






MHAF-YOLO|欢迎Star
个人主页 | 欢迎关注
这篇工作也花了挺多心血,中间打比赛找工作申博花了不少时间,还是陆陆续续完成了,虽然技术含量有限,但是工作量和性能还是杠杠的,今天太累了先不写全文解读了,水一篇YOLOv12改进,如何用MHAF-YOLO中的RepHMS模块,MAFPN,GHSK思想来改进YOLOv12,个人实验下来涨点挺明显的,希望为大家带来点帮助,万一涨点了呢hhh。
先介绍一下:MAFPN,我直接快速生成😂
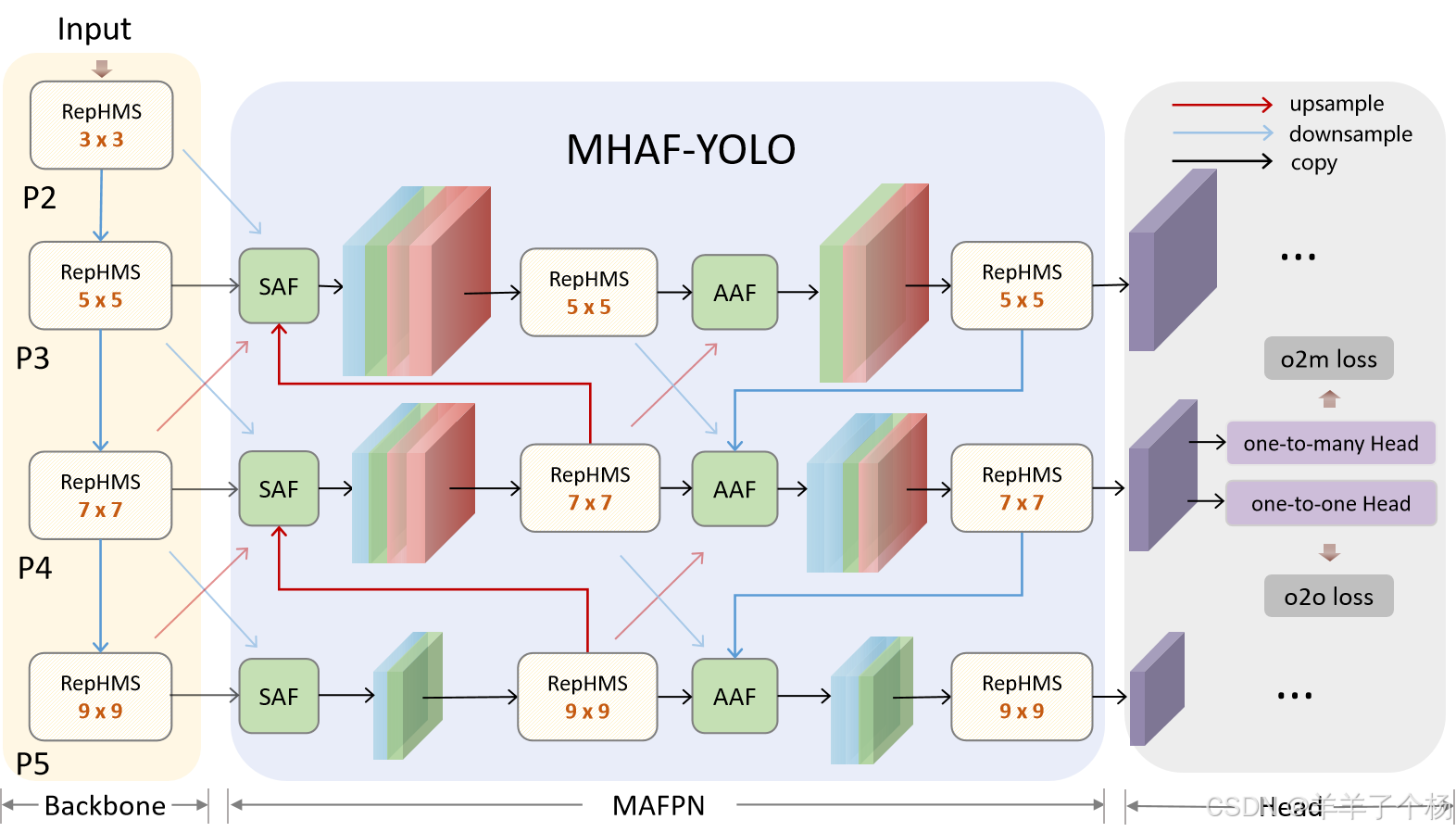
MAFPN核心包含两个关键模块:
-
SAF模块(浅层辅助特征模块)
- 作用:解决浅层特征噪声敏感性问题,提升小目标检测性能。
- 设计:将浅层特征分支引入深层网络,通过1×1卷积控制通道数,减少其在融合中的比例,同时保留关键空间细节。融合时结合上采样、下采样操作,稳定梯度传播并增强特征鲁棒性,避免浅层信息干扰深层语义学习。
-
AAF模块(自适应注意力融合模块)
- 作用:整合多尺度上下文信息,提升多尺度目标检测精度。
- 设计:从四类来源聚合特征——高/低分辨率浅层、同层输出及前序层级状态,通过1×1卷积参数化调节各分支权重,防止特征主导失衡。通道数均衡化设计确保多尺度特征平等参与,维持输出多样性。
整体优势:MAFPN通过SAF和AAF的协同,实现跨层特征的高效交互,兼顾浅层定位细节与深层语义抽象,显著提升多尺度目标检测效果。
再介绍一下其中用到的特征提取模块RepHMS,
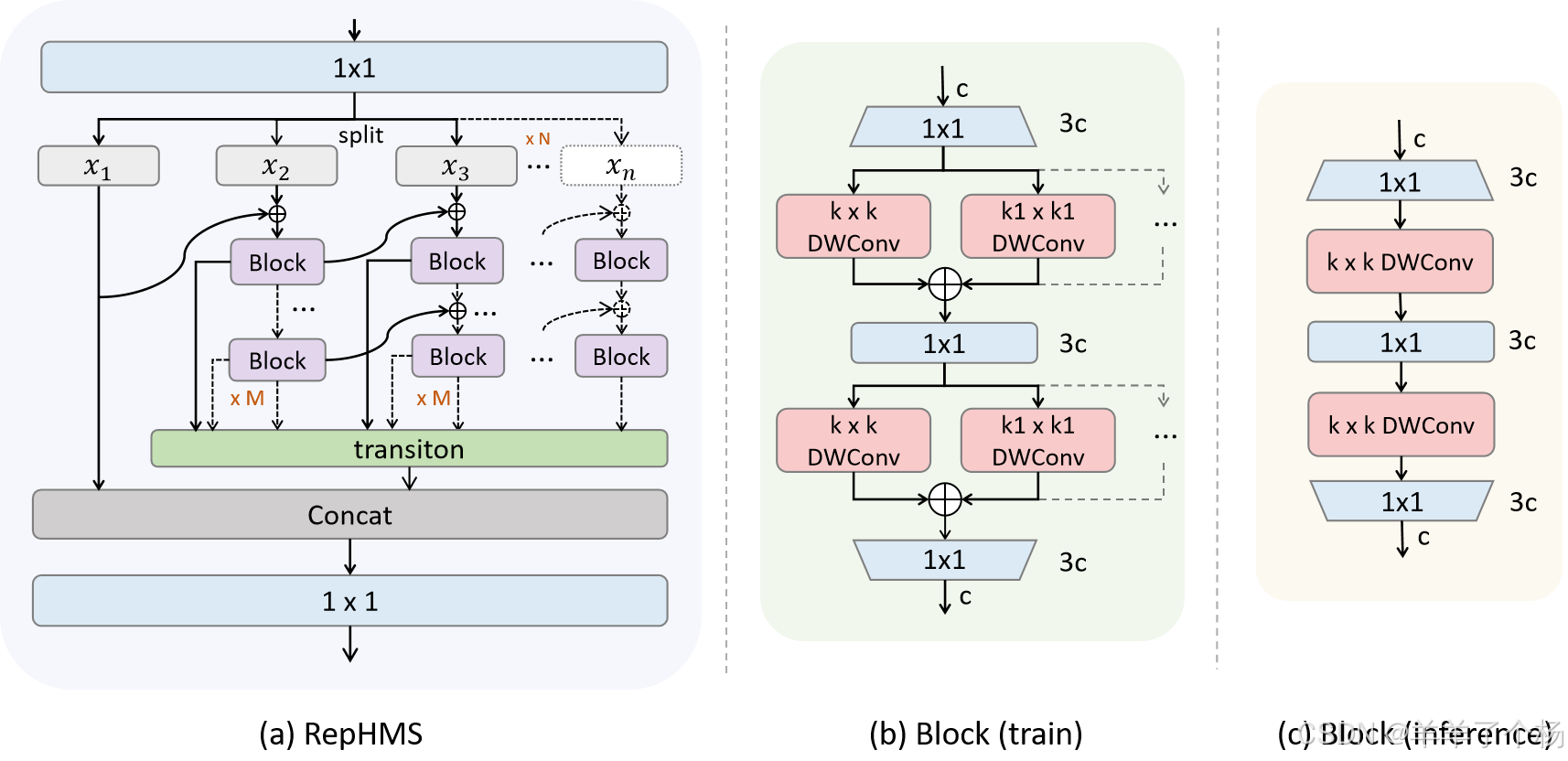
RepHMS模块(重参数化异构多分支模块)是MAFPN架构中的高效特征提取核心,通过多分支并行与参数融合实现多尺度特征优化,兼顾计算效率与检测性能。其设计要点如下:
-
多分支并行结构
- 输入处理:输入特征先经1×1卷积调整通道,随后Split为N条并行分支。
- 浅层保留:第一条分支直接保留原始浅层信息,确保定位细节不丢失。
- 深度增强:后续分支串联M个特征块(Block),每个块包含多尺度深度可分离卷积(DWConv)与重参数化操作,逐步深化特征抽象能力。
- 跨分支级联:后序分支接收前序分支的浅层特征,通过梯度流交互增强信息多样性。
-
动态特征整合
- 最终输出通过拼接(Concat)所有分支信息,再经1×1卷积压缩通道,融合多尺度表征。
- 参数M(块数量)和N(分支数)可灵活调节,平衡特征提取能力与计算开销。
-
RepHConv技术支撑
- 异构卷积核:每个Block内并行使用不同大小的DW卷积核(如3×3与7×7),兼顾大范围上下文捕捉与小目标细节保留。
- 训练-推理解耦:训练时多分支异构卷积并行学习;推理时通过重参数化合并为单一等效卷积,维持速度优势。
废话不多说,具体细节可以去原论文看看,直接进入改进环节,这次的目标是在YOLOv12中加入MAFPN,因为我自己做完了改进,还跑了实验,在COCO数据集上,YOLOv12n-MAFPN,在参数量不变的情况下,用了更少的训练轮次(600缩短到500),获得了1%的AP提升。
第一步,直接采用ultralytics官方库代码开始修改(吐槽一下YOLOv12官方库,使用到的flash attention经常安装不成功,且windows也不支持,u社的库支持得更好)
先看下YOLOv12n的结构:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# YOLO12 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo12
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo12n.yaml' will call yolo12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 272 layers, 2,602,288 parameters, 2,602,272 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 272 layers, 9,284,096 parameters, 9,284,080 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 292 layers, 20,199,168 parameters, 20,199,152 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 488 layers, 26,450,784 parameters, 26,450,768 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 488 layers, 59,210,784 parameters, 59,210,768 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
# YOLO12n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, A2C2f, [512, False, -1]] # 11
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, A2C2f, [256, False, -1]] # 14
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 2, A2C2f, [512, False, -1]] # 17
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)YOLOv12采用的是传统的PAFPN结构,并且可以看出文章提到的flash attention注意力机制仅仅用在了backbone区域,即A2C2f模块的超参数(A2C2f, [1024, True, 1]),直接第二个超参数为True,才会采用这个注意力机制,所以还有很大的优化空间。
再看下MHAF-YOLOn的结构图:
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [1, 0.25, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 1, Conv, [128, 3, 2]]
- [-1, 1, RepHMS, [128, 2, 1, 3, 3]]
- [-1, 1, Conv, [256, 3, 2]]
- [-1, 1, RepHMS, [256, 3, 1, 3, 5]]
- [-1, 1, SCDown, [512, 3, 2]]
- [-1, 1, RepHMS, [512, 3, 1, 3, 7]]
- [-1, 1, SCDown, [1024, 3, 2]]
- [-1, 1, RepHMS, [1024, 2, 1, 3, 9]]
- [-1, 1, SPPF, [1024, 5]]
- [-1, 1, PSA, [1024]]
head:
- [6, 1, AVG, []]
- [[-1, 10], 1, Concat, [1]]
- [-1, 1, RepHMS, [512, 2, 1, 3, 9]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [10, 1, nn.Upsample, [None, 2, "nearest"]]
- [4, 1, AVG, []]
- [[-1, 6, -2, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 7]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [6, 1, nn.Upsample, [None, 2, "nearest"]]
- [2, 1, AVG, []]
- [[-1, 4, -2, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 5]]
- [18, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, -2], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 5]]
- [-1, 1, Conv, [384, 3, 2]]
- [23, 1, AVG, []]
- [13, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-2, -1, 18, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 7]]
- [-1, 1, Conv, [384, 3, 2]]
- [18, 1, AVG, []]
- [[-2, -1, 13], 1, Concat, [1]]
- [-1, 1, RepHMS, [512, 2, 1, 3, 9]]
- [[26, 31, 35], 1, v10Detect, [nc]]2. 再把两者结合一下,直接把MHAF-YOLO的neck部分移到YOLOv12中,可以得到最终的文章,这边以YOLOv12n-MAFPN为例,如果是更大的基准模型,应该采用更大的MAFPN结构,
结构如下:
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 465 layers, 2,603,056 parameters, 2,603,040 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 465 layers, 9,285,632 parameters, 9,285,616 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 501 layers, 20,201,216 parameters, 20,201,200 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 831 layers, 26,454,880 parameters, 26,454,864 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 831 layers, 59,216,928 parameters, 59,216,912 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
# YOLO12n head
head:
- [6, 1, AVG, []]
- [[-1, 8], 1, Concat, [1]]
- [-1, 1, RepHMS, [512, 2, 1, 3, 9]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [8, 1, nn.Upsample, [None, 2, "nearest"]]
- [4, 1, AVG, []]
- [[-1, 6, -2, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 7]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [6, 1, nn.Upsample, [None, 2, "nearest"]]
- [2, 1, AVG, []]
- [[-1, 4, -2, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 5]]
- [16, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, -2], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 5]]
- [-1, 1, Conv, [384, 3, 2]]
- [21, 1, AVG, []]
- [11, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-2, -1, 16, -3], 1, Concat, [1]]
- [-1, 1, RepHMS, [384, 2, 1, 3, 7]]
- [-1, 1, Conv, [384, 3, 2]]
- [16, 1, AVG, []]
- [[-2, -1, 11], 1, Concat, [1]]
- [-1, 1, RepHMS, [512, 2, 1, 3, 9]]
- [[24, 29, 33], 1, Detect, [nc]] # Detect(P3, P4, P5)3. 接下来就是底层代码的移植了,先在ultralytics/nn/modules目录新建一个mafyolo.py的文件,用于加入代码,不对之前的文件产生影响:

# Ultralytics YOLO 🚀, AGPL-3.0 license
"""Block modules."""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from .conv import DWConv
__all__ = (
"RepHDW",
)
class Conv(nn.Module):
'''Normal Conv with SiLU activation'''
def __init__(self, in_channels, out_channels, kernel_size = 1, stride = 1, groups=1, bias=False):
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class AVG(nn.Module):
def __init__(self, down_n=2):
super().__init__()
self.avg_pool = nn.functional.adaptive_avg_pool2d
self.down_n = down_n
# self.output_size = np.array([H, W])
def forward(self, x):
B, C, H, W = x.shape
H = int(H / self.down_n)
W = int(W / self.down_n)
output_size = np.array([H, W])
x = self.avg_pool(x, output_size)
return x
class RepHDW(nn.Module):
def __init__(self, in_channels, out_channels, depth=1, shortcut = True, expansion = 0.5, kersize = 5,depth_expansion = 1,small_kersize = 3,use_depthwise = True):
super(RepHDW, self).__init__()
c1 = int(out_channels * expansion) * 2
c_ = int(out_channels * expansion)
self.c_ = c_
self.conv1 = Conv(in_channels, c1, 1, 1)
self.m = nn.ModuleList(DepthBottleneckUni(self.c_, self.c_, shortcut,kersize,depth_expansion,small_kersize,use_depthwise) for _ in range(depth))
self.conv2 = Conv(c_ * (depth+2), out_channels, 1, 1)
def forward(self,x):
x = self.conv1(x)
x_out = list(x.split((self.c_, self.c_), 1))
for conv in self.m:
y = conv(x_out[-1])
x_out.append(y)
y_out = torch.cat(x_out, axis=1)
y_out = self.conv2(y_out)
return y_out
class DepthBottleneckUni(nn.Module):
def __init__(self,
in_channels,
out_channels,
shortcut=True,
kersize = 5,
expansion_depth = 1,
small_kersize = 3,
use_depthwise=True):
super(DepthBottleneckUni, self).__init__()
mid_channel = int(in_channels * expansion_depth)
self.conv1 = Conv(in_channels, mid_channel, 1)
self.shortcut = shortcut
if use_depthwise:
self.conv2 = UniRepLKNetBlock(mid_channel, kernel_size=kersize)
self.act = nn.SiLU()
self.one_conv = Conv(mid_channel,out_channels,kernel_size = 1)
else:
self.conv2 = Conv(out_channels, out_channels, 3, 1)
def forward(self, x):
y = self.conv1(x)
y = self.act(self.conv2(y))
y = self.one_conv(y)
return y
class UniRepLKNetBlock(nn.Module):
def __init__(self,
dim,
kernel_size,
deploy=False,
attempt_use_lk_impl=True):
super().__init__()
if deploy:
print('------------------------------- Note: deploy mode')
if kernel_size == 0:
self.dwconv = nn.Identity()
elif kernel_size >= 3:
self.dwconv = DilatedReparamBlock(dim, kernel_size, deploy=deploy,
attempt_use_lk_impl=attempt_use_lk_impl)
else:
assert kernel_size in [3]
self.dwconv = get_conv2d_uni(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=deploy,
attempt_use_lk_impl=attempt_use_lk_impl)
if deploy or kernel_size == 0:
self.norm = nn.Identity()
else:
self.norm = get_bn(dim)
def forward(self, inputs):
out = self.norm(self.dwconv(inputs))
return out
def reparameterize(self):
if hasattr(self.dwconv, 'merge_dilated_branches'):
self.dwconv.merge_dilated_branches()
if hasattr(self.norm, 'running_var'):
std = (self.norm.running_var + self.norm.eps).sqrt()
if hasattr(self.dwconv, 'lk_origin'):
self.dwconv.lk_origin.weight.data *= (self.norm.weight / std).view(-1, 1, 1, 1)
self.dwconv.lk_origin.bias.data = self.norm.bias + (
self.dwconv.lk_origin.bias - self.norm.running_mean) * self.norm.weight / std
else:
conv = nn.Conv2d(self.dwconv.in_channels, self.dwconv.out_channels, self.dwconv.kernel_size,
self.dwconv.padding, self.dwconv.groups, bias=True)
conv.weight.data = self.dwconv.weight * (self.norm.weight / std).view(-1, 1, 1, 1)
conv.bias.data = self.norm.bias - self.norm.running_mean * self.norm.weight / std
self.dwconv = conv
self.norm = nn.Identity()
class DilatedReparamBlock(nn.Module):
"""
Dilated Reparam Block proposed in UniRepLKNet (https://github.com/AILab-CVC/UniRepLKNet)
We assume the inputs to this block are (N, C, H, W)
"""
def __init__(self, channels, kernel_size, deploy, use_sync_bn=False, attempt_use_lk_impl=True):
super().__init__()
self.lk_origin = get_conv2d_uni(channels, channels, kernel_size, stride=1,
padding=kernel_size//2, dilation=1, groups=channels, bias=deploy,
)
self.attempt_use_lk_impl = attempt_use_lk_impl
if kernel_size == 17:
self.kernel_sizes = [5, 9, 3, 3, 3]
self.dilates = [1, 2, 4, 5, 7]
elif kernel_size == 15:
self.kernel_sizes = [5, 7, 3, 3, 3]
self.dilates = [1, 2, 3, 5, 7]
elif kernel_size == 13:
self.kernel_sizes = [5, 7, 3, 3, 3]
self.dilates = [1, 2, 3, 4, 5]
elif kernel_size == 11:
self.kernel_sizes = [5, 5, 3, 3, 3]
self.dilates = [1, 2, 3, 4, 5]
elif kernel_size == 9:
self.kernel_sizes = [7, 5, 3]
self.dilates = [1, 1, 1]
elif kernel_size == 7:
self.kernel_sizes = [5, 3]
self.dilates = [1, 1]
elif kernel_size == 5:
self.kernel_sizes = [3, 1]
self.dilates = [1, 1]
elif kernel_size == 3:
self.kernel_sizes = [3, 1]
self.dilates = [1, 1]
else:
raise ValueError('Dilated Reparam Block requires kernel_size >= 5')
if not deploy:
self.origin_bn = get_bn(channels)
for k, r in zip(self.kernel_sizes, self.dilates):
self.__setattr__('dil_conv_k{}_{}'.format(k, r),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=k, stride=1,
padding=(r * (k - 1) + 1) // 2, dilation=r, groups=channels,
bias=False))
self.__setattr__('dil_bn_k{}_{}'.format(k, r), get_bn(channels))
def forward(self, x):
if not hasattr(self, 'origin_bn'): # deploy mode
return self.lk_origin(x)
out = self.origin_bn(self.lk_origin(x))
for k, r in zip(self.kernel_sizes, self.dilates):
conv = self.__getattr__('dil_conv_k{}_{}'.format(k, r))
bn = self.__getattr__('dil_bn_k{}_{}'.format(k, r))
out = out + bn(conv(x))
return out
def merge_dilated_branches(self):
if hasattr(self, 'origin_bn'):
origin_k, origin_b = fuse_bn(self.lk_origin, self.origin_bn)
for k, r in zip(self.kernel_sizes, self.dilates):
conv = self.__getattr__('dil_conv_k{}_{}'.format(k, r))
bn = self.__getattr__('dil_bn_k{}_{}'.format(k, r))
branch_k, branch_b = fuse_bn(conv, bn)
origin_k = merge_dilated_into_large_kernel(origin_k, branch_k, r)
origin_b += branch_b
merged_conv = get_conv2d_uni(origin_k.size(0), origin_k.size(0), origin_k.size(2), stride=1,
padding=origin_k.size(2)//2, dilation=1, groups=origin_k.size(0), bias=True,
attempt_use_lk_impl=self.attempt_use_lk_impl)
merged_conv.weight.data = origin_k
merged_conv.bias.data = origin_b
self.lk_origin = merged_conv
self.__delattr__('origin_bn')
for k, r in zip(self.kernel_sizes, self.dilates):
self.__delattr__('dil_conv_k{}_{}'.format(k, r))
self.__delattr__('dil_bn_k{}_{}'.format(k, r))
from itertools import repeat
import collections.abc
def _ntuple(n):
def parse(x):
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
return tuple(x)
return tuple(repeat(x, n))
return parse
to_1tuple = _ntuple(1)
to_2tuple = _ntuple(2)
to_3tuple = _ntuple(3)
to_4tuple = _ntuple(4)
to_ntuple = _ntuple
def fuse_bn(conv, bn):
kernel = conv.weight
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def get_conv2d_uni(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias,
attempt_use_lk_impl=True):
kernel_size = to_2tuple(kernel_size)
if padding is None:
padding = (kernel_size[0] // 2, kernel_size[1] // 2)
else:
padding = to_2tuple(padding)
need_large_impl = kernel_size[0] == kernel_size[1] and kernel_size[0] > 5 and padding == (kernel_size[0] // 2, kernel_size[1] // 2)
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias)
def convert_dilated_to_nondilated(kernel, dilate_rate):
identity_kernel = torch.ones((1, 1, 1, 1), dtype=kernel.dtype, device =kernel.device )
if kernel.size(1) == 1:
# This is a DW kernel
dilated = F.conv_transpose2d(kernel, identity_kernel, stride=dilate_rate)
return dilated
else:
# This is a dense or group-wise (but not DW) kernel
slices = []
for i in range(kernel.size(1)):
dilated = F.conv_transpose2d(kernel[:,i:i+1,:,:], identity_kernel, stride=dilate_rate)
slices.append(dilated)
return torch.cat(slices, dim=1)
def merge_dilated_into_large_kernel(large_kernel, dilated_kernel, dilated_r):
large_k = large_kernel.size(2)
dilated_k = dilated_kernel.size(2)
equivalent_kernel_size = dilated_r * (dilated_k - 1) + 1
equivalent_kernel = convert_dilated_to_nondilated(dilated_kernel, dilated_r)
rows_to_pad = large_k // 2 - equivalent_kernel_size // 2
merged_kernel = large_kernel + F.pad(equivalent_kernel, [rows_to_pad] * 4)
return merged_kernel
def get_bn(channels):
return nn.BatchNorm2d(channels)
class DepthBottleneckUniv2(nn.Module):
def __init__(self,
in_channels,
out_channels,
shortcut=True,
kersize=5,
expansion_depth=1,
small_kersize=3,
use_depthwise=True):
super(DepthBottleneckUniv2, self).__init__()
mid_channel = int(in_channels * expansion_depth)
mid_channel2 = mid_channel
self.conv1 = Conv(in_channels, mid_channel, 1)
self.shortcut = shortcut
if use_depthwise:
self.conv2 = UniRepLKNetBlock(mid_channel, kernel_size=kersize)
self.act = nn.SiLU()
self.one_conv = Conv(mid_channel, mid_channel2, kernel_size=1)
self.conv3 = UniRepLKNetBlock(mid_channel2, kernel_size=kersize)
self.act1 = nn.SiLU()
self.one_conv2 = Conv(mid_channel2, out_channels, kernel_size=1)
else:
self.conv2 = Conv(out_channels, out_channels, 3, 1)
def forward(self, x):
y = self.conv1(x)
y = self.act(self.conv2(y))
y = self.one_conv(y)
y = self.act1(self.conv3(y))
y = self.one_conv2(y)
return y
class RepHMS(nn.Module):
def __init__(self, in_channels, out_channels, width=3, depth=1, depth_expansion=2, kersize=5, shortcut=True,
expansion=0.5,
small_kersize=3, use_depthwise=True):
super(RepHMS, self).__init__()
self.width = width
self.depth = depth
c1 = int(out_channels * expansion) * width
c_ = int(out_channels * expansion)
self.c_ = c_
self.conv1 = Conv(in_channels, c1, 1, 1)
self.RepElanMSBlock = nn.ModuleList()
for _ in range(width - 1):
DepthBlock = nn.ModuleList([
DepthBottleneckUniv2(self.c_, self.c_, shortcut, kersize, depth_expansion, small_kersize, use_depthwise)
for _ in range(depth)
])
self.RepElanMSBlock.append(DepthBlock)
self.conv2 = Conv(c_ * 1 + c_ * (width - 1) * depth, out_channels, 1, 1)
def forward(self, x):
x = self.conv1(x)
x_out = [x[:, i * self.c_:(i + 1) * self.c_] for i in range(self.width)]
x_out[1] = x_out[1] + x_out[0]
cascade = []
elan = [x_out[0]]
for i in range(self.width - 1):
for j in range(self.depth):
if i > 0:
x_out[i + 1] = x_out[i + 1] + cascade[j]
if j == self.depth - 1:
#cascade = [cascade[-1]]
if self.depth > 1:
cascade =[cascade[-1]]
else:
cascade = []
x_out[i + 1] = self.RepElanMSBlock[i][j](x_out[i + 1])
elan.append(x_out[i + 1])
if i < self.width - 2:
cascade.append(x_out[i + 1])
y_out = torch.cat(elan, 1)
y_out = self.conv2(y_out)
return y_out
class DepthBottleneckv2(nn.Module):
def __init__(self,
in_channels,
out_channels,
shortcut=True,
kersize=5,
expansion_depth=1,
small_kersize=3,
use_depthwise=True):
super(DepthBottleneckv2, self).__init__()
mid_channel = int(in_channels * expansion_depth)
mid_channel2 = mid_channel
self.conv1 = Conv(in_channels, mid_channel, 1)
self.shortcut = shortcut
if use_depthwise:
self.conv2 = DWConv(mid_channel, mid_channel, kersize)
# self.act = nn.SiLU()
self.one_conv = Conv(mid_channel, mid_channel2, kernel_size=1)
self.conv3 = DWConv(mid_channel2, mid_channel2, kersize)
# self.act1 = nn.SiLU()
self.one_conv2 = Conv(mid_channel2, out_channels, kernel_size=1)
else:
self.conv2 = Conv(out_channels, out_channels, 3, 1)
def forward(self, x):
y = self.conv1(x)
y = self.conv2(y)
y = self.one_conv(y)
y = self.conv3(y)
y = self.one_conv2(y)
return y
class ConvMS(nn.Module):
def __init__(self, in_channels, out_channels, width=3, depth=1, depth_expansion=2, kersize=5, shortcut=True,
expansion=0.5,
small_kersize=3, use_depthwise=True):
super(ConvMS, self).__init__()
self.width = width
self.depth = depth
c1 = int(out_channels * expansion) * width
c_ = int(out_channels * expansion)
self.c_ = c_
self.conv1 = Conv(in_channels, c1, 1, 1)
self.RepElanMSBlock = nn.ModuleList()
for _ in range(width - 1):
DepthBlock = nn.ModuleList([
DepthBottleneckv2(self.c_, self.c_, shortcut, kersize, depth_expansion, small_kersize, use_depthwise)
for _ in range(depth)
])
self.RepElanMSBlock.append(DepthBlock)
self.conv2 = Conv(c_ * 1 + c_ * (width - 1) * depth, out_channels, 1, 1)
def forward(self, x):
x = self.conv1(x)
x_out = [x[:, i * self.c_:(i + 1) * self.c_] for i in range(self.width)]
x_out[1] = x_out[1] + x_out[0]
cascade = []
elan = [x_out[0]]
for i in range(self.width - 1):
for j in range(self.depth):
if i > 0:
x_out[i + 1] = x_out[i + 1] + cascade[j]
if j == self.depth - 1:
# cascade = [cascade[-1]]
if self.depth > 1:
cascade = [cascade[-1]]
else:
cascade = []
x_out[i + 1] = self.RepElanMSBlock[i][j](x_out[i + 1])
elan.append(x_out[i + 1])
if i < self.width - 2:
cascade.append(x_out[i + 1])
y_out = torch.cat(elan, 1)
y_out = self.conv2(y_out)
return y_out
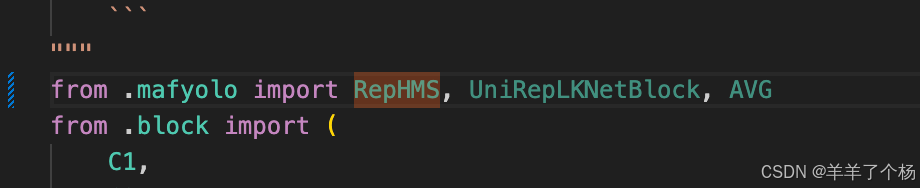
4. 再更改ultralytics/nn/modules/__init__.py文件,开头加入
from .mafyolo import RepHMS, UniRepLKNetBlock, AVG
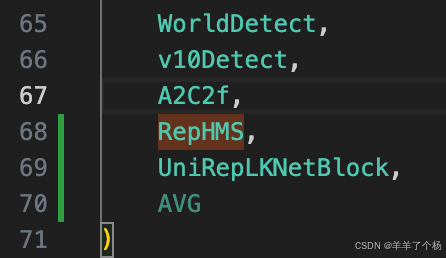
5. 在ultralytics/nn/tasks.py中from ultralytics.nn.modules import ()加入引用,如图
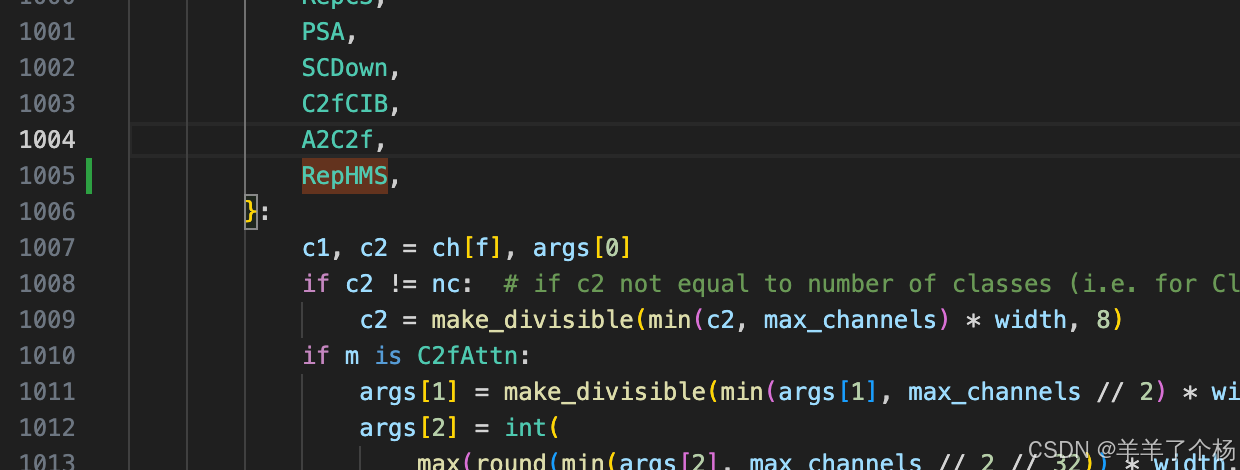
6. 在可能1000多行的位置加入RepHMS
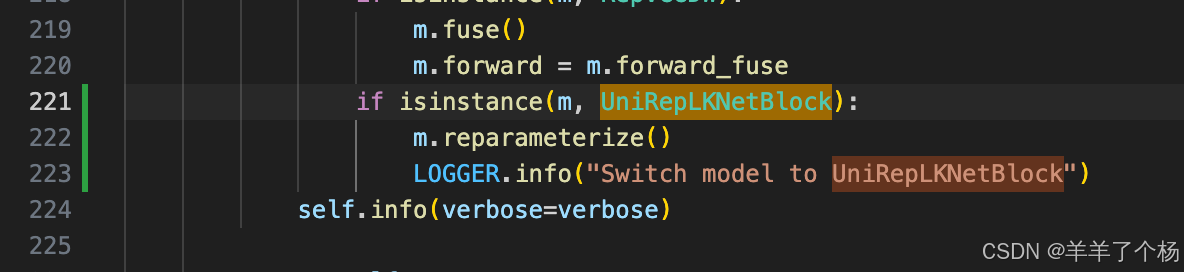
7. 大概220行加入UniRepLKNetBlock,这个可以让验证阶段发生重参数化
8. 此时应该可以运行了,这是我训练COCO的代码
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov12n-MAFPN.yaml')
model.train(data='coco.yaml', batch=128, device=[0, 1, 2, 3], epochs=500, imgsz=640, scale=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.1)
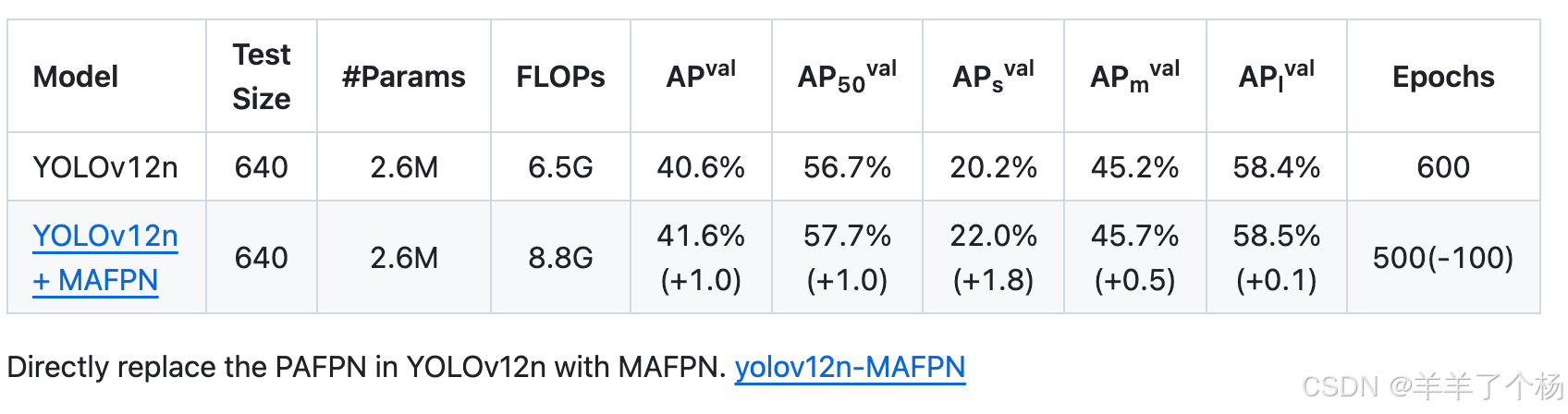
得到的精度如下,权重和文件可以在MHAF-YOLO项目中找到,总体来看参数量不变,计算量增加了,AP提升了1%,小目标AP提升了1.8%,训练轮次降低了100,收益还可以,希望对大家的工作也有启发,如果对大家有帮助的话可以点个Star,加个文章引用,或者试试我们的项目MHAF-YOLO,这对我的工作有很大的帮助,谢谢,有问题可以评论区指出,有空就解答YO !


















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











