







5.1 卷积神经网络简介
#实例化一个小型的卷积神经网络(CNN)
from keras import layers
from keras import models
#卷积神经网络接受的形状为(image_height, image_width, image_channels)的张量
model = models.Sequential()
#使用3×3的filter
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))建立好一个小型的CNN模型,下面看一下这个模型的网络构架情况:
>>>model.summary()
Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_5 (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 13, 13, 32) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 11, 11, 64) 18496 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 3, 3, 64) 36928 ================================================================= Total params: 55,744 Trainable params: 55,744 Non-trainable params: 0 _________________________________________________________________
宽度和高度两个维度的尺寸通常会随着网络的加深而减小,通道数由传入Conv2D层的第一个参数控制(64或32).下一步是将最后的输出张量(3维)输入到一个密集连接分类器中(前面几章一直在用的)Dense,这些分类器可以处理一维张量,首先我们要将3D张量输出展平为一维张量。
# 在卷积神经网络上添加分类器(这里使用密集连接分类器)
model.add(layers.Flatten()) #展平3维张量
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))>>>model.summary()
Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_5 (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 13, 13, 32) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 11, 11, 64) 18496 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 3, 3, 64) 36928 _________________________________________________________________ flatten_1 (Flatten) (None, 576) 0 _________________________________________________________________ dense_1 (Dense) (None, 64) 36928 _________________________________________________________________ dense_2 (Dense) (None, 10) 650 ================================================================= Total params: 93,322 Trainable params: 93,322 Non-trainable params: 0 _________________________________________________________________
这个模型中使用的filter大小为3×3,所以输入形状为(28,28,1)的张量,输出为(None,26,26,32)26是因为边界效应缩小了两个大小,可以画图理解,大小为28的方块,每次使用3×3的滤镜覆盖,每次移动一格,最后移动到第26步的时候滤镜的右边界和28的大方块的右边界重合将不再进行移动,所以大小会缩小2个单位。如果使用5×5的滤镜,则大小缩小4个。
第一个输出的中,320 =(9×1+1)×32 。其中9是因为使用3×3的滤镜,加一项是截距项。第三行中18496 = (9×32+1)×64 。这里1换成了32是因为第一次conv做完以后输出的形状有32层,而原来的输入只有1层。36928 = (9×64+1)×64 ;第二个输出中flatten_1 (Flatten) (None, 576) 中的576解释为3×3×32,是因为这是一个展平函数,就是把张量变成一维的直接平铺为一层。
Desne和卷积的根本区别:Dense层从输入特征空间学到的是全局模式(比如MNIST数字,全局模式就是涉及所有的像素模式),而卷积层只是学到了局部模式,对图像来说就是学到在输入图像的二维小窗口中发现的模式。
卷积神经网络具有两个特性:
- 学到的模式具有平移不变性
- 卷积神经网络可以学到模式的空间层次结构,这是更接近人脑的学习方式
卷积神经网络的实质:对一个图片里的每个像素值和滤镜的估计值做点对点的乘积,再加上截距项。其实是一个线性变换(卷积核)
最大池化:(MaxPooling)作用,是对特征图进行下采样,减少参数的个数,并且通过让连续的卷积层的观察窗口越来越大从而引入空间过滤器的层级结构
卷积的时候会产生边界效应(导致输出图比原来的图小一些,如果filter是(3,3)的模式,则会缩小两个单位),如果不想对图片进行缩小,则可以使用padding(填充),padding默认是"valid",修改为padding="same"即可。
下面在MNIST数字分类分体上使用卷积神经网络训练一下。
#在MNIST数据集上训练
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)>>>test_loss, test_acc = model.evaluate(test_images, test_labels)
>>>test_acc10000/10000 [==============================] - 1s 105us/step 0.9922999739646912
可以看出CNN的使用使得准确度达到了99.2%,相比于密集连接层的97.8%提升了很多,错误率降低了68%(相对比例),取得了很好的效果。如果想了解为什么CNN有这么惊人的能力,我们需要理解CNN的运算与各层作用。
推荐一篇不错的文章,详细的以动图的形式解析了卷积神经网络的操作情况。https://towardsdatascience.com/gentle-dive-into-math-behind-convolutional-neural-networks-79a07dd44cf9
参考上面的链接,给出卷积神经网络的数学原理解析。
图像在计算机中的存储是这样的:图象是由很多数字组成的矩阵,每一个这样的数字对应一个像素的亮度。在RGB模型中,彩色图像实际上是由三个对应于红、绿、蓝三种颜色通道的矩阵组成的。在黑白图像中,只有一个矩阵,每个矩阵都存储0到255之间的值。
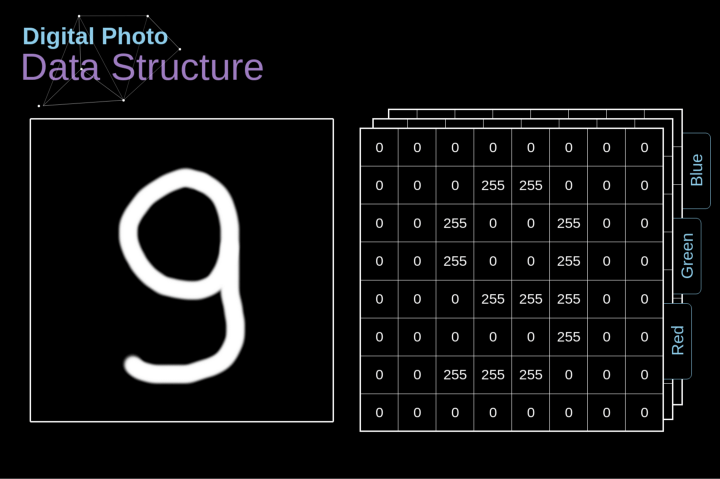
图1. 数字图像的数据结构
卷积的工作原理:在3D输入的特征图上进行slide,filter一般选择3×3或者5×5,在每个可能的位置停止并提取周围特征的3D图块。然后每个3D图块与学到的同一个权重矩阵(卷积核)【卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素 加权平均 后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核】做张量积,转换成形状为(output_depth,)的1D张量。然后对所有这些向量进行空间重组,使其转换为形状为(height,width,output_depth)的3D输出特征图。
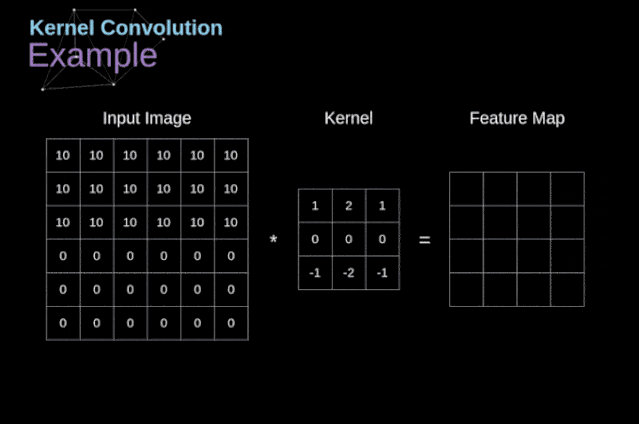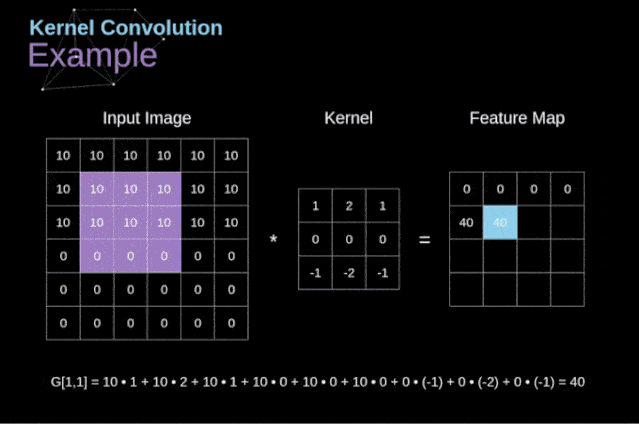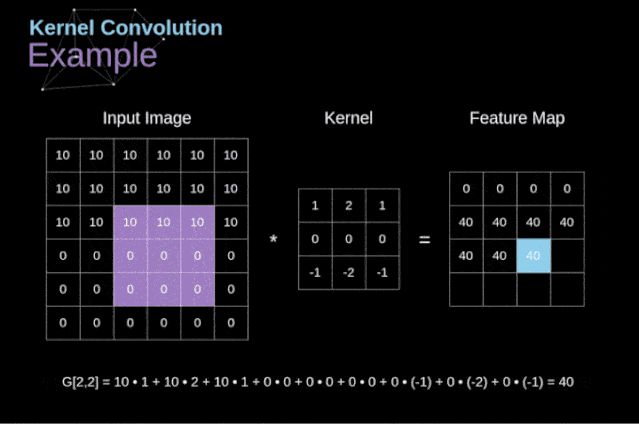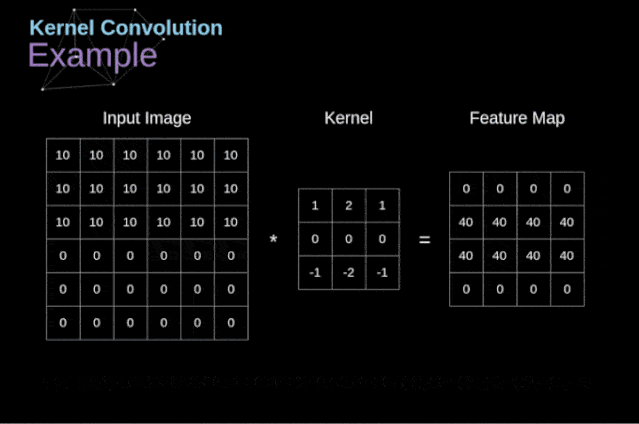
图2 卷积运算图解
卷积的步幅也可以不是1,但是一般步幅为1的效果较好。下面是卷积步幅为2的示意图
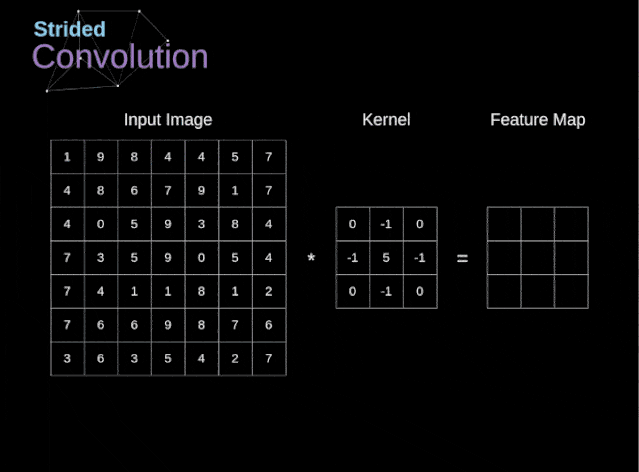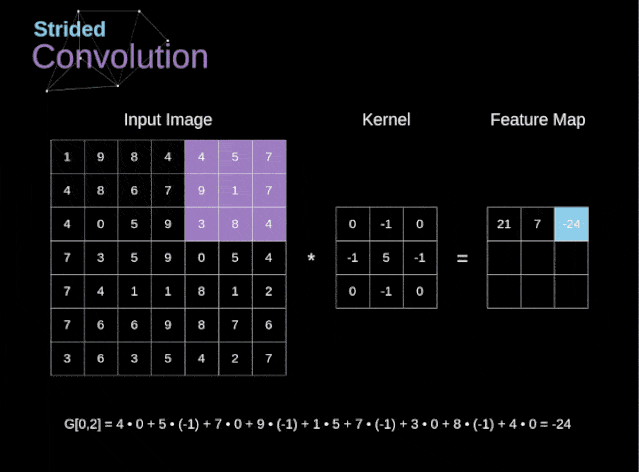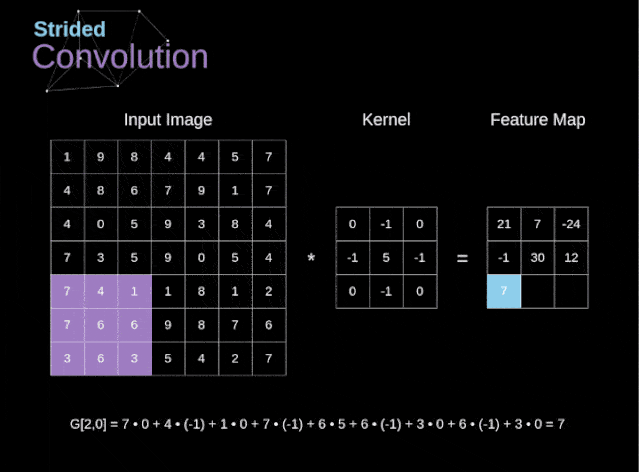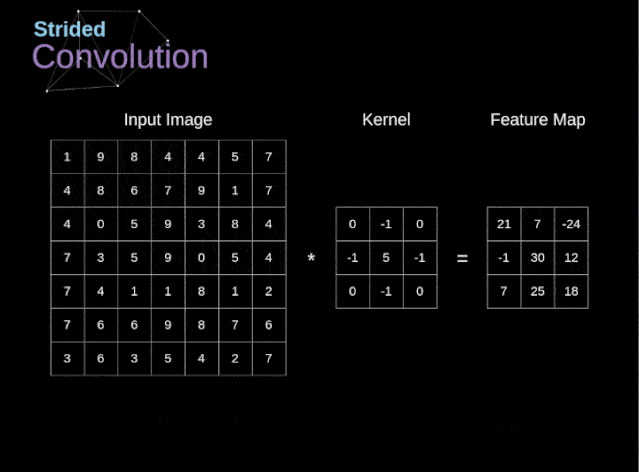
图3 卷积步幅为2的情况
首先介绍一下下采样的作用,下采样是为了减小张量的大小从而加快运算的速度,张量大小较小比较安全,因为张量大小大意味着需估计的参数就越多,参数估计越多就更加容易导致严重的过拟合。卷积步幅为2意味着特征图的宽度和高度都被做下 2 倍采样(变为一半)【除了边界效应引起的变化】,卷积步幅可以实现下采样,但是事实上我们经常使用的最大池化(MaxPooling),最大池化作用就是直接进行下采样,对width和height直接对2整除,所以我们上面构建的网络中第二个MaxPooling结束后输出的形状是(None,5,5,64),11整除2是5,直接舍弃余数,这就是最大池化。
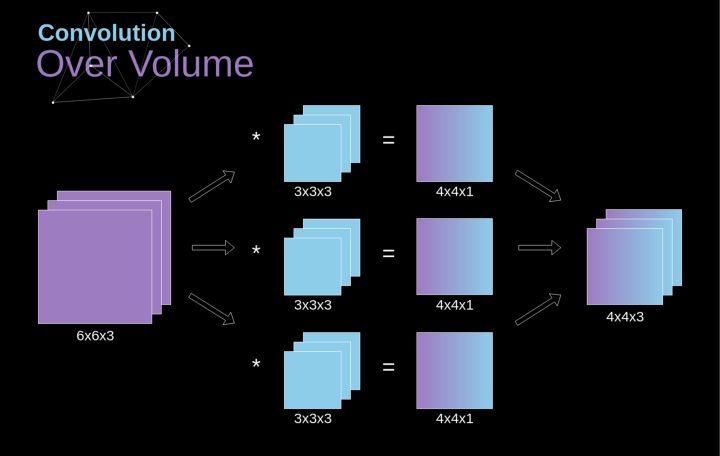
图4 三维卷积
空间卷积是一个常用的概念,彩色图像的通道有三个,所在表示是在一个空间中(单通道的是彩色图像的灰度图像,只需要一层就可以表示,即二维空间)。空间卷积还可以在单层中应用多个卷积核。使用原则是filter(滤镜)和要应用它的图像必须具有相同通道数。一般来说,这种方式与卷积核(图2)的示例非常相似,不过这次我们将三维空间中的值与卷积核对应相乘(即在三维空间中做线性变换)。如果我们想在同一幅图像上使用多个filter,我们分别对它们进行卷积,将结果一个叠在一起,并将它们组合成一个整体。接收张量的维数(即我们的三维矩阵)满足如下方程:n-图像大小,f-滤波器大小,nc-图像中通道数,p-是否使用填充,s-使用的步幅,nf-滤波器个数。
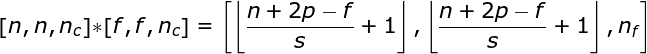
下面我们来看看CNN中各层的操作原理和步骤:
Conv层的操作原理:
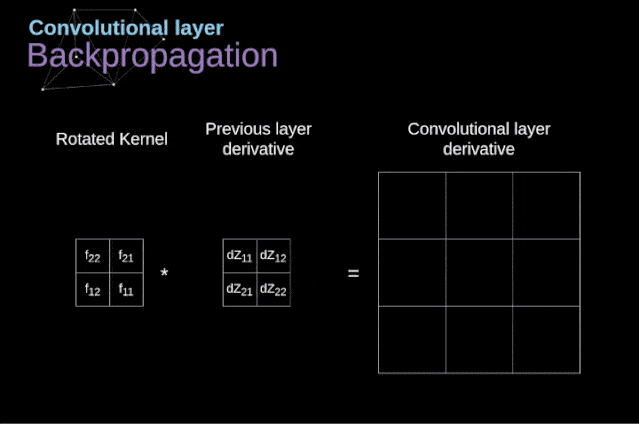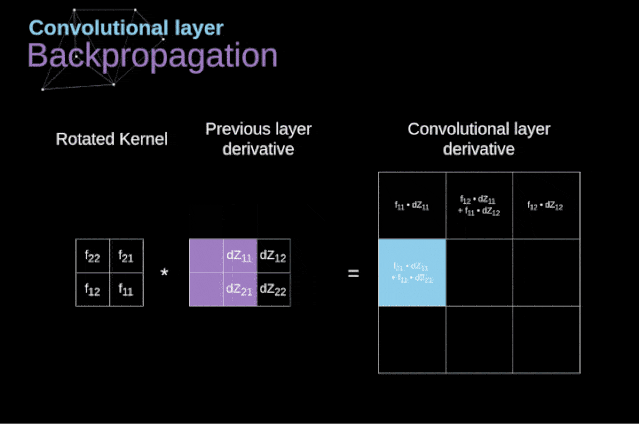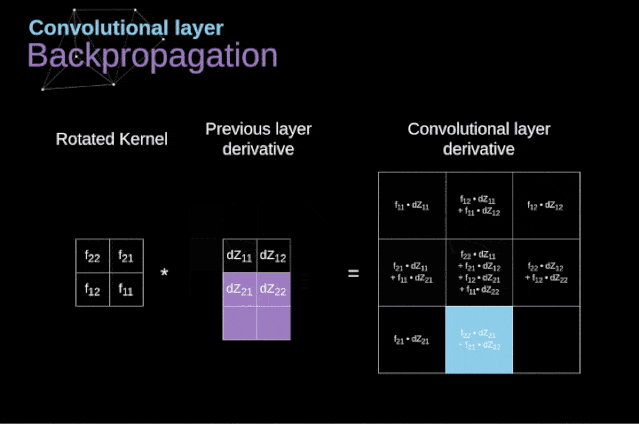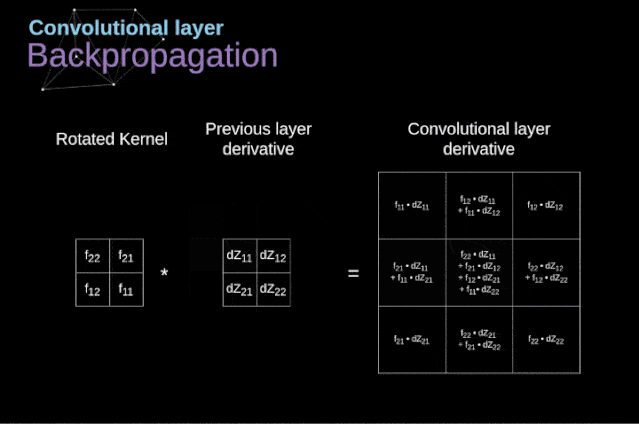
MaxPooling的原理:
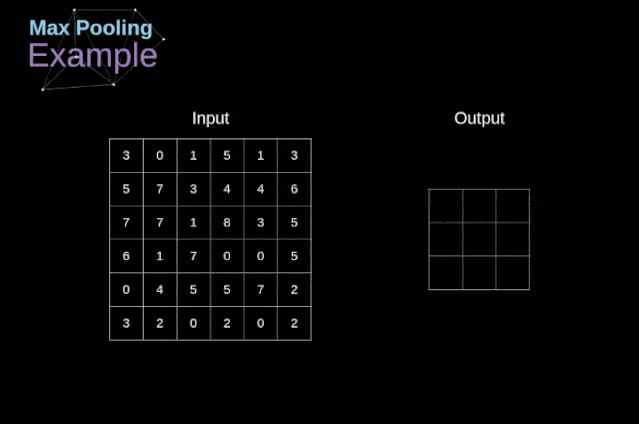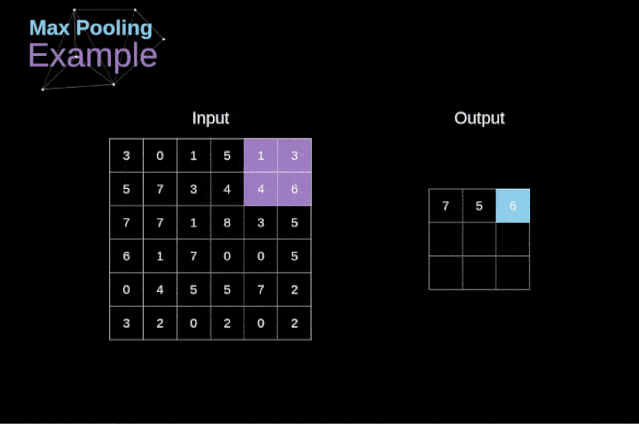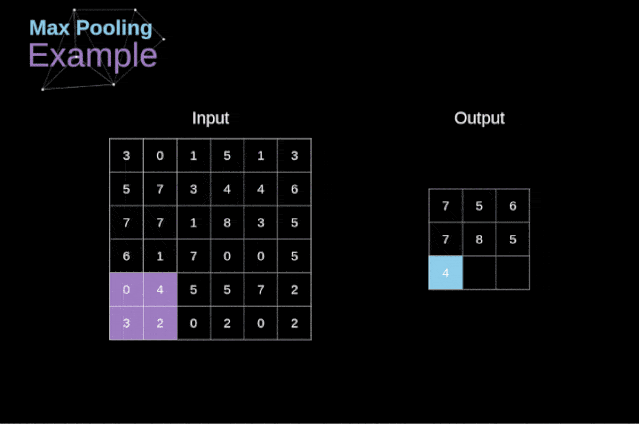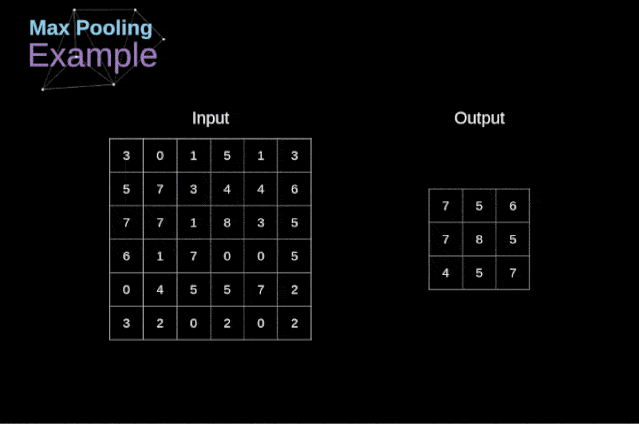
最大池化的例子
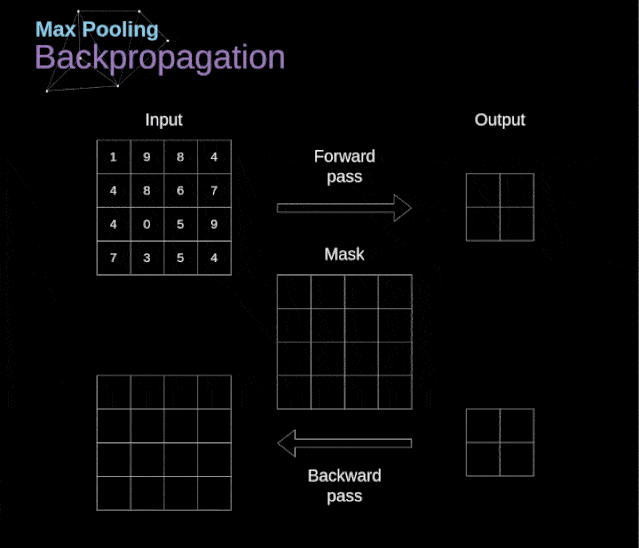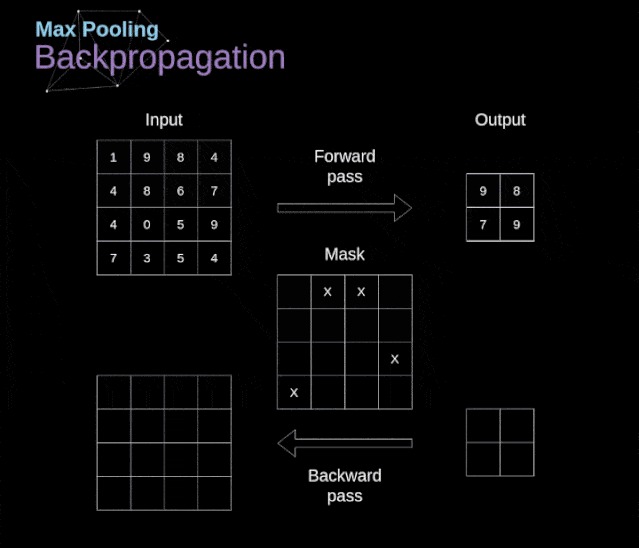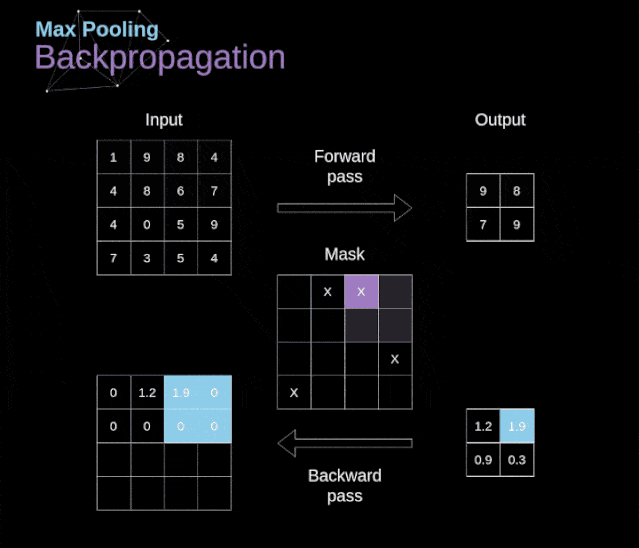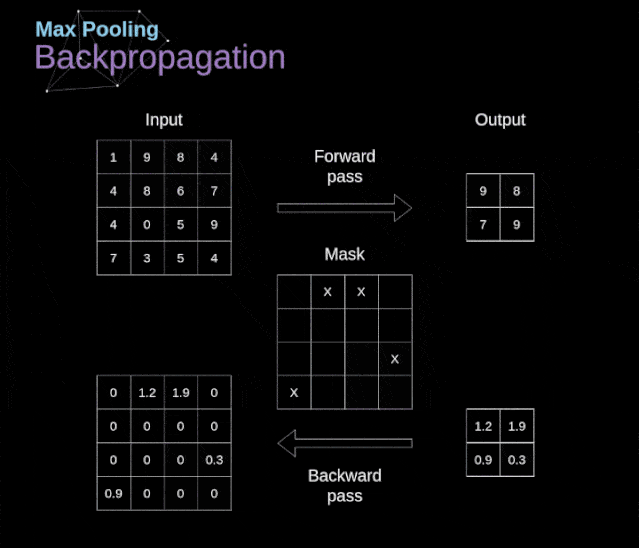
最大池化的反向传播
最大值池化的反向传播实例如上所示,我们将学习的规则只需要稍加调整就可以适用于所有类型的池化层。最大池化层不需要进行参数的更新,任务只是分布梯度不需要做Descent。正如我们所记得的,在最大值池化的正向传播中,我们从每个区域中选择最大值,并将它们传输到下一层。因此,很明显,在反向传播过程中,梯度不应该影响矩阵中没有包含在正向传播中的元素。实际上,这是通过创建一个掩码来实现的,该掩码可以记住第一阶段中使用的值的位置,稍后我们可以使用该掩码来传播梯度。
第五章 深度学习用于计算机视觉(二)——在小型数据集上从头开始训练一个卷积神经网络https://blog.csdn.net/qq_43028656/article/details/119849031















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









