







RoBERTa是BERT的改进版,在很多论文中都用二者做基础预训练模型来对比性能,一般来说都是RoBERTa表现要更好一些。那么RoBERTa具体在BERT基础上改进了什么?
论文原文链接:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ,
RoBERTa:A Robustly Optimized BERT Pretraining Approach。
RoBERTa论文中 Section 4 Training Procedure Analysis中讨论了一些改进的措施,包含以下四个方面:
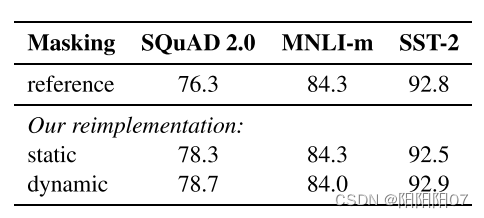
1. Static vs. Dynamic Masking
也就是将BERT的静态Masking改为动态Masking。
最初的BERT在数据预处理的时候做了一次性的掩码,从而产生另一个静态掩码。具体来说,BERT对每一个序列随机选择15%的Tokens替换成[MASK],为了消除与下游任务的不匹配,还对这15%的Tokens进行(1)80%替换成[MASK];(2)10%不变;(3)10%替换成其他词。但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了,所以是一种静态的Masking策略。
而RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking。
实验效果来看,只改变mask策略是有一定提升的:
2. Model Input Format and Next Sentence Prediction
即去掉NSP任务,将句子输入换成每次输入连续的多个句子,直到最大长度512(可以跨文章),这种策略叫FULL - SENTENCES。
在原始的BERT中,为了捕捉句子级的信息,采用Next Sentence Prediction的训练任务,输入两个句子A和B,预测句子B是否是A的下一个句子。具体来说,输入的训练样例中,50%的情况B是A的下一个句子(IsNext),另外50%随机替换成预料中其他句子(NotNext)。
而RoBERTa提出几种新的训练模式:
SEGMENT-PAIR+NSP
遵循原本BERT的上下句的输入格式,但是原本单个句子用多个句子代替,可以理解为文档级的上下句预测,总长度不超过512.
SENTENCE-PAIR+NSP
每个输入包含一对句子,可能是一个文档的连续部分,可能是来自不同文档。由于输入长度明显短于512,为了和上个策略保持一致,增大了batch size。
FULL-SENTENCES
每个输入都包含从一个或多个文档中连续采样的完整句子,因此总长度最多为512个标记,可能是跨文档的。在这种策略下,去掉了NSP loss。
DOC-SENTENCES
输入的构造与FULL-SENTENCE类似,只是它们不能跨越文档边界。当长度小于512时,我们动态增大batch size,以保持与FULL-SENTENCES一样的token总数。在这种策略下,也去掉了NSP loss。
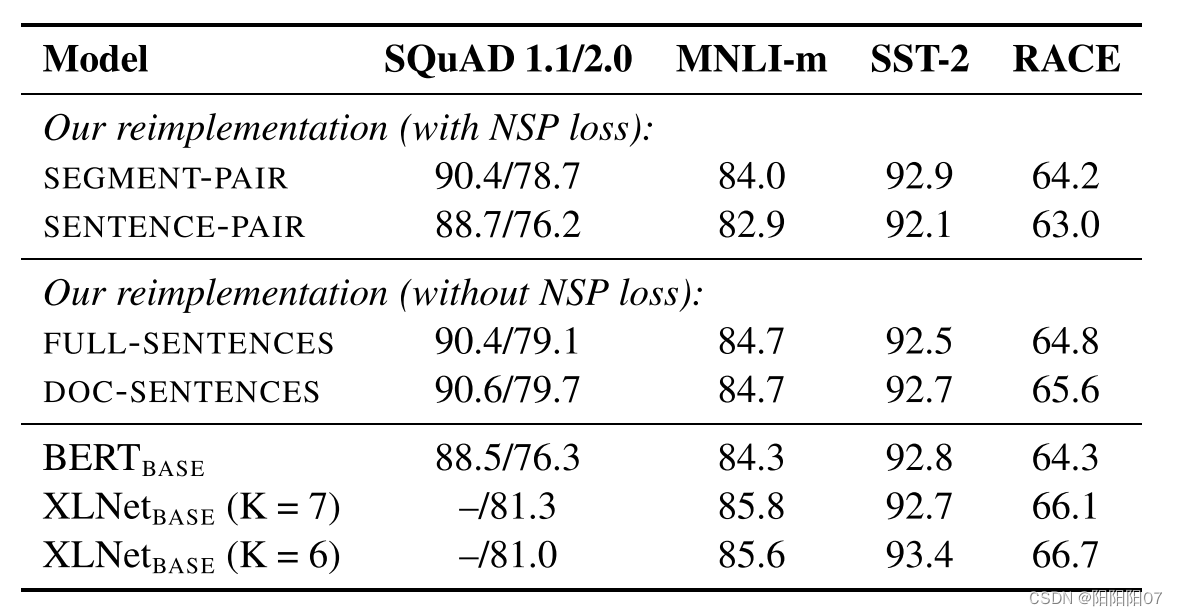 发现去掉NSP loss的两个策略明显更好,其中DOC-SENTENCES略好于FULL-SENTENCES,但是由于DOC-SENTENCES是动态调整batch size的,为了便于后续实验对比,后面的实验都采用FULL-SENTENCES策略。
发现去掉NSP loss的两个策略明显更好,其中DOC-SENTENCES略好于FULL-SENTENCES,但是由于DOC-SENTENCES是动态调整batch size的,为了便于后续实验对比,后面的实验都采用FULL-SENTENCES策略。
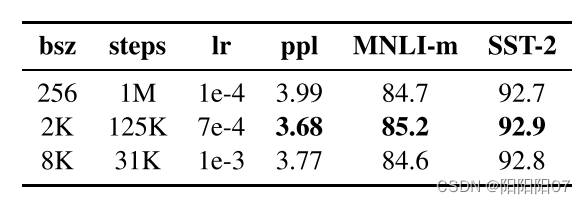
3. Training with large batches Past
也就是更大的batch size。
原始BERT用256个序列的batch size训练1M个step。通过分布式数据并行训练,大批量也更容易并行化,在后来的实验中,RoBERTa使用8K个序列的batch size进行训练。可以说是简单粗暴了。
还有更多的数据,RoBERTa使用的数据量为160G,BERT使用的数据量为13G。
4.Text Encoding
更大的字节级的BPE编码词表。
BERT用大小为30k的字符集BPE词汇表,而RoBERTa使用大小为50k的较大字节级BPE词汇表来训练。
实验
此外实验中,RoBERTa还研究了用于与训练的数据集,以及训练的次数。
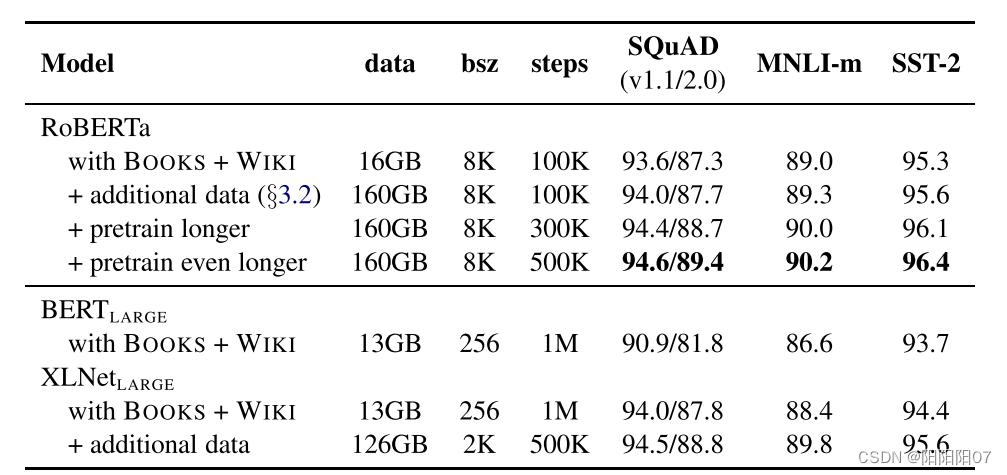 其实后面三点,即更大的batch size,更大的词表,更多的训练数据和训练时长可以总结为大力出奇迹!
其实后面三点,即更大的batch size,更大的词表,更多的训练数据和训练时长可以总结为大力出奇迹!
参考: 改进版的RoBERTa到底改进了什么?
如有错误欢迎指正!














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









