







【AAAI 2025】SegFace : Face Segmentation of Long-Tail Classes
论文:https://arxiv.org/abs/2412.08647
代码:https://github.com/Kartik-3004/SegFace
话不多说,直接看演示。今天分享的是AAAI 2025一篇名为SegFace论文的面部解析(人脸语义分割)模型的推理接口。把模型和数据预处理部分从代码仓库里面剥离出来了。需要自取。
演示
| 输入 | 输出 | 真值 |
|---|---|---|
 |  |  |
说明
本文分享的是SegFace在CelebAMask-HQ数据集上用ConvNext(Base)架构训练的模型的一键推理接口。
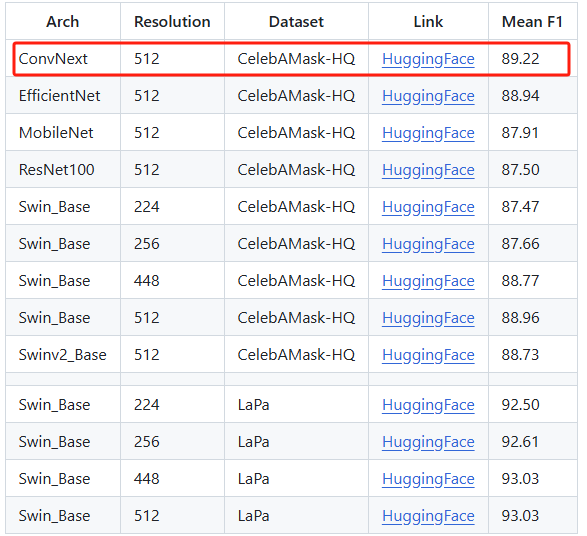
下方为模型输出的语义分割的结果索引(从0开始,最大18,共19类)对应的标签。
| Label | Full Name | Chinese Description | RGB | Color |
|---|---|---|---|---|
| background | Background | 背景 | (0, 0, 0) | █ |
| neck | Neck | 脖子 | (255, 153, 51) | █ |
| face | Face | 脸 | (204, 0, 0) | █ |
| cloth | Cloth | 衣服 | (0, 204, 0) | █ |
| lr | Left Ear | 左耳 | (102, 51, 0) | █ |
| rr | Right Ear | 右耳 | (255, 0, 0) | █ |
| lb | Left Eyebrow | 左眉毛 | (0, 255, 255) | █ |
| rb | Right Eyebrow | 右眉毛 | (255, 204, 204) | █ |
| le | Left Eye | 左眼 | (51, 51, 255) | █ |
| re | Right Eye | 右眼 | (204, 0, 204) | █ |
| nose | Nose | 鼻子 | (76, 153, 0) | █ |
| imouth | Inner Mouth | 嘴巴内部 | (102, 204, 0) | █ |
| llip | Lower Lip | 下唇 | (0, 0, 153) | █ |
| ulip | Upper Lip | 上唇 | (255, 255, 0) | █ |
| hair | Hair | 头发 | (0, 0, 204) | █ |
| eyeg | Eyeglass | 眼镜 | (204, 204, 0) | █ |
| hat | Hat | 帽子 | (255, 51, 153) | █ |
| earr | Earring | 耳环 | (0, 204, 204) | █ |
| neckl | Necklace | 项链 | (0, 51, 0) | █ |
代码
运行需要安装如下环境:
pip install torch torchvision opencv-python
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import cv2
import torch
import torch.nn.functional as F
import torch.nn as nn
import torch
from torch import Tensor, nn
import math
from typing import Tuple, Type
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Any, Optional, Tuple, Type
from torchvision.models import (
convnext_base,
convnext_small,
convnext_tiny,
swin_b,
swin_v2_b,
swin_v2_s,
swin_v2_t,
mobilenet_v3_large,
efficientnet_v2_m,
)
import numpy as np
import torchvision
import torchvision.models as models
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
if self.sigmoid_output:
x = F.sigmoid(x)
return x
class FaceDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: 256,
transformer: nn.Module,
activation: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.transformer_dim = transformer_dim
self.transformer = transformer
self.background_token = nn.Embedding(1, transformer_dim)
self.neck_token = nn.Embedding(1, transformer_dim)
self.face_token = nn.Embedding(1, transformer_dim)
self.cloth_token = nn.Embedding(1, transformer_dim)
self.rightear_token = nn.Embedding(1, transformer_dim)
self.leftear_token = nn.Embedding(1, transformer_dim)
self.rightbro_token = nn.Embedding(1, transformer_dim)
self.leftbro_token = nn.Embedding(1, transformer_dim)
self.righteye_token = nn.Embedding(1, transformer_dim)
self.lefteye_token = nn.Embedding(1, transformer_dim)
self.nose_token = nn.Embedding(1, transformer_dim)
self.innermouth_token = nn.Embedding(1, transformer_dim)
self.lowerlip_token = nn.Embedding(1, transformer_dim)
self.upperlip_token = nn.Embedding(1, transformer_dim)
self.hair_token = nn.Embedding(1, transformer_dim)
self.glass_token = nn.Embedding(1, transformer_dim)
self.hat_token = nn.Embedding(1, transformer_dim)
self.earring_token = nn.Embedding(1, transformer_dim)
self.necklace_token = nn.Embedding(1, transformer_dim)
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
),
activation(),
)
self.output_hypernetwork_mlps = MLP(
transformer_dim, transformer_dim, transformer_dim // 8, 3
)
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
image_embeddings - torch.Size([1, 256, 128, 128])
image_pe - torch.Size([1, 256, 128, 128])
"""
output_tokens = torch.cat(
[
self.background_token.weight,
self.neck_token.weight,
self.face_token.weight,
self.cloth_token.weight,
self.rightear_token.weight,
self.leftear_token.weight,
self.rightbro_token.weight,
self.leftbro_token.weight,
self.righteye_token.weight,
self.lefteye_token.weight,
self.nose_token.weight,
self.innermouth_token.weight,
self.lowerlip_token.weight,
self.upperlip_token.weight,
self.hair_token.weight,
self.glass_token.weight,
self.hat_token.weight,
self.earring_token.weight,
self.necklace_token.weight,
],
dim=0,
)
tokens = output_tokens.unsqueeze(0).expand(
image_embeddings.size(0), -1, -1
) ##### torch.Size([4, 11, 256])
src = image_embeddings ##### torch.Size([4, 256, 128, 128])
pos_src = image_pe.expand(image_embeddings.size(0), -1, -1, -1)
b, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(
src, pos_src, tokens
) ####### hs - torch.Size([BS, 11, 256]), src - torch.Size([BS, 16348, 256])
mask_token_out = hs[:, :, :]
src = src.transpose(1, 2).view(b, c, h, w) ##### torch.Size([4, 256, 128, 128])
upscaled_embedding = self.output_upscaling(
src
) ##### torch.Size([4, 32, 512, 512])
hyper_in = self.output_hypernetwork_mlps(
mask_token_out
) ##### torch.Size([1, 11, 32])
b, c, h, w = upscaled_embedding.shape
seg_output = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(
b, -1, h, w
) ##### torch.Size([1, 11, 512, 512])
return seg_output
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C
class TwoWayTransformer(nn.Module):
def __init__(
self,
depth: int,
embedding_dim: int,
num_heads: int,
mlp_dim: int,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
) -> None:
"""
A transformer decoder that attends to an input image using
queries whose positional embedding is supplied.
Args:
depth (int): number of layers in the transformer
embedding_dim (int): the channel dimension for the input embeddings
num_heads (int): the number of heads for multihead attention. Must
divide embedding_dim
mlp_dim (int): the channel dimension internal to the MLP block
activation (nn.Module): the activation to use in the MLP block
"""
super().__init__()
self.depth = depth
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.mlp_dim = mlp_dim
self.layers = nn.ModuleList()
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_dim=mlp_dim,
activation=activation,
attention_downsample_rate=attention_downsample_rate,
skip_first_layer_pe=(i == 0),
)
)
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor,
image_pe: Tensor,
point_embedding: Tensor,
) -> Tuple[Tensor, Tensor]:
"""
Args:
image_embedding (torch.Tensor): image to attend to. Should be shape
B x embedding_dim x h x w for any h and w.
image_pe (torch.Tensor): the positional encoding to add to the image. Must
have the same shape as image_embedding.
point_embedding (torch.Tensor): the embedding to add to the query points.
Must have shape B x N_points x embedding_dim for any N_points.
Returns:
torch.Tensor: the processed point_embedding
torch.Tensor: the processed image_embedding
"""
# BxCxHxW -> BxHWxC == B x N_image_tokens x C
bs, c, h, w = image_embedding.shape
image_embedding = image_embedding.flatten(2).permute(0, 2, 1)
image_pe = image_pe.flatten(2).permute(0, 2, 1)
# Prepare queries
queries = point_embedding
keys = image_embedding
# Apply transformer blocks and final layernorm
for layer in self.layers:
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding,
key_pe=image_pe,
)
# Apply the final attention layer from the points to the image
q = queries + point_embedding
k = keys + image_pe
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm_final_attn(queries)
return queries, keys
class MLPBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
mlp_dim: int,
act: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
self.act = act()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lin2(self.act(self.lin1(x)))
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
A transformer block with four layers: (1) self-attention of sparse
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
block on sparse inputs, and (4) cross attention of dense inputs to sparse
inputs.
Arguments:
embedding_dim (int): the channel dimension of the embeddings
num_heads (int): the number of heads in the attention layers
mlp_dim (int): the hidden dimension of the mlp block
activation (nn.Module): the activation of the mlp block
skip_first_layer_pe (bool): skip the PE on the first layer
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
class Attention(nn.Module):
"""
An attention layer that allows for downscaling the size of the embedding
after projection to queries, keys, and values.
"""
def __init__(
self,
embedding_dim: int,
num_heads: int,
downsample_rate: int = 1,
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate
self.num_heads = num_heads
assert (
self.internal_dim % num_heads == 0
), "num_heads must divide embedding_dim."
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2)
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# Input projections
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# Separate into heads
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# Attention
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
attn = attn / math.sqrt(c_per_head)
attn = torch.softmax(attn, dim=-1)
# Get output
out = attn @ v
out = self._recombine_heads(out)
out = self.out_proj(out)
return out
class SegfaceMLP(nn.Module):
"""
Linear Embedding.
"""
def __init__(self, input_dim):
super().__init__()
self.proj = nn.Linear(input_dim, 256)
def forward(self, hidden_states: torch.Tensor):
hidden_states = hidden_states.flatten(2).transpose(1, 2)
hidden_states = self.proj(hidden_states)
return hidden_states
class SegFaceCeleb(nn.Module):
def __init__(self, input_resolution, model):
super(SegFaceCeleb, self).__init__()
self.input_resolution = input_resolution
self.model = model
if self.model == "swin_base":
swin_v2 = swin_b(weights="IMAGENET1K_V1")
self.backbone = torch.nn.Sequential(*(list(swin_v2.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "swinv2_base":
swin_v2 = swin_v2_b(weights="IMAGENET1K_V1")
self.backbone = torch.nn.Sequential(*(list(swin_v2.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "swinv2_small":
swin_v2 = swin_v2_s(weights="IMAGENET1K_V1")
self.backbone = torch.nn.Sequential(*(list(swin_v2.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "swinv2_tiny":
swin_v2 = swin_v2_t(weights="IMAGENET1K_V1")
self.backbone = torch.nn.Sequential(*(list(swin_v2.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "convnext_base":
convnext = convnext_base(pretrained=False)
self.backbone = torch.nn.Sequential(*(list(convnext.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "convnext_small":
convnext = convnext_small(pretrained=True)
self.backbone = torch.nn.Sequential(*(list(convnext.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "convnext_tiny":
convnext = convnext_tiny(pretrained=True)
self.backbone = torch.nn.Sequential(*(list(convnext.children())[:-1]))
self.target_layer_names = ["0.1", "0.3", "0.5", "0.7"]
self.multi_scale_features = []
if self.model == "resnet":
resnet101 = models.resnet101(pretrained=True)
self.backbone = torch.nn.Sequential(*(list(resnet101.children())[:-1]))
self.target_layer_names = ["4", "5", "6", "7"]
self.multi_scale_features = []
if self.model == "mobilenet":
mobilenet = mobilenet_v3_large(pretrained=True).features
self.backbone = mobilenet
self.target_layer_names = ["3", "6", "12", "16"]
self.multi_scale_features = []
if self.model == "efficientnet":
efficientnet = efficientnet_v2_m(pretrained=True).features
self.backbone = efficientnet
self.target_layer_names = ["2", "3", "5", "8"]
self.multi_scale_features = []
embed_dim = 1024
out_chans = 256
self.pe_layer = PositionEmbeddingRandom(out_chans // 2)
for name, module in self.backbone.named_modules():
if name in self.target_layer_names:
module.register_forward_hook(self.save_features_hook(name))
self.face_decoder = FaceDecoder(
transformer_dim=256,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=256,
mlp_dim=2048,
num_heads=8,
),
)
num_encoder_blocks = 4
if self.model in ["swin_base", "swinv2_base", "convnext_base"]:
hidden_sizes = [128, 256, 512, 1024] ### Swin Base and ConvNext Base
if self.model in ["resnet"]:
hidden_sizes = [256, 512, 1024, 2048] ### ResNet
if self.model in [
"swinv2_small",
"swinv2_tiny",
"convnext_small",
"convnext_tiny",
]:
hidden_sizes = [
96,
192,
384,
768,
] ### Swin Small/Tiny and ConvNext Small/Tiny
if self.model in ["mobilenet"]:
hidden_sizes = [24, 40, 112, 960] ### MobileNet
if self.model in ["efficientnet"]:
hidden_sizes = [48, 80, 176, 1280] ### EfficientNet
decoder_hidden_size = 256
mlps = []
for i in range(num_encoder_blocks):
mlp = SegfaceMLP(input_dim=hidden_sizes[i])
mlps.append(mlp)
self.linear_c = nn.ModuleList(mlps)
# The following 3 layers implement the ConvModule of the original implementation
self.linear_fuse = nn.Conv2d(
in_channels=decoder_hidden_size * num_encoder_blocks,
out_channels=decoder_hidden_size,
kernel_size=1,
bias=False,
)
def save_features_hook(self, name):
def hook(module, input, output):
if self.model in [
"swin_base",
"swinv2_base",
"swinv2_small",
"swinv2_tiny",
]:
self.multi_scale_features.append(
output.permute(0, 3, 1, 2).contiguous()
) ### Swin, Swinv2
if self.model in [
"convnext_base",
"convnext_small",
"convnext_tiny",
"mobilenet",
"efficientnet",
]:
self.multi_scale_features.append(
output
) ### ConvNext, ResNet, EfficientNet, MobileNet
return hook
def forward(self, x):
self.multi_scale_features.clear()
_, _, h, w = x.shape
features = self.backbone(x).squeeze()
batch_size = self.multi_scale_features[-1].shape[0]
all_hidden_states = ()
for encoder_hidden_state, mlp in zip(self.multi_scale_features, self.linear_c):
height, width = encoder_hidden_state.shape[2], encoder_hidden_state.shape[3]
encoder_hidden_state = mlp(encoder_hidden_state)
encoder_hidden_state = encoder_hidden_state.permute(0, 2, 1)
encoder_hidden_state = encoder_hidden_state.reshape(
batch_size, -1, height, width
)
# upsample
encoder_hidden_state = nn.functional.interpolate(
encoder_hidden_state,
size=self.multi_scale_features[0].size()[2:],
mode="bilinear",
align_corners=False,
)
all_hidden_states += (encoder_hidden_state,)
fused_states = self.linear_fuse(
torch.cat(all_hidden_states[::-1], dim=1)
) #### torch.Size([BS, 256, 128, 128])
image_pe = self.pe_layer(
(fused_states.shape[2], fused_states.shape[3])
).unsqueeze(0)
seg_output = self.face_decoder(image_embeddings=fused_states, image_pe=image_pe)
return seg_output
def save_result(logits, output_path):
palette = np.array(
[
[0, 0, 0],
[255, 153, 51],
[204, 0, 0],
[0, 204, 0],
[102, 51, 0],
[255, 0, 0],
[0, 255, 255],
[255, 204, 204],
[51, 51, 255],
[204, 0, 204],
[76, 153, 0],
[102, 204, 0],
[0, 0, 153],
[255, 255, 0],
[0, 0, 204],
[204, 204, 0],
[255, 51, 153],
[0, 204, 204],
[0, 51, 0],
],
dtype=np.uint8,
)
segmentation_image = Image.fromarray(
logits.squeeze(0).cpu().byte().numpy(), mode="P"
) # 使用 P 模式
# 设置调色板
segmentation_image.putpalette(palette.flatten()) # 调色板必须是扁平数组
# 保存图像
segmentation_image.save(output_path)
def inference(input_path, output_path):
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SegFaceCeleb(512, "convnext_base").to(device)
checkpoint = torch.hub.load_state_dict_from_url("https://huggingface.co/kartiknarayan/SegFace/resolve/main/convnext_celeba_512/model_299.pt")
model.load_state_dict(checkpoint["state_dict_backbone"])
model.eval()
image = cv2.imread(input_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = image.resize((512, 512), Image.BICUBIC)
transforms_image_test = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
image = transforms_image_test(image)
logits = model(image.unsqueeze(0).cuda())
logits = logits.argmax(dim=1)
save_result(logits, output_path)
if __name__ == "__main__":
inference(input_path="1.jpg", output_path="output.png")


















 5334
5334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











