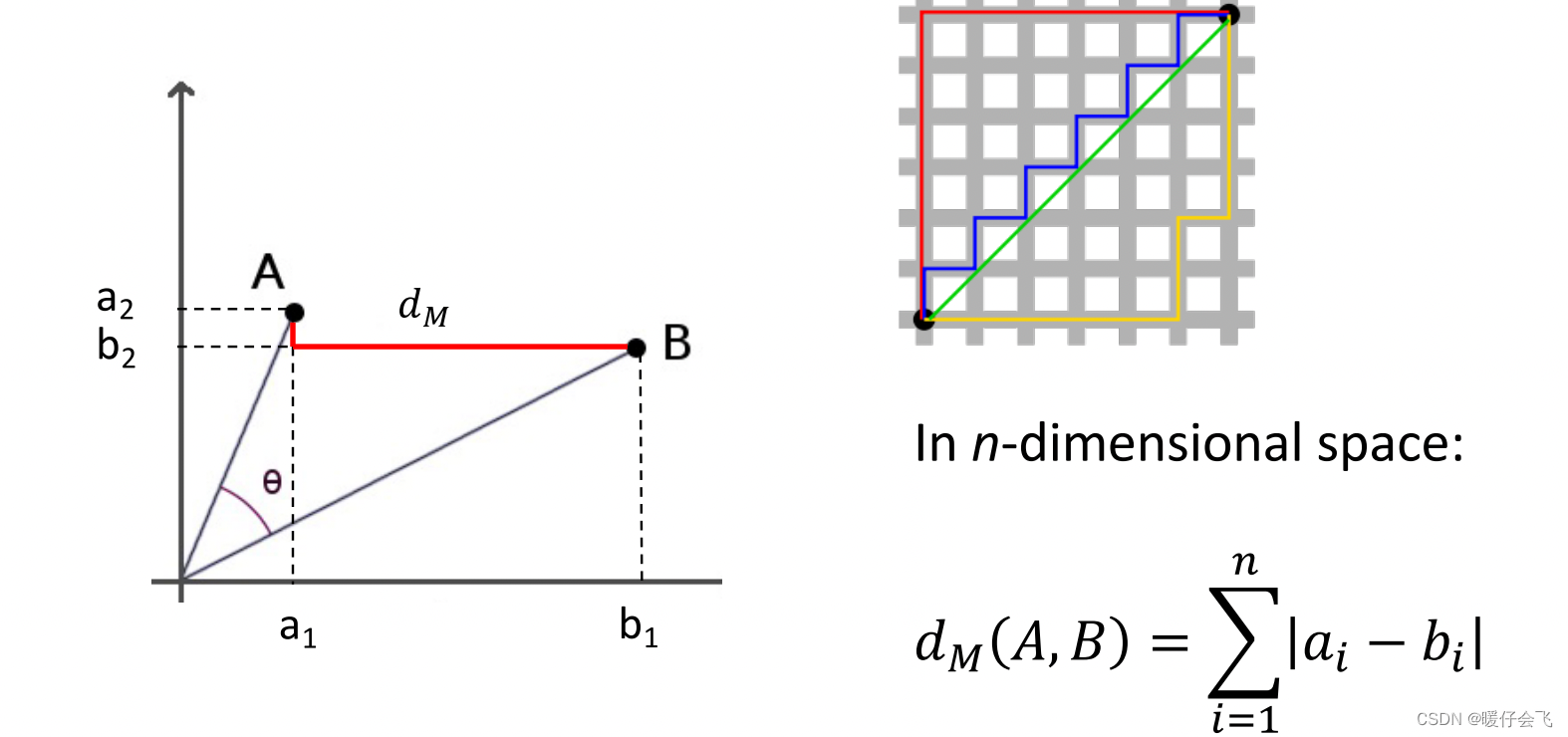
曼哈顿距离(Manhattan Distance)
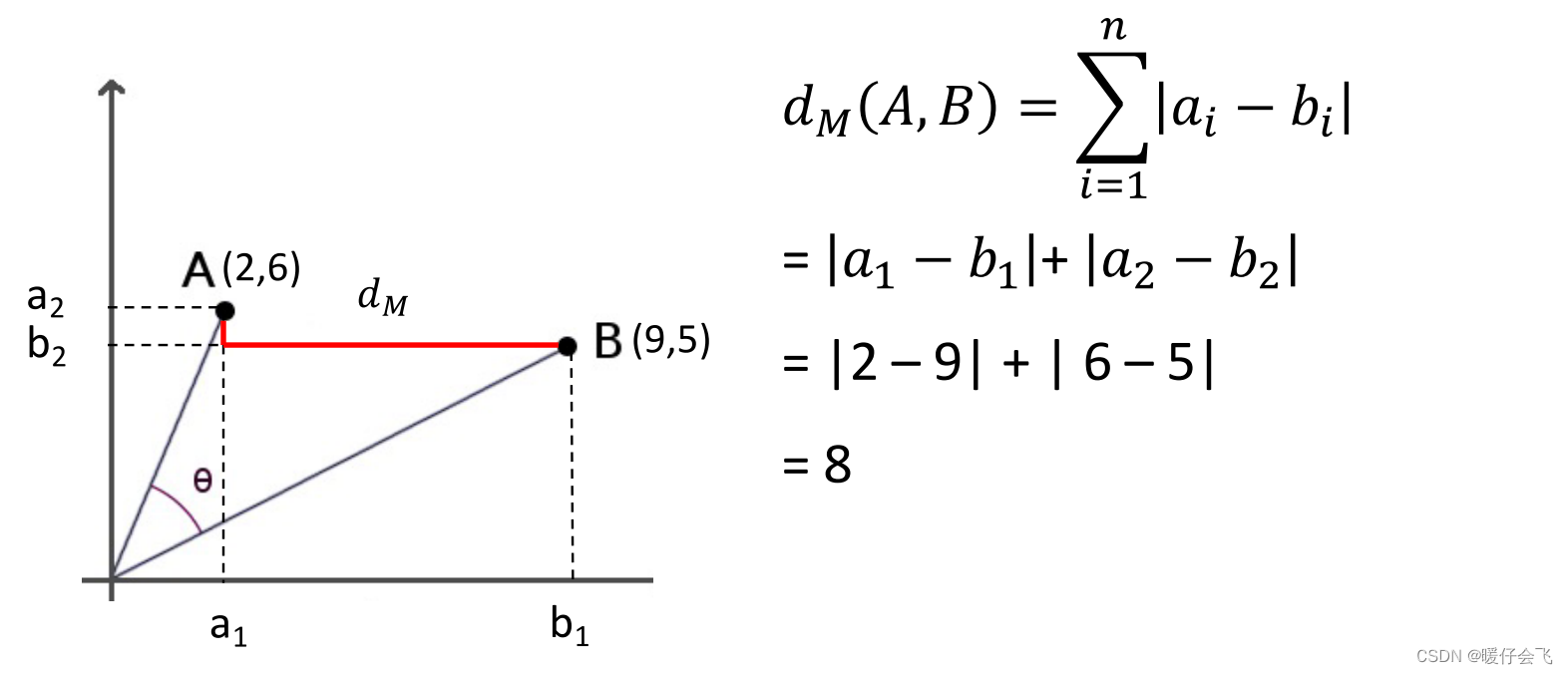
Hamming 距离
- 上面说的两个特征向量距离的度量方式必须要求每一个维度的特征都要是数值类型的,那么如果对于下面这种包含 nomial 类型的 instance 之间,如何衡量 distance
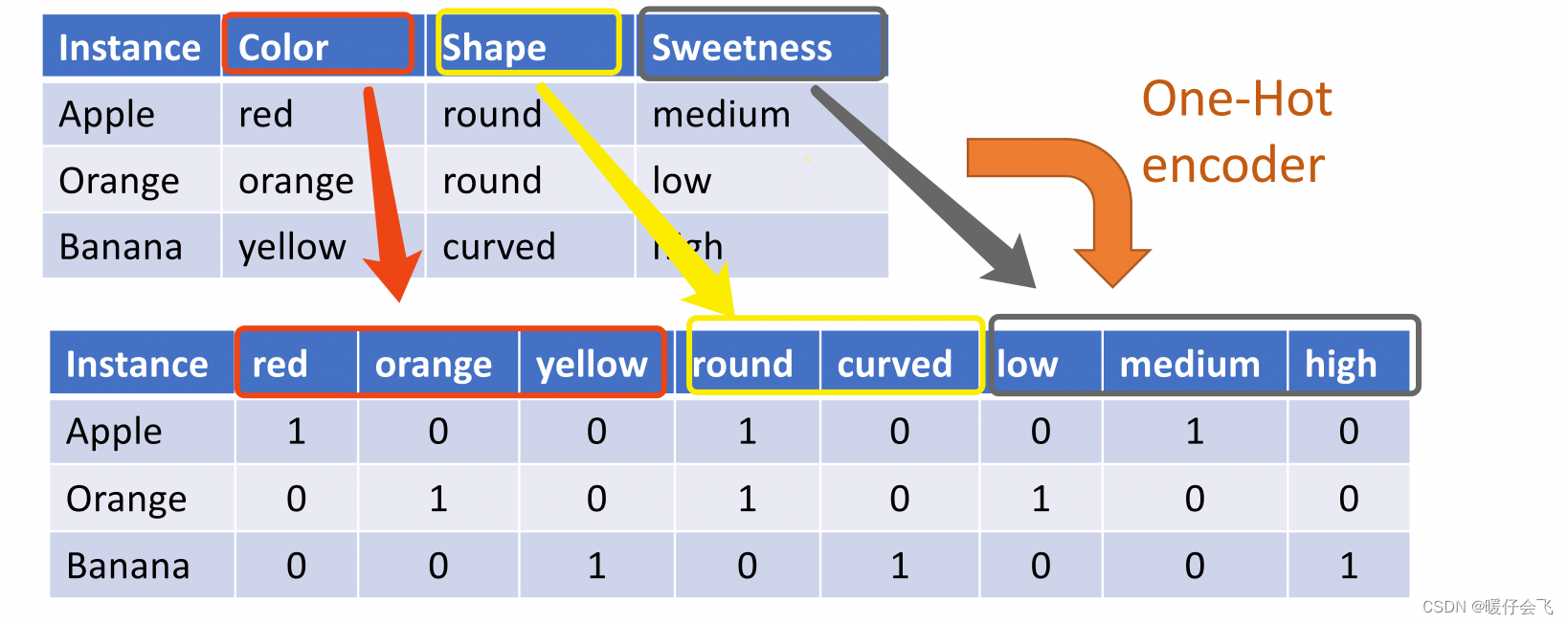
- 首先应该将所有的 nomial 特征都使用 one-hot 编码的方式进行转换
- one-hot 就是一种将非数值特征转换成数值特征的方式。而且能够保证特征在转换之后,不同的取值在距离上都是完全一样的。例如 color 这列特征,在进行 one-hot 编码之后,所有的特征取值都变成了用 3 个位表示的向量;无论是 red 和 orange 还是 red 和 yellow 或是 orange 和 yellow 之间,都只有一个 bit 位的不同,因此他们相互之间都是公平的。
- 如果不用 one-hot 可能会造成一种不公平的现象,即,假设还是对 color,我们让 red=1,orange=2, yellow=3;看起来他们之间还是彼此距离一样,但其实有一个问题,就是对机器来说,很可能认为 yellow 的优先级高于 red 和 orange,因为 yellow 的数值较大。而使用 one-hot 就可以完美解决这个问题
- 但是 one-hot 问题就是会造成特别系数的矩阵,例如 color 3 个颜色还好,如果有一个特征有 100 种不同的取值,那么通过 one-hot 编码出的新特征就会是一个长度为 100 的值,里面除了某一个 bit 位上的值 =1 之外,其他的位置都是 0。

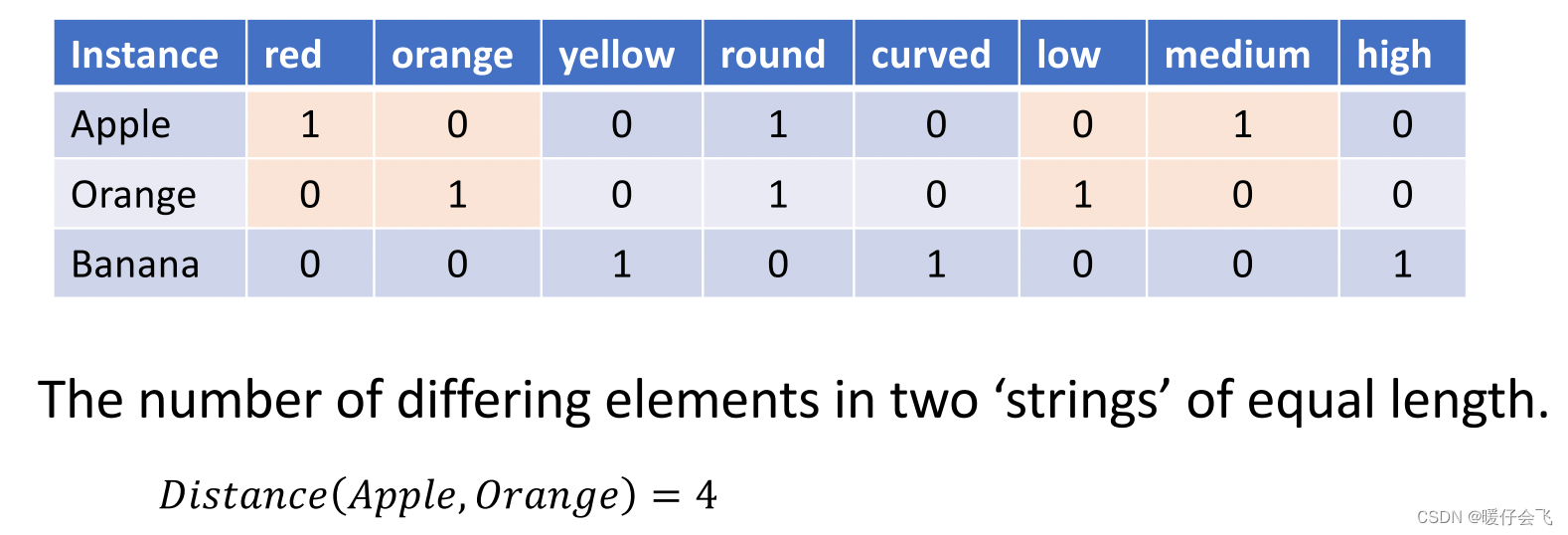
- 经过 one-hot 编码之后我们就可以衡量两个样本之间的距离了:
- 从图中可以看出 Apple 样本和 Orange 之间有 4 个bit 位是不同的,因此他们的距离就是 4 ,而 Apple 和 Banana 的距离是 6

Instance-Based 分类器
最近邻分类器(Nearest Neighbor Classifier)
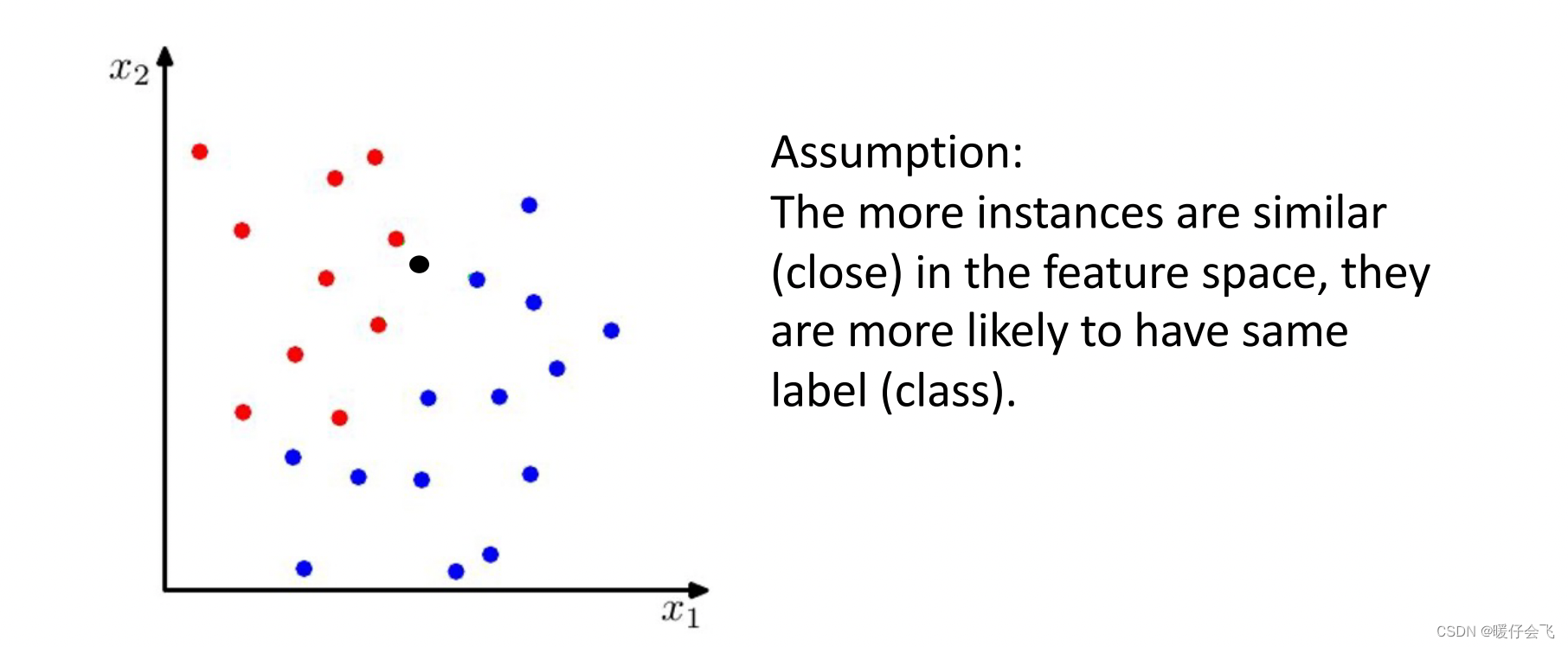
基于的假设
- 最近邻分类算法基于的假设是:空间中两个样本的距离越相近,那么他们越可能拥有相同的标签。
算法细节
- 对于一个样本
x
x
x(测试样本,没有 label),离他最近的一个训练样本(有 label 的样本)是
y
y
y,它所有的邻居样本是
z
∈
Y
z\in Y
z∈Y;在所有邻居样本中通过距离/相似度测算得到距离最小或者相似度最大的邻居样本:

- 用这个邻居样本的 label 作为当前 x x x 的 label。
- 通过最近邻算法得到的决策边界是非线性的。
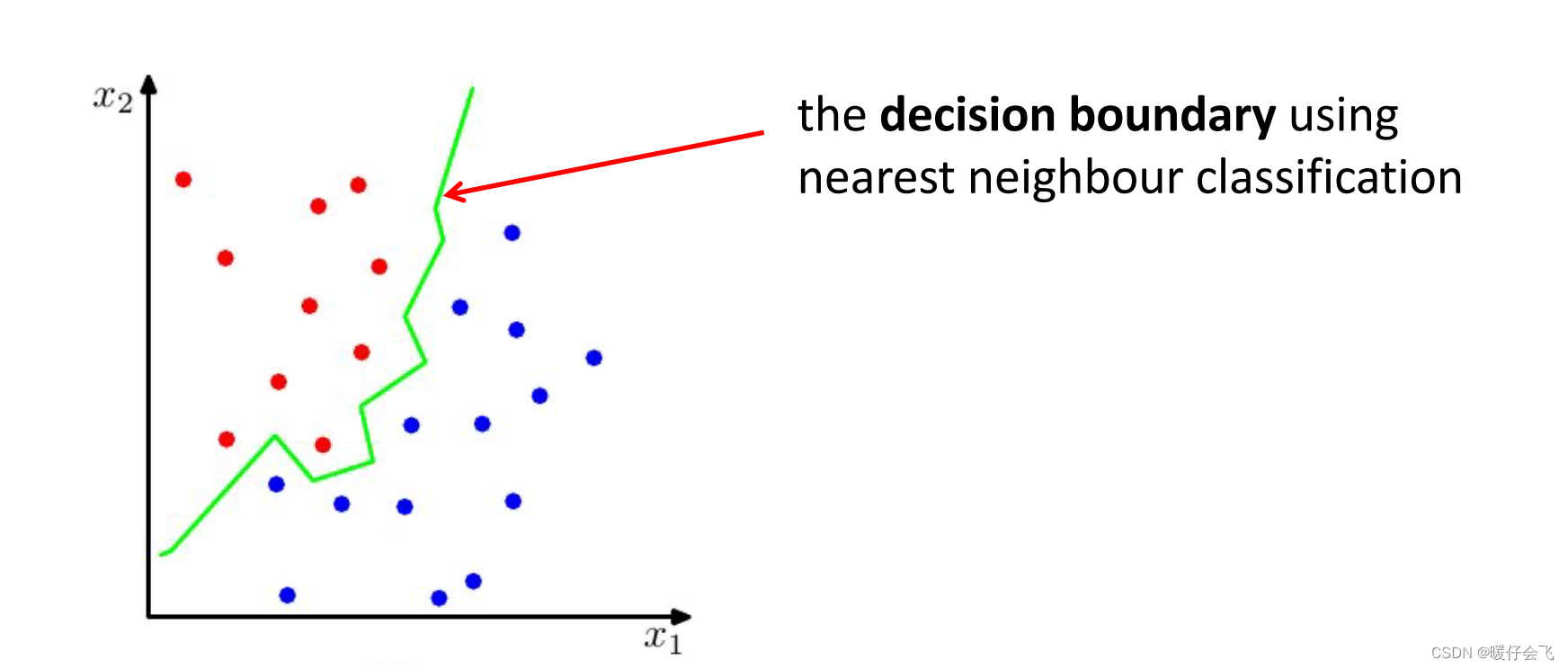
K最近邻(K-Nearest Neighbor) 算法(KNN)
- 最近邻是通过找最近的一个带标签的训练样本 y y y,把 y y y 的标签当做自己的预测标签,将一个邻居扩展到 k k k 个邻居,也就是通过 k k k 个训练样本的标签来决定当前这个预测样本的标签,这样的算法叫 K 最近邻
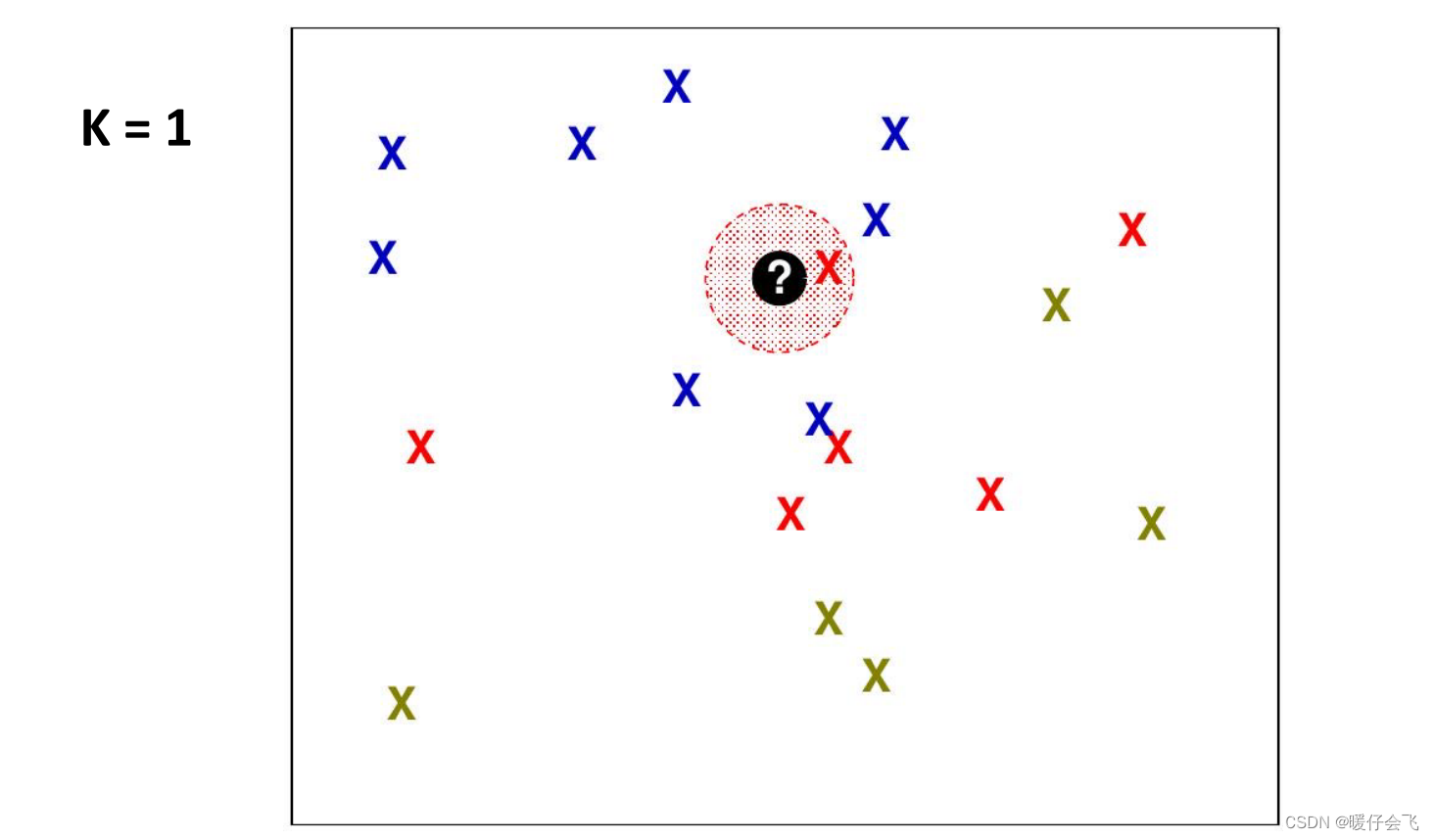
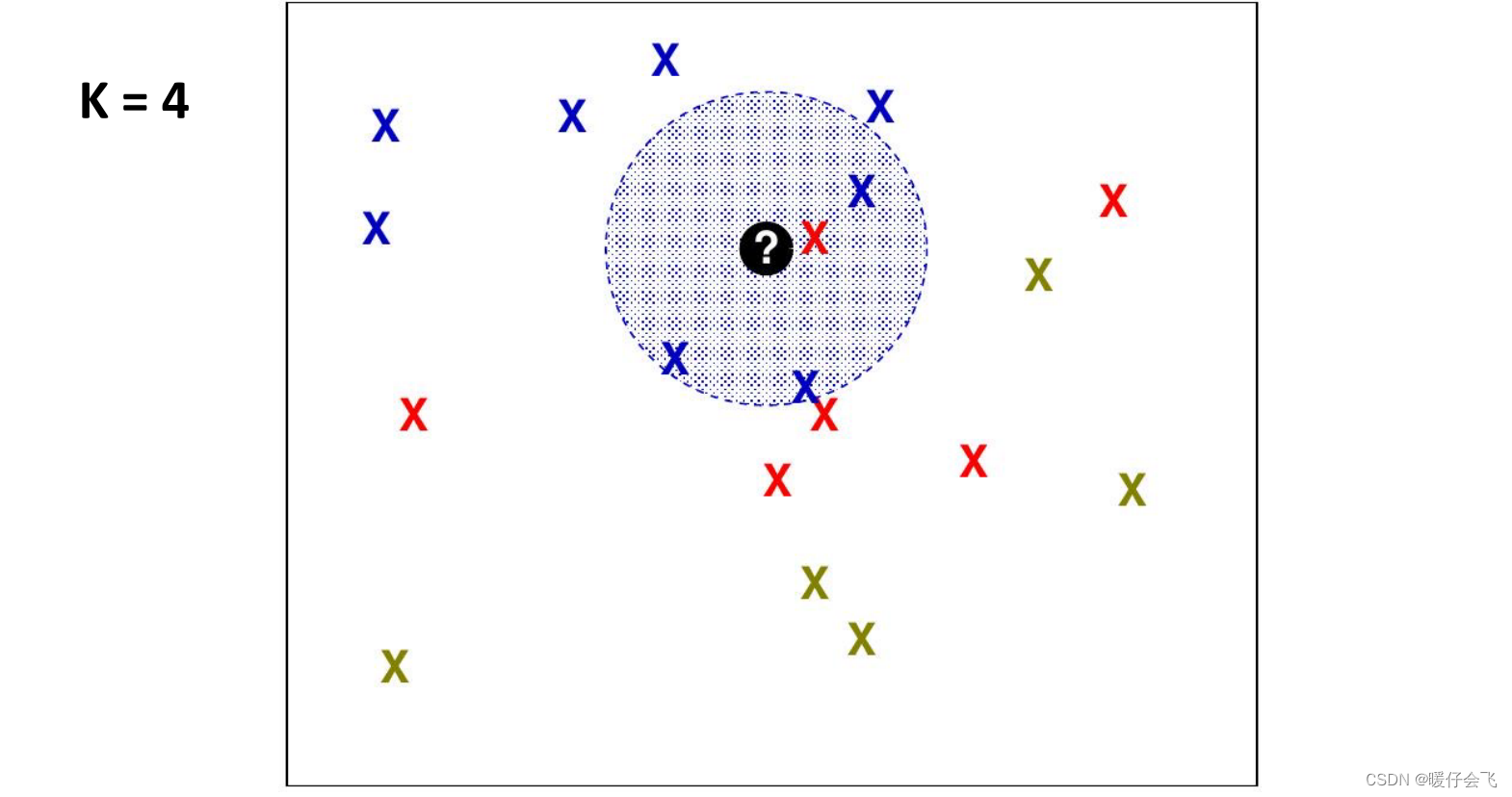
如何选择 K
- 不同的 K 会导致算法的表现差异很大
- K值越小,由于噪声(过拟合),性能越低,泛化能力差
- 当 K 很大的时候 K值越大,分类器性能越趋向于 zero-R 的性能; 因为zero-R 其实可以看成将所有的样本数 N N N 一起考虑的 N N N-最近邻
- 一般来说,对训练数据进行试错是得到合适 K 的唯一方法
- 我们需要考虑数据点的密度
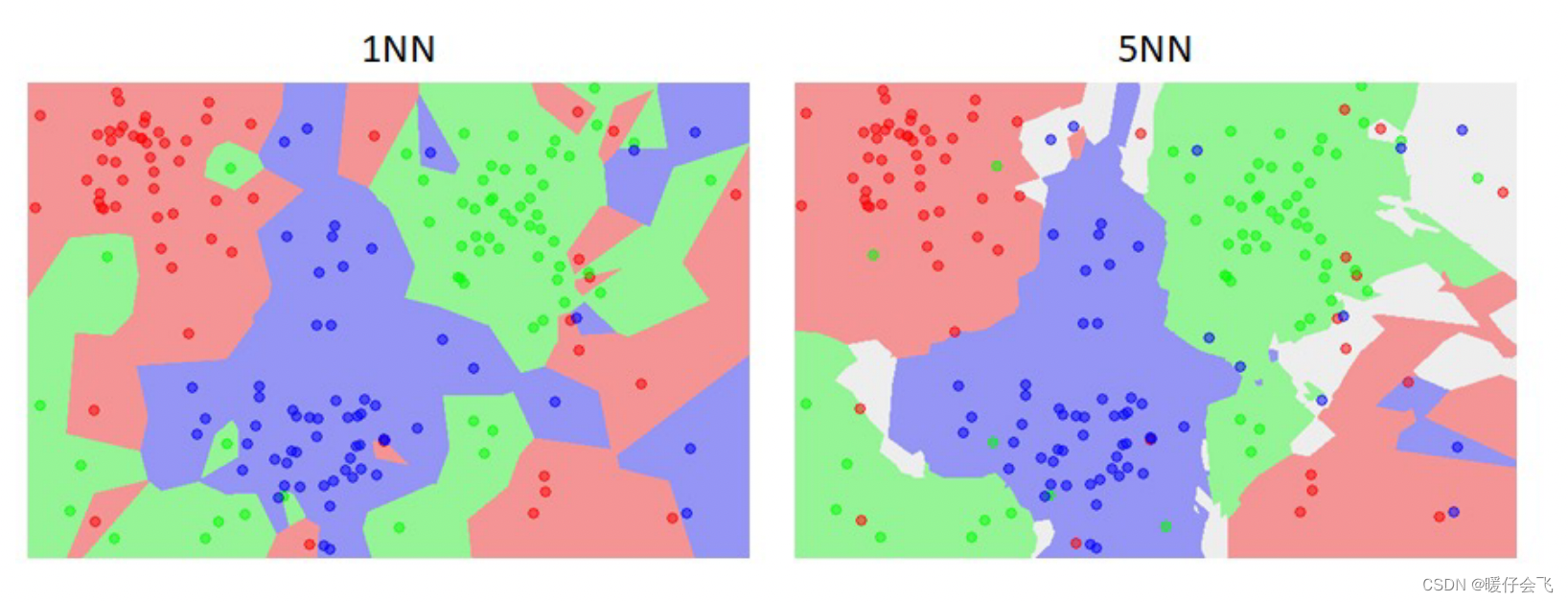
打破平局
- 一定会出现一种情况,假设是 1-最近邻,但在当前需要预测样本
x
x
x 的周围恰好有两个标签不同的样本
d
d
d,
h
h
h距离
x
x
x 完全相同

- 打破平局的方式有 3 种:
- 随机选一个
- 选哪个具有更高 先验概率 的样本:例如 d d d 的类别标签是 0 0 0, h h h 的类别标签是 1 1 1,而在整体的训练集的样本分布中,标签为 0 0 0 的样本占了 60 % 60\% 60%, 1 1 1 的样本占了 40 % 40\% 40% ,这时候以 0 0 0 为标签的样本的先验概率就是 0.6 0.6 0.6 所以这时候 x x x 的标签为 0 0 0
- 将当前的 K-NN 增加到 (K+1)-NN
加权 KNN(Weighted KNN)
-
假设在这种情境中,对于一个样本 x x x 周围有多个样本点,如果按照传统的 KNN 就会判定 x x x 的标签和蓝色的样本一样。但明明有一个红色的样本点离这个 x x x 比其他的所有蓝色样本点都更近,这样的情景我们应该怎么处理呢?
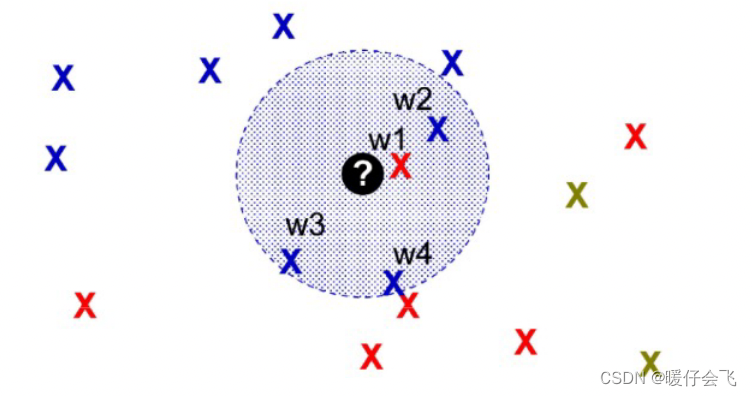
-
给数量和距离都分配一定的权重,最后得到的加权值比较大的样本类作为 x x x 的标签。
-
加权 KNN 使用的加权策略有以下常用的三种:
平等权重(Equal weight)
- 这种方式就是传统的 KNN,即
x
x
x 周围的每个样本点权重都一样,哪个类标签的样本数多就把
x
x
x 分为哪一类。

距离倒数(Inverse distance)
- 每个 x x x 周围的样本 { x j ∣ j ∈ K } \{x_j|j\in K\} {xj∣j∈K},他们与 x x x 之间的距离表示为 d j d_j dj,那么他们的权重分别是: w j = 1 d j + ϵ w_j=\frac{1}{d_j+\epsilon} wj=dj+ϵ1
- 其中 ϵ \epsilon ϵ 是一个非零但是极小的值,为了避免 w j w_j wj 计算过程中出现了 除 0 问题
- 这样导致的问题就是:离 x x x 近到一定程度的样本的倒数会非常大,大到哪怕其他类在附近的样本很多也可以忽略不计

缩放的距离倒数(Inverse linear distance)
w j = d m a x − d j d m a x − d m i n w_j=\frac{d_{max}-d_j}{d_{max}-d_{min}} wj=dmax−dmindmax−dj
- 这里的 d m a x , d m i n d_{max}, d_{min} dmax,dmin 分别是 x x x 周围的点距离 x x x 的最大值和最小值。
- 通过这种放缩方式可以保证没有非常大的值出现。

不同加权 KNN 示例

KNN 的复杂度分析
- 因为这是一种 instance-based(memory-based)的计算方式,因此需要非常暴力地对所有的样本同时加载到内存中进行计算。
- 对于一个包含 N N N 个样本,每个样本 D D D 个特征的数据集,这种算法的复杂度为 O ( D N ) O(DN) O(DN)
- 对于规模较小的数据集,这种方法效果很好
- 但对于大数据集,几乎不考虑这种方法
KNN 与 Naive Bayes / Decision Tree 的比较
- KNN 是一种非常 lazy 的算法,因为它不存在训练,所有的操作都在测试阶段完成,所以 KNN 不存在需要训练的参数
- 给定一个 C C C 个类别, D D D 个不同特征的数据集,对于一个 test 样本,NB 需要的计算时间为 O ( C D ) O(CD) O(CD),而 DT 只需要 O ( D ) O(D) O(D)
KNN 优缺点
优点
- 简单,基于样本,不需要建立模型
- 可以产生很灵活的决策边界
- 可以随时增加新的训练或者测试样本而不用重新生成模型

缺点
- 需要规划一个很好的距离函数才能最大发挥算法的性能
- K 值需要自己设定
- 所有的计算都发生在预测阶段,不可能预先训练模型并保存使用
- 容易受到噪音干扰,在高维数据上很难应用


















 6888
6888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











