







Self-RAG研究学习记录
论文发布的太新太新了,找了小半天也没有相关资料和应用实践,只能啃啃论文,结合自己的理解,以作记录。
论文链接:https://arxiv.org/pdf/2310.11511.pdf
github: https://github.com/AkariAsai/self-rag.git
Self-RAG(Self-Reflective Retrieval-Augmented Generation):自反思的检索增强生成方法。 SELF-RAG 是一种训练任意语言模型(LM)的方法,使其在推理阶段具有可控性。通过让 LM 反思自己的生成过程。
SELF-RAG 使得模型在多种任务上表现优越,如开放领域问答、推理和事实验证。实验结果显示,Self-RAG 在这些任务上的表现优于现有的大型语言模型(如 ChatGPT)以及检索增强模型(如检索增强的 Llama2-chat)。尤其是在事实性和引用准确性方面,Self-RAG 具有显著的提升。
我们目前使用的chatchat架构,以及目前市面上常见的AI知识检索解决方案,都遵循着共通的范式:query+context→LLM。
query 表示用户的输入,context 表示从向量库中检索获得的信息,然后共同输入到 LLM 中,这是一种检索前置的被动的增强方式。
chatchat存在的问题
- 检索效果依赖 embedding 和检索算法,目前可能检索到相似但是无关信息,反而对输出有负面影响;如:
办公电话夜间开机作业怎么办,会和机房电脑夜间开机怎么办进行匹配 ; - 大模型如何利用检索到的信息仍是黑盒的,可能仍存在不准确(甚至生成的文本与检索信息相冲突);如:回答完问题后,会输出 “根据已知信息,无法回答该问题”;
- 对所有任务都无差别强行检索 top_k 个文本片段,当有不相关文本片段被匹配出来时,会影响准确性;
Self-RAG方案理解
相较chatchat的检索前置被动的增强的方案,Self-RAG 是更加主动和智能的实现方式,真正应用上了AI大模型的能力。
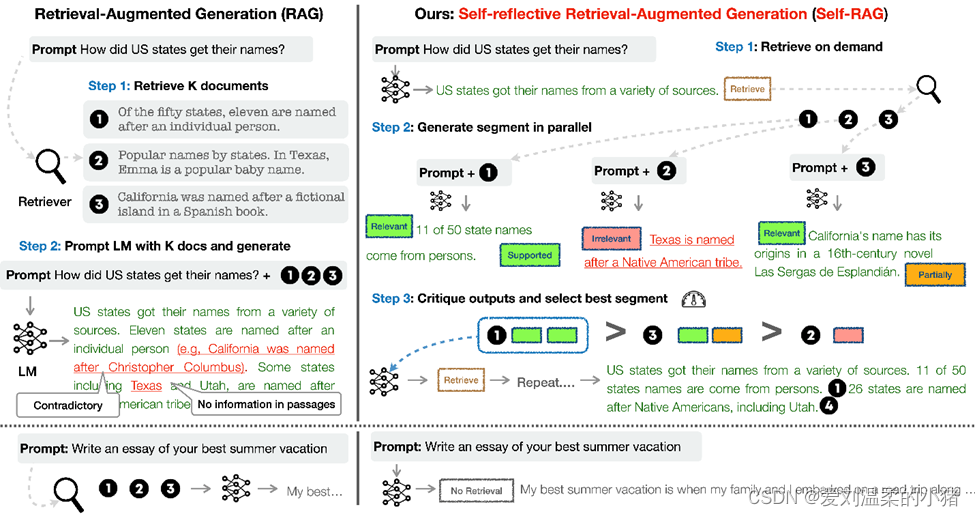
SELF-RAG往语言模型的词表中引入了4种新类型的反思令牌,分别是Retriver, IsRel, IsSup, IsUse,对应四种不同的子任务,如下图:

以第一个任务Retriever为例, 该任务会判断当前问题下是否需要检索模块支持,对应反思令牌有yes,no跟continue,分别对应不同选择。通过让语言模型生成对应的反思令牌,使得语言模型具备判断是否需要检索以及评判生成结果的能力。
这里值得注意的是,也可以主动由检索模块先来判断是否需要支持,然后把标签提前打好。官方给出的实例代码展示了**主动检索并打Retriever标签 **和 被动由模型识别去打Retriever标签。
x:代表问题; d:代表知识片段; y:代表模型根据知识片段生成的回答;
Retrieve任务:模型判断这段话或者这个问题结束后,需不需要去知识库里查询信息。
IsREL任务:检索出来的知识片段y,对我解决问题x有没有帮助。
IsSUP任务:我生成出来的回答y,能不能被知识片段d证明。
IsUSE任务:我生成的y,能不能解决x这个问题。
并且作者把很好的token,用加粗字体标识出来了,如:relevant、full supported、5。
Self-RAG主要运作如下:
- 判断是否需要额外检索事实性信息(Retrieve任务),仅当有需要时才召回相关知识片段;
- 并发组装每个召回的知识片段,产生prompt(就是用户的问题)+ 一个知识片段的prompt;
- 将组装好的各个prompt,再度并发投入到模型中,由模型进行判断用户问题和知识片段的相关性(IsREL任务),并且生成回答y。
- 模型生成y后,模型会判断y是否可以由知识片段支撑(IsSUP任务);
- 将IsREL任务和IsSUP任务的结果,依次加入到模型前边的输出y中,如果IsREL任务是Relevant,则继续进行评判y是否是有价值的回答(IsUse任务),原理是根据IsREL任务和IsSUP任务的结果标签对y进行打分5~1分,越大越趋近于问题的正确回答,如下图中的Relevant+Supported > Relevant+Partially > Irrelevant 。
- 将分数最高的知识片段和该知识片段的IsREL任务和IsSUP任务的反思字段结果,从新投入到大模型中,让模型进行再度理解和整合,输出正确答案。
整体原理如图右所示(图左是我们现在使用的chatchat的实现原理):
Self-RAG代码理解
从官方入门代码,结合上边的理论进行入手,官方代码如下:
from vllm import LLM 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5268
5268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









