







ssd网络的特征提取部分与常见的卷积方式大同小异,这里从得到六张不同尺寸的特征图说起…
一、检测结果提取
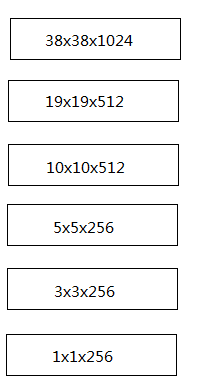
ssd300得到以上六张特征图,它们的先验框数量依次为4,6,6,6,4,4。所有特征图上的总先验框数量为:
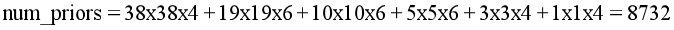
38x38x1024特征图为例,先验框数量为38x38x4,用3x3卷积改变其通道数,生成位置(4)与类别(20+1)预测特征图

将位置预测特征图reshape为[-1,4],将类别预测特征图reshape为(-1,21)
然后将不同尺寸的特征图按第一个维度进行拼接。
最终,
位置预测:[batch_szie,8732,4]
类别预测:[batch_size,8732,21]


二、正负样本的选取
正样本:
1.每个gt box的最大iou default box
2.与任意gt box iou大于0.5
负样本:
采用 hard negative mining,对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差较大的前一部分作为训练的负样本,以保证正负样本比例接近1:3
看段代码,neg_pos_ratio即为负样本比例
1.用上下文管理器强制不进行计算图的构建
2.在最后一个维度进行计算,即计算每个default box的分类概率,第一个维度是背景概率
3.用hard negative mining 和得到的置信度误差进行负样本抽样,得到box id,即mask
4.用mask取出负样本

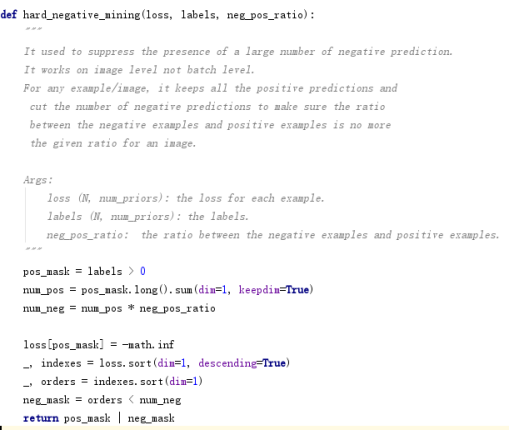
hard negative mining
1.获取正样本掩码pos_mask
2.True转long,在dim=1,统计每个输入对应的正样本数
3.负样本数为正样本数三倍
4.正样本的置信度损失置为负无穷
5.两次sort(),在dim=1,即对每个输入对应的8732个default box按置信度损失降序排列,得到排序索引(向量中每个值对应的排序序号)
6.根据每个输入对应的正样本数获取负样本掩码掩码neg_mask
7.用|按位或运算合并正、负样本掩码
三、损失计算
1.分类损失
用筛选出的正负样本掩码mask,去除需要计算损失的box,预测类别特征图和标签都reshape为[-1,类别数+背景],计算交叉熵。

2.位置损失
只计算正样本的损失,使用smooth L1损失函数

计算的实际是偏移量之间的损失
在GT中,为了限制偏移量的范围,便于预测,对x、y利用w、h进行了归一化,w、h进行了对数处理
因此,实际预测的也是偏移量
3.最终损失
分类损失和位置损失以权重系数α相加,除以该batch中的匹配到GT的box数N














 2325
2325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









