







《最优化理论》课程作业
目录
1. SVM介绍
支持向量机SVM是一种二分类模型,其基本模型是定义在特征空间上的间隔最大的线性分类器。
设有数据集 T { ( x i , y i ) ∣ i = 1 , . . . , N } T \left \{ (x_i,y_i)|i=1,...,N \right \} T{(xi,yi)∣i=1,...,N}, x i x_i xi是第i个数据样本的特征, x i ∈ R m x_i \in R^m xi∈Rm,即特征为m维,每个样本的标签类别 y i ∈ { − 1 , + 1 } y_i \in \{-1,+1\} yi∈{−1,+1},当 y i = − 1 y_i=-1 yi=−1时,称 x i x_i xi为负例;当 y i = + 1 y_i=+1 yi=+1时,称 x i x_i xi为正例。
假设数据T是线性可分的,即存在超平面S: w T x + b = 0 w^T x+b=0 wTx+b=0能够将数据集T中的正实例和负实例点完全划分到超平面两侧,即对 y i = + 1 y_i=+1 yi=+1的正例, w ⋅ x i + b > 0 w \cdot x_i +b>0 w⋅xi+b>0,对 y i = − 1 y_i=-1 yi=−1d的负例, w ⋅ x i + b < 0 w \cdot x_i+b<0 w⋅xi+b<0。显然,这是一个二分类问题。
当数据集线性可分时,存在无穷多个分离超平面可以将两类数据正确分开。线性可分支持向量机通过(几何)间隔最大化或等价地求解相应的凸二次规划问题得到分离超平面。
2. SVM推导
2.1 函数间隔与几何间隔
超平面
(
w
,
b
)
(w,b)
(w,b)关于某一样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的函数间隔定义为
γ
^
i
=
y
i
(
w
⋅
x
i
+
b
)
\hat \gamma_i=y_i\left ({w \cdot x_i+b}\right)
γ^i=yi(w⋅xi+b)超平面
(
w
,
b
)
(w,b)
(w,b)关于所有样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的函数间隔定义为所有样本点函数间隔的最小值:
γ
^
=
m
i
n
i
=
1
,
.
.
.
,
N
γ
^
i
\hat\gamma=\underset{i=1,...,N}{min}\hat\gamma_i
γ^=i=1,...,Nminγ^i对函数间隔进行规范化,则超平面
(
w
,
b
)
(w,b)
(w,b)关于某一样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的几何间隔定义为
γ
i
=
y
i
(
w
⋅
x
i
+
b
∣
∣
w
∣
∣
)
\gamma_i=y_i\left ( \frac{w \cdot x_i+b}{||w||}\right)
γi=yi(∣∣w∣∣w⋅xi+b)几何间隔是实例点到超平面的带符号的距离(符号是因为
y
i
y_i
yi可正可负)。
超平面
(
w
,
b
)
(w,b)
(w,b)关于所有样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的几何间隔定义为
γ
=
m
i
n
i
=
1
,
.
.
.
,
N
γ
i
\gamma=\underset{i=1,...,N}{min}\gamma_i
γ=i=1,...,Nminγi由上述定义,可以得出函数间隔与几何间隔间的关系:
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 55: …ad \gamma=\hat \̲f̲r̲a̲c̲ ̲{\gamma}{||w||}
SVM学习的基本思想是求解能够正确划分数据集并使几何间隔最大的超平面。虽然对线性可分的数据集而言,分离超平面有无穷多个,但使几何间隔最大的分离超平面是唯一的。
求几何间隔最大的分离超平面的问题,可以转换为约束最优化问题:
m
a
x
w
,
b
γ
s
.
t
.
y
i
(
w
⋅
x
i
+
b
∣
∣
w
∣
∣
)
≥
γ
,
i
=
1
,
2
,
.
.
.
,
N
\underset{w,b}{max} \ \gamma\\s.t.\quad y_i\left ( \frac{w \cdot x_i+b}{||w||}\right)≥\gamma,\quad i=1,2,...,N
w,bmax γs.t.yi(∣∣w∣∣w⋅xi+b)≥γ,i=1,2,...,N即希望最大化超平面
(
w
,
b
)
(w,b)
(w,b)关于数据集的几何间隔
γ
\gamma
γ,并使超平面关于每个样本点的几何间隔至少是
γ
\gamma
γ。
用函数间隔替换几何间隔,可将优问题改写为:
m
a
x
w
,
b
γ
^
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
⋅
x
i
+
b
)
≥
γ
^
,
i
=
1
,
2
,
.
.
.
,
N
\underset{w,b}{max} \ \frac{\hat\gamma}{||w||}\\s.t.\quad y_i\left ( w \cdot x_i+b\right )≥\hat\gamma,\quad i=1,2,...,N
w,bmax ∣∣w∣∣γ^s.t.yi(w⋅xi+b)≥γ^,i=1,2,...,N函数间隔并不影响优化问题的解,故将
γ
^
\hat\gamma
γ^替换为1,又最大化
1
∣
∣
w
∣
∣
\frac{1}{||w||}
∣∣w∣∣1(另一个角度,最大化平面
w
x
+
b
=
−
1
wx+b=-1
wx+b=−1与平面
w
x
+
b
=
+
1
wx+b=+1
wx+b=+1的距离,即
2
∣
∣
w
∣
∣
\frac{2}{||w||}
∣∣w∣∣2)与最小化
1
2
∣
∣
w
∣
∣
2
\frac{1}{2}||w||^2
21∣∣w∣∣2是等价的,则得到SVM对应的优化问题的最终形式(原始最优化问题):
m
i
n
w
,
b
f
=
1
2
∣
∣
w
∣
∣
2
s
.
t
.
g
i
=
1
−
y
i
(
w
⋅
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
\underset{w,b}{min}\ f=\frac{1}{2}||w||^2\\s.t. \quad g_i=1-y_i(w\cdot x_i+b)\leq0,\quad i=1,2,...,N
w,bmin f=21∣∣w∣∣2s.t.gi=1−yi(w⋅xi+b)≤0,i=1,2,...,N这是一个凸二次规划问题,并且没有等式约束,只有N个不等式约束。
2.2 解法一:对偶学习算法
引入拉格朗日乘子
λ
i
\lambda_i
λi,i=1,…,N ,构造广义拉格朗日函数:
L
(
w
,
b
,
λ
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
N
λ
i
(
1
−
y
i
(
w
⋅
x
i
+
b
)
)
L(w,b,\lambda)=\frac{1}{2}||w||^2 + \sum\limits_{i=1}^N\lambda_i(1-y_i(w\cdot x_i+b))
L(w,b,λ)=21∣∣w∣∣2+i=1∑Nλi(1−yi(w⋅xi+b))最终,将原始优化问题转化为极小极大问题:
m
i
n
w
,
b
m
a
x
λ
L
(
w
,
b
,
λ
)
s
.
t
.
λ
i
≥
0
\underset{w,b}{min} \; \underset{\lambda}{max}\;L(w,b,\lambda)\\s.t.\quad \lambda_i \geq0
w,bminλmaxL(w,b,λ)s.t.λi≥0其与上述原始最优化问题是等价的,因为当存在某个
g
i
g_i
gi不满足约束,即
g
i
>
0
g_i>0
gi>0时,
m
a
x
λ
L
(
w
,
b
,
λ
)
\underset{\lambda}{max}\;L(w,b,\lambda)
λmaxL(w,b,λ)将使
λ
i
→
+
∞
\lambda_i\rightarrow +\infty
λi→+∞,此时
m
a
x
λ
L
(
w
,
b
,
λ
)
→
+
∞
\underset{\lambda}{max}\;L(w,b,\lambda)\rightarrow +\infty
λmaxL(w,b,λ)→+∞;当所有
g
i
g_i
gi满足约束,即
g
i
≤
0
g_i\leq0
gi≤0时,
m
a
x
λ
L
(
w
,
b
,
λ
)
\underset{\lambda}{max}\;L(w,b,\lambda)
λmaxL(w,b,λ)将使
λ
i
→
0
\lambda_i\rightarrow0
λi→0,此时
m
a
x
λ
L
(
w
,
b
,
λ
)
→
f
\underset{\lambda}{max}\;L(w,b,\lambda)\rightarrow f
λmaxL(w,b,λ)→f。
上述构造的广义拉格朗日函数是极小极大问题,其对偶问题,即极大极小问题: m a x λ m i n w , b L ( w , b , λ ) s . t . λ i ≥ 0 \underset{\lambda}{max}\;\underset{w,b}{min} \; L(w,b,\lambda)\\s.t.\quad \lambda_i \geq0 λmaxw,bminL(w,b,λ)s.t.λi≥0
(1) 求
m
i
n
w
,
b
L
(
w
,
b
,
λ
)
\underset{w,b}{min} \; L(w,b,\lambda)
w,bminL(w,b,λ)
拉格朗日函数关于
w
,
b
w,b
w,b的偏导数等于0:
∇
w
L
(
w
,
b
,
λ
)
=
w
−
∑
i
=
1
N
λ
i
y
i
x
i
=
0
∇
b
L
(
w
,
b
,
λ
)
=
∑
i
=
1
N
λ
i
y
i
=
0
\nabla_wL(w,b,\lambda)=w-\sum\limits_{i=1}^N\lambda_iy_ix_i=0\\ \nabla_bL(w,b,\lambda)=\sum\limits_{i=1}^N\lambda_iy_i=0
∇wL(w,b,λ)=w−i=1∑Nλiyixi=0∇bL(w,b,λ)=i=1∑Nλiyi=0将上述两式其代入拉格朗日函数:
L
(
w
,
b
,
λ
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
λ
i
L(w,b,\lambda)=-\frac{1}{2}\sum\limits_{i=1}^N\sum\limits_{j=1}^N \lambda_i\lambda_jy_iy_j(x_i \cdot x_j)+\sum\limits_{i=1}^N\lambda_i
L(w,b,λ)=−21i=1∑Nj=1∑Nλiλjyiyj(xi⋅xj)+i=1∑Nλi
第一阶段的结果
m
i
n
w
,
b
L
(
w
,
b
,
λ
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
λ
i
\underset{w,b}{min} \; L(w,b,\lambda)=-\frac{1}{2}\sum\limits_{i=1}^N\sum\limits_{j=1}^N \lambda_i\lambda_jy_iy_j(x_i \cdot x_j)+\sum\limits_{i=1}^N\lambda_i
w,bminL(w,b,λ)=−21i=1∑Nj=1∑Nλiλjyiyj(xi⋅xj)+i=1∑Nλi
(2) 求
m
a
x
λ
m
i
n
w
,
b
L
(
w
,
b
,
λ
)
\underset{\lambda}{max}\;\underset{w,b}{min} \; L(w,b,\lambda)
λmaxw,bminL(w,b,λ)
m
a
x
λ
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
λ
i
s
.
t
.
∑
i
=
1
N
λ
i
y
i
=
0
λ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} &\underset{\lambda}{max}\; -\frac{1}{2}\sum\limits_{i=1}^N\sum\limits_{j=1}^N \lambda_i\lambda_jy_iy_j(x_i \cdot x_j)+\sum\limits_{i=1}^N\lambda_i\\ &s.t. \quad \begin{aligned} & \sum\limits_{i=1}^N\lambda_iy_i=0\\ & \lambda_i\geq0,\quad i=1,2,...,N \end{aligned} \end{aligned}
λmax−21i=1∑Nj=1∑Nλiλjyiyj(xi⋅xj)+i=1∑Nλis.t.i=1∑Nλiyi=0λi≥0,i=1,2,...,N其对偶问题为:
m
i
n
λ
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
λ
i
s
.
t
.
∑
i
=
1
N
λ
i
y
i
=
0
λ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} &\underset{\lambda}{min}\; \frac{1}{2}\sum\limits_{i=1}^N\sum\limits_{j=1}^N \lambda_i\lambda_jy_iy_j(x_i \cdot x_j)-\sum\limits_{i=1}^N\lambda_i\\ &s.t. \quad \begin{aligned} & \sum\limits_{i=1}^N\lambda_iy_i=0\\ & \lambda_i\geq0,\quad i=1,2,...,N \end{aligned} \end{aligned}
λmin21i=1∑Nj=1∑Nλiλjyiyj(xi⋅xj)−i=1∑Nλis.t.i=1∑Nλiyi=0λi≥0,i=1,2,...,N记该最优解为
λ
∗
=
λ
1
∗
,
λ
2
∗
,
.
.
.
,
λ
N
∗
\lambda^*=\lambda_1^*,\lambda_2^*,...,\lambda_N^*
λ∗=λ1∗,λ2∗,...,λN∗
有定理使该对偶问题与原始最优化问题满足:存在
a
∗
,
b
∗
a^*,b^*
a∗,b∗,使得
a
∗
a^*
a∗是原问题的解,
b
∗
b^*
b∗是对偶问题的解。这使得可以通过求解对偶问题间接求解原问题。
又有定理: 对凸规划问题,
a
∗
a^*
a∗、
b
∗
b^*
b∗分别是原问题和对偶问题的解的充要条件是该解满足KKT条件。
依此,满足KKT条件时,可以通过对偶问题的解
b
∗
b^*
b∗求得原问题的解
a
∗
a^*
a∗
当KKT条件成立时,有
{
∇
w
L
(
w
∗
,
b
∗
,
λ
∗
)
=
w
∗
−
∑
i
=
1
N
λ
i
∗
y
i
x
i
=
0
∇
b
L
(
w
∗
,
b
∗
,
λ
∗
)
=
∑
i
=
1
N
λ
i
∗
y
i
=
0
λ
i
∗
(
1
−
y
i
(
w
∗
⋅
x
i
+
b
∗
)
)
=
0
,
i
=
1
,
2
,
.
.
.
,
N
1
−
y
i
(
w
∗
⋅
x
i
+
b
∗
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
λ
i
≥
0
\left\{ \begin{aligned} & \nabla_wL(w^*,b^*,\lambda^*)=w^*-\sum\limits_{i=1}^N\lambda_i^*y_ix_i=0\\ & \nabla_bL(w^*,b^*,\lambda^*)=\sum\limits_{i=1}^N\lambda_i^*y_i=0 \\ & \lambda_i^*(1-y_i(w^*\cdot x_i+b^*))=0,\quad i=1,2,...,N\\ & 1-y_i(w^*\cdot x_i+b^*)\leq0,\quad i=1,2,...,N \\ & \lambda_i \geq0 \\ \end{aligned} \right.
⎩
⎨
⎧∇wL(w∗,b∗,λ∗)=w∗−i=1∑Nλi∗yixi=0∇bL(w∗,b∗,λ∗)=i=1∑Nλi∗yi=0λi∗(1−yi(w∗⋅xi+b∗))=0,i=1,2,...,N1−yi(w∗⋅xi+b∗)≤0,i=1,2,...,Nλi≥0由此得
w
∗
=
∑
i
=
1
N
λ
i
∗
y
i
x
i
w^*=\sum\limits_{i=1}^N\lambda_i^*y_ix_i
w∗=i=1∑Nλi∗yixi由于至少有一个
λ
j
∗
>
0
\lambda_j^*>0
λj∗>0,对此j,将上式
w
∗
w^*
w∗代入
λ
i
∗
(
1
−
y
i
(
w
∗
⋅
x
i
+
b
∗
)
)
=
0
,
i
=
j
\lambda_i^*(1-y_i(w^*\cdot x_i+b^*))=0,\quad i=j
λi∗(1−yi(w∗⋅xi+b∗))=0,i=j,得
b
∗
=
1
y
j
−
w
∗
x
j
=
1
y
j
−
∑
i
=
1
N
λ
i
∗
y
i
(
x
i
⋅
x
j
)
=
y
j
−
∑
i
=
1
N
λ
i
∗
y
i
(
x
i
⋅
x
j
)
(
类别标签
y
j
的取值为
±
1
)
\begin{aligned} b^*& =\frac{1}{y_j}-w^*x_j \\ & =\frac{1}{y_j}-\sum\limits_{i=1}^N\lambda_i^*y_i(x_i \cdot x_j)\\ & =y_j-\sum\limits_{i=1}^N\lambda_i^*y_i(x_i \cdot x_j) \quad (类别标签y_j的取值为±1) \end{aligned}
b∗=yj1−w∗xj=yj1−i=1∑Nλi∗yi(xi⋅xj)=yj−i=1∑Nλi∗yi(xi⋅xj)(类别标签yj的取值为±1)
至此,我们由对偶问题的解
λ
∗
\lambda^*
λ∗求得了原始最优化问题的解
{
w
∗
=
∑
i
=
1
N
λ
i
∗
y
i
x
i
b
∗
=
y
j
−
∑
i
=
1
N
λ
i
∗
y
i
(
x
i
⋅
x
j
)
λ
j
≥
0
\left\{ \begin{aligned} & w^*=\sum\limits_{i=1}^N\lambda_i^*y_ix_i \\ & b^*=y_j-\sum\limits_{i=1}^N\lambda_i^*y_i(x_i \cdot x_j) \quad \lambda_j \geq0 \end{aligned} \right.
⎩
⎨
⎧w∗=i=1∑Nλi∗yixib∗=yj−i=1∑Nλi∗yi(xi⋅xj)λj≥0由此我们看出,SVM超平面参数只依赖数据集中
λ
i
∗
>
0
\lambda_i^*>0
λi∗>0对应的样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)
最终SVM的分类决策函数为
f
(
x
)
=
s
i
g
n
(
w
∗
⋅
x
+
b
∗
)
f(x)=sign(w^* \cdot x+b^*)
f(x)=sign(w∗⋅x+b∗)综上,对线性可分数据集,先求对偶问题的解
λ
∗
\lambda^*
λ∗;再求解原始问题的解
w
∗
w^*
w∗,并使用
λ
∗
\lambda^*
λ∗的一个正分量
λ
j
∗
\lambda_j^*
λj∗求解
b
∗
b^*
b∗;最终得到分离超平面和分类决策函数。
2.3 解法二:直接使用KKT条件
满足KKT条件的点为KKT点,在凸问题(包括凸二次规划)中KKT点就是问题的最优解。
通过求解下面的方程组(SVM不含等式约束)来得到KKT点:
{
∇
f
+
∑
i
=
1
N
λ
∇
g
i
=
0
g
i
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
λ
i
≥
0
λ
i
h
i
=
0
\left\{ \begin{aligned} & \nabla f + \sum\limits_{i=1}^N \lambda \nabla g_i = 0 \\ & g_i \leq0,\quad i=1,2,...,N \\ & \lambda_i \geq0 \\ &\lambda_ih_i=0 \end{aligned} \right.
⎩
⎨
⎧∇f+i=1∑Nλ∇gi=0gi≤0,i=1,2,...,Nλi≥0λihi=0
对SVM的优化问题
m
i
n
w
,
b
f
=
1
2
∣
∣
w
∣
∣
2
s
.
t
.
g
i
=
1
−
y
i
(
w
⋅
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
\underset{w,b}{min}\ f=\frac{1}{2}||w||^2\\s.t. \quad g_i=1-y_i(w\cdot x_i+b)\leq0,\quad i=1,2,...,N
w,bmin f=21∣∣w∣∣2s.t.gi=1−yi(w⋅xi+b)≤0,i=1,2,...,N其KKT条件为:
{
w
−
∑
i
=
1
N
λ
i
y
i
x
i
=
0
∑
i
=
1
N
λ
i
y
i
=
0
λ
i
(
1
−
y
i
(
w
⋅
x
i
+
b
)
)
=
0
,
i
=
1
,
2
,
.
.
.
,
N
1
−
y
i
(
w
⋅
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
λ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\left\{ \begin{aligned} & w-\sum\limits_{i=1}^N\lambda_iy_ix_i=0\\ & \sum\limits_{i=1}^N\lambda_iy_i=0\\ & \lambda_i(1-y_i(w\cdot x_i+b))=0, \quad i=1,2,...,N\\ & 1-y_i(w\cdot x_i+b)\leq0, \quad i=1,2,...,N\\ & \lambda_i\geq0, \quad i=1,2,...,N \end{aligned} \right.
⎩
⎨
⎧w−i=1∑Nλiyixi=0i=1∑Nλiyi=0λi(1−yi(w⋅xi+b))=0,i=1,2,...,N1−yi(w⋅xi+b)≤0,i=1,2,...,Nλi≥0,i=1,2,...,N
3. SVM编程求解
3.1 问题样例
数据集包含三个样例,正样例点是 x 1 = ( 3 , 3 ) T x_1=(3,3)^T x1=(3,3)T, x 2 = ( 4 , 3 ) T x_2=(4,3)^T x2=(4,3)T,负样例点是 x 3 = ( 1 , 1 ) T x_3=(1,1)^T x3=(1,1)T。
3.2 KKT方程组
样本空间为三维,将超平面定义为
y
=
w
1
x
1
+
w
2
x
2
+
b
y=w_1x_1+w_2x_2+b
y=w1x1+w2x2+b。由KKT条件,得到如下方程组:
{
w
1
=
3
λ
1
+
4
λ
2
−
λ
3
w
2
=
3
λ
1
+
3
λ
2
−
λ
3
λ
1
+
λ
2
−
λ
3
=
0
λ
1
(
1
−
(
3
w
1
+
3
w
2
+
b
)
)
=
0
λ
2
(
1
−
(
4
w
1
+
3
w
2
+
b
)
)
=
0
λ
3
(
1
+
(
w
1
+
w
2
+
b
)
)
=
0
1
−
(
3
w
1
+
3
w
2
+
b
)
≤
0
1
−
(
4
w
1
+
3
w
2
+
b
)
≤
0
1
+
(
w
1
+
w
2
+
b
)
≤
0
λ
1
≥
0
λ
2
≥
0
λ
3
≥
0
\left\{ \begin{aligned} & w_1=3\lambda_1+4\lambda_2-\lambda_3\\ & w_2=3\lambda_1+3\lambda_2-\lambda_3\\ & \lambda_1+\lambda_2-\lambda_3=0\\ & \lambda_1(1-(3w_1+3w_2+b))=0\\ & \lambda_2(1-(4w_1+3w_2+b))=0\\ & \lambda_3(1+(w_1+w_2+b))=0\\ & 1-(3w_1+3w_2+b)\leq0 \\ & 1-(4w_1+3w_2+b)\leq0 \\ & 1+(w_1+w_2+b)\leq0 \\ & \lambda_1\geq0 \\ & \lambda_2\geq0 \\ & \lambda_3\geq0 \\ \end{aligned} \right.
⎩
⎨
⎧w1=3λ1+4λ2−λ3w2=3λ1+3λ2−λ3λ1+λ2−λ3=0λ1(1−(3w1+3w2+b))=0λ2(1−(4w1+3w2+b))=0λ3(1+(w1+w2+b))=01−(3w1+3w2+b)≤01−(4w1+3w2+b)≤01+(w1+w2+b)≤0λ1≥0λ2≥0λ3≥0
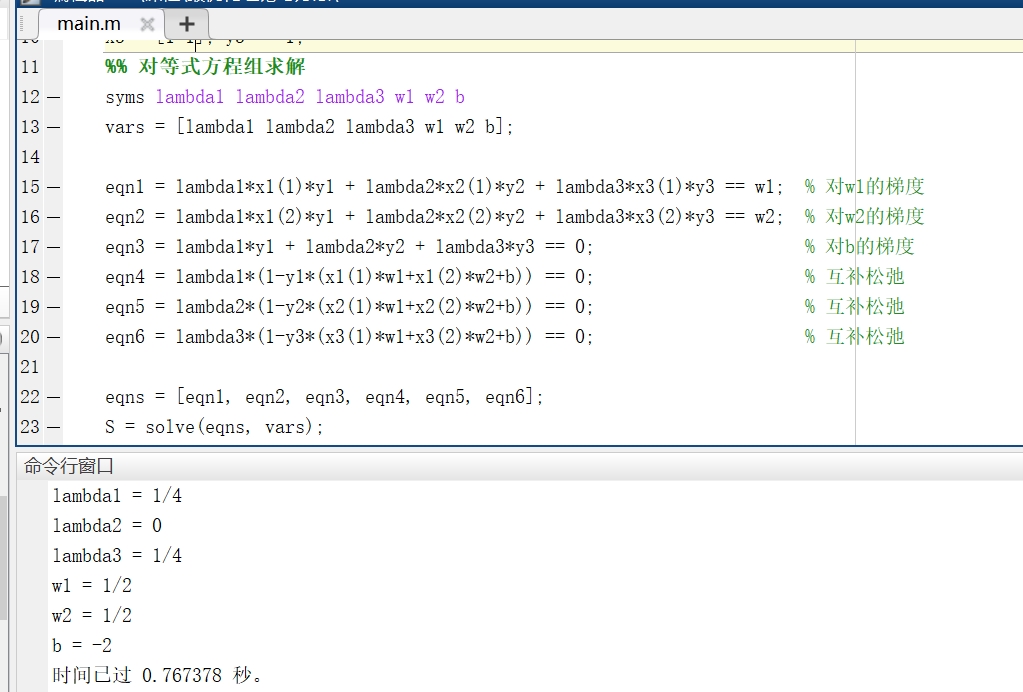
3.3 MATLAB求解
使用MATLAB的solve函数对KKT方程组的前六个等式方程组求解,得到多个解组成的解集,然后筛选出解集中的满足所有剩余不等式约束的解,即问题的最终解。最后并绘制超平面可视化,相关代码及效果如下。
clear
close all
clc
tic
%% 样本点
% (3, 3)--(1) (4, 3)--(1) (1, 1)--(-1)
x1 = [3 3]; y1 = +1;
x2 = [4 3]; y2 = +1;
x3 = [1 1]; y3 = -1;
%% 对等式方程组求解
syms lambda1 lambda2 lambda3 w1 w2 b
vars = [lambda1 lambda2 lambda3 w1 w2 b];
eqn1 = lambda1*x1(1)*y1 + lambda2*x2(1)*y2 + lambda3*x3(1)*y3 == w1; % 对w1的梯度
eqn2 = lambda1*x1(2)*y1 + lambda2*x2(2)*y2 + lambda3*x3(2)*y3 == w2; % 对w2的梯度
eqn3 = lambda1*y1 + lambda2*y2 + lambda3*y3 == 0; % 对b的梯度
eqn4 = lambda1*(1-y1*(x1(1)*w1+x1(2)*w2+b)) == 0; % 互补松弛
eqn5 = lambda2*(1-y2*(x2(1)*w1+x2(2)*w2+b)) == 0; % 互补松弛
eqn6 = lambda3*(1-y3*(x3(1)*w1+x3(2)*w2+b)) == 0; % 互补松弛
eqns = [eqn1, eqn2, eqn3, eqn4, eqn5, eqn6];
S = solve(eqns, vars);
%% 满足剩余不等式约束
n = length(S.b);
flag = false;
for i = 1:n
lambda1_ = S.lambda1(i);
lambda2_ = S.lambda2(i);
lambda3_ = S.lambda3(i);
w1_ = S.w1(i);
w2_ = S.w2(i);
b_ = S.b(i);
if (lambda1_ >= 0)...
&& (lambda2_ >= 0)...
&& (lambda3_ >= 0)...
&& ((3*w1_ + 3*w2_ + b_) >= 1)...
&& ((4*w1_ + 3*w2_ + b_) >= 1)...
&& (-(w1_ + w2_ + b_) >= 1)
fprintf('lambda1 = %s \nlambda2 = %s \nlambda3 = %s \nw1 = %s \nw2 = %s \nb = %s \n',...
lambda1_, lambda2_, lambda3_, w1_, w2_, b_)
flag = true;
break
end
end
if ~flag
fprintf('无解\n')
end
%% 绘图
x_all = [x1(1), x2(1), x3(1)];
y_all = [x1(2), x2(2), x3(2)];
z_all = [y1, y2, y3];
X = linspace(min(x_all)-2, max(x_all)+2, 60);
Y = linspace(min(y_all)-2, max(y_all)+2, 60);
[X, Y] = meshgrid(X, Y);
Z = double(w1_) .* X + double(w2_) .* Y + double(b_);
figure(1)
colormap('jet')
mesh(X, Y, Z)
% view(23, -18)
view(57, 19)
hold on
plot3(x_all, y_all, z_all, 'bo', 'MarkerFaceColor', 'k', 'MarkerSize', 8)
hold off
axis([-inf, inf, -inf, inf, -2, 2])
xlabel('x1')
ylabel('x2')
zlabel('y')
toc
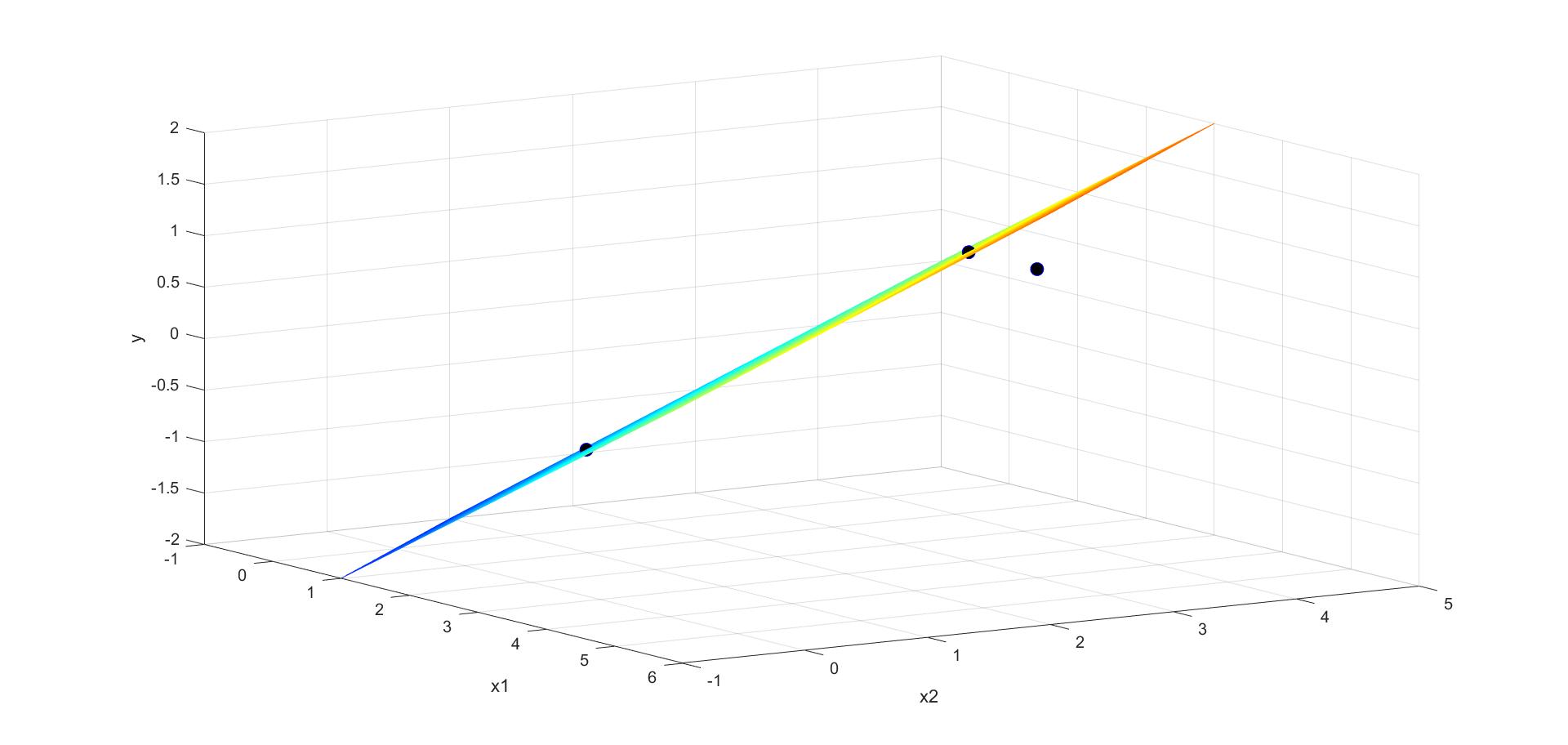
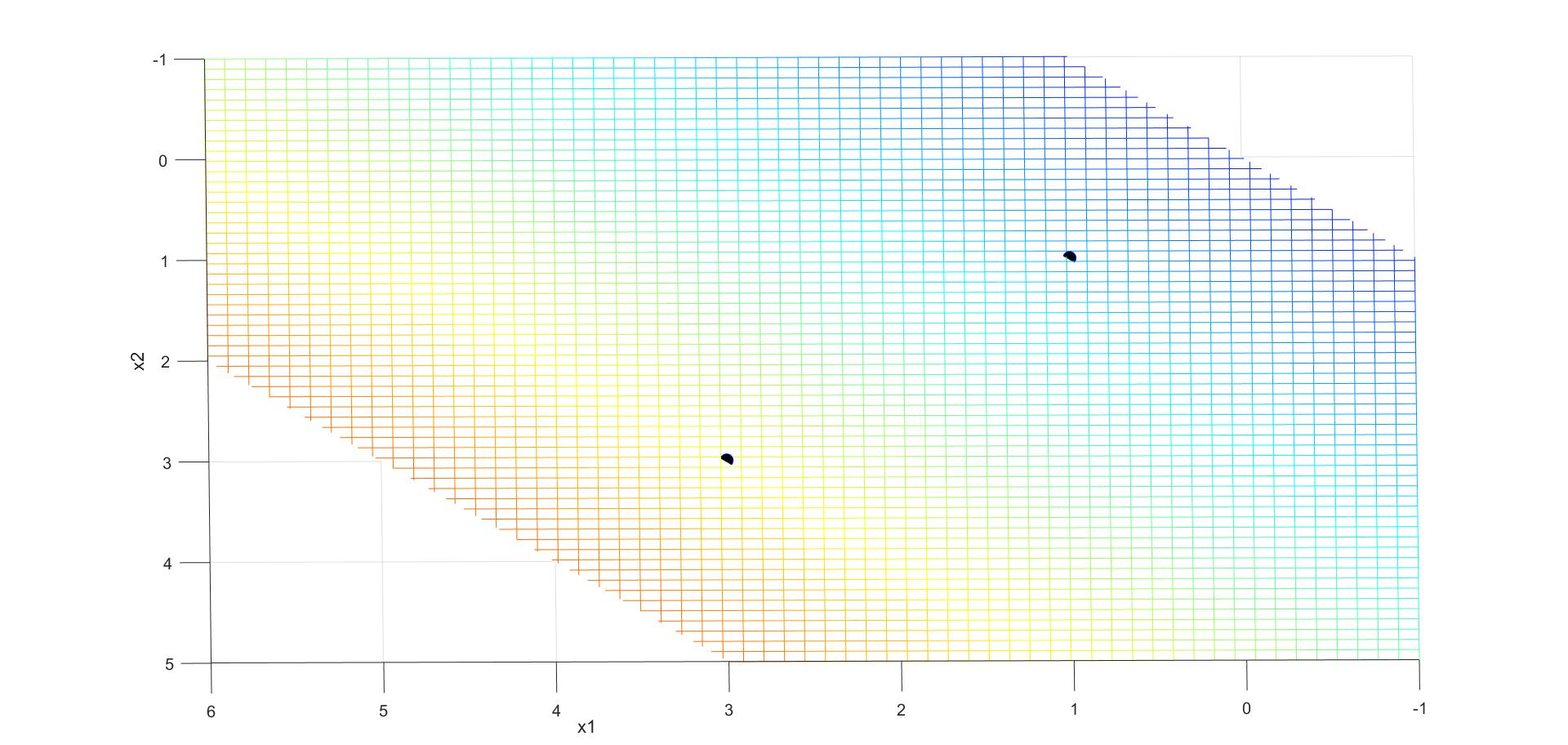
得到的分离超平面为 y = 1 2 x 1 + 1 2 x 2 − 2 y = \frac{1}{2}x_1+\frac{1}{2}x_2-2 y=21x1+21x2−2,由可视化结果可以看出, ( 3 , 3 ) T (3,3)^T (3,3)T和 ( 1 , 1 ) T (1,1)^T (1,1)T为支持向量。
4. 总结
- 以SVM为研究对象,并由最大化几何间隔,最终建立起SVM的约束最优化问题。
- 以对偶问题、KKT条件、凸规划问题的性质等为切入点,一步步推导出SVM的最优解。
- 设计了一个实例,建立KKT方程组,并使用MATLAB编程求解,得到分离超平面,通过可视化超平面得到支持向量。
在整个过程中,通过学习、推导与应用,加深了对线性可分支持向量机的理解,并深入理解了KKT条件的组成与背后逻辑,也了解了KKT条件的应用价值。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









