






项目:基于yolov5的舰船检测+pycharm+机器学习+图像检测
项目将深度学习的方法引入海洋目标的检测,利用深度神经网络模型强大的学习能力和模型通用性,来实现准确、可靠和快速的目标自动检测和识别,为海洋领域里不同目标的检测、定位和识别等多种应用需求提供技术支持,她对航海运输、海上搜救等都有实际意义。
· SAR图像特点
· 应用举例:AIS(Automatic Identification System)信息融合、灾害监测、海洋监测、资源勘探、测绘和军事
· 作用:有助于航运交通的目标监测和管理
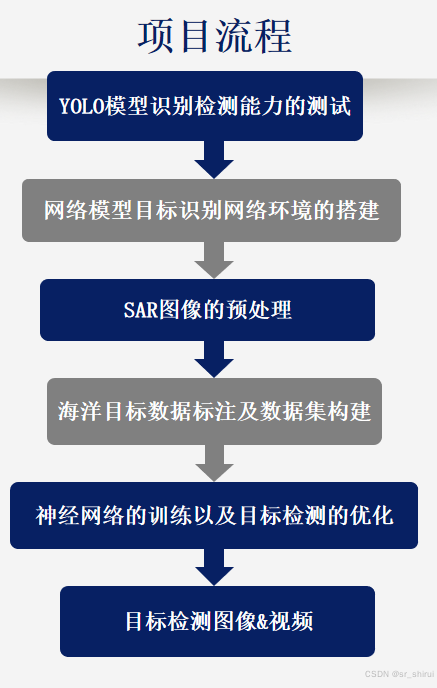
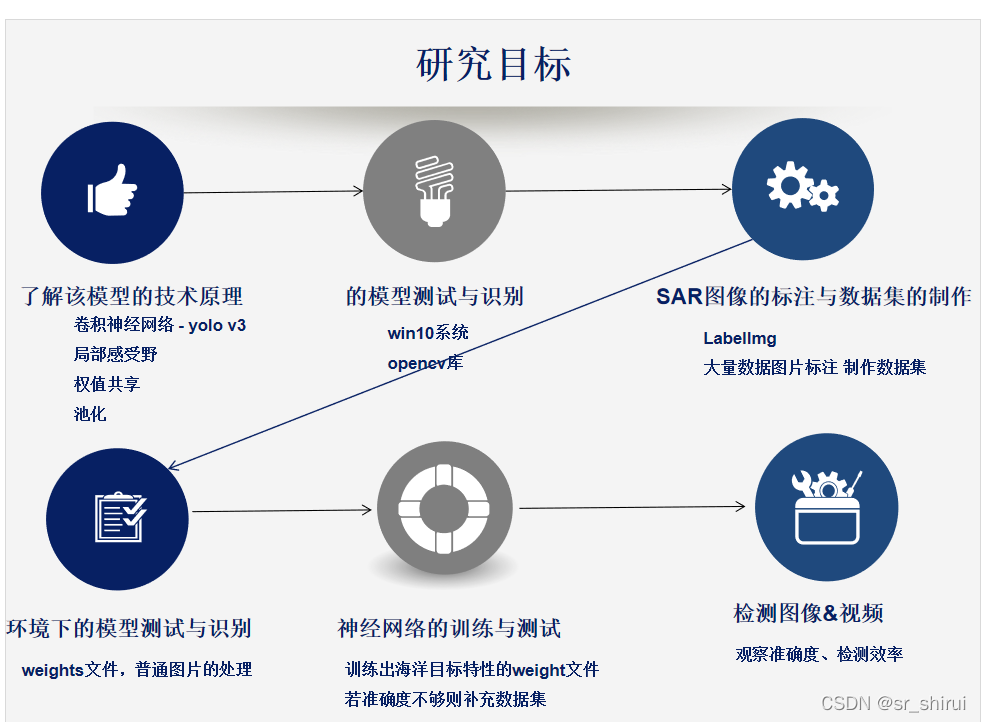
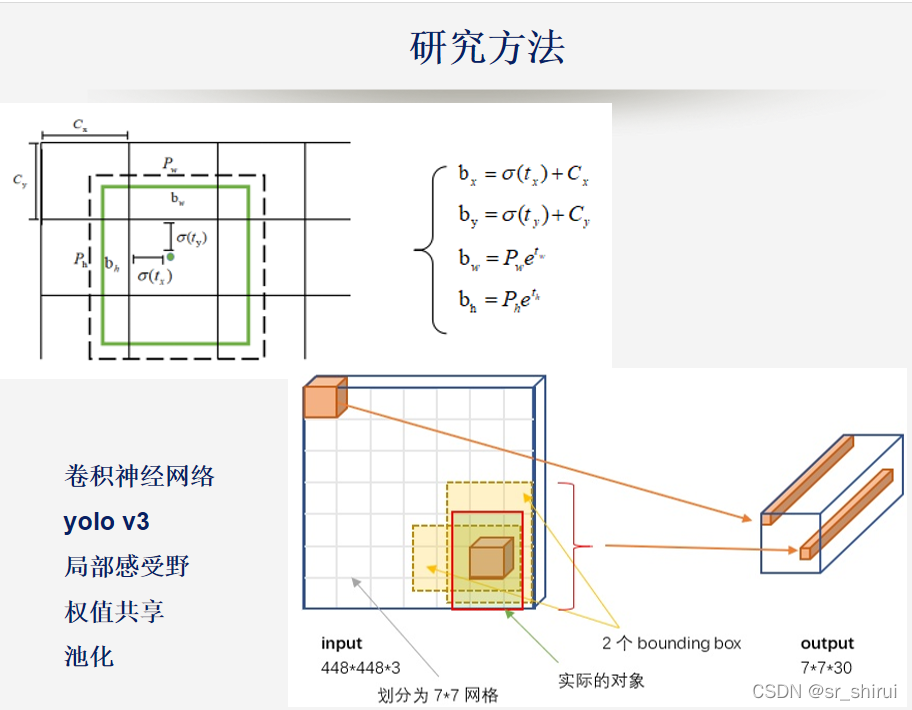
项目流程与结果
1 工程环境的搭建
首先,安装python3.6,并安装pycharm2019作为python的环境IDE。因为训练神经网络的电脑是win10且没有显卡,所以我们采用CPU模式。
打开Pycharm,打开Project,然后开始安装所缺少的库。由于系统版本的不同,所需要安装的库也略有不同。可以把train.py、detect.py和test.py这几个文件点开,看Pycharm的提示进行安装库。
2 SAR图像的标注与数据集的制作
由于开源的SAR图库和SAR图像船舶标注较少,因此,需要用图像标注软件LabelImg对SAR图像下的舰船进行标注。标注示例如下图所示:
标注舰船时要注意区分海岛和舰船,一般海岛形状不规则,且亮度不均匀;而舰船一般为条状亮点,有行驶尾迹。用LabelImg标注后可以生成记录图片中目标位置信息的文件,可以用来训练自己的YOLO网络模型,使之具有检测SAR图像下舰船特征的能力。
其中,标注后生成的文件存储的是标注物的起点坐标(x,y),目标框宽与高(w,h)等数据。每行代表一个目标,各元素分别是:种类(ship)、4个坐标。标注之后的数据集如下所示:
从数据集下载下来Annotations(标注)、JPEGImages(图片)两个文件夹,将他们复制到YOLOV5工程目录下的data文件夹下,然后将JPEGImages文件夹复制一下,并重命名为images,最后在data下新建两个空文件夹,分别命名为ImageSets和labels,建立工程文件编写代码。
再进行迁移学习,修改cfg文件中网络的结构,主要是yolo层前一层的Conv层的卷积核个数。需要将filters=255改为filters=18,即: anchor个数3x(种类数+bbox4个坐标+bbox信度)。将yolo层的class=80改为class=1,即类数。
修改train.py中main函数的parser参数,主要是yolo.cfg文件位置,rbc.data文件位置,还有epochs、batch size等超参数,直接运行就好了。
测试detect.py,测试图片位置默认在data/images输出在runs/detect/exp文件夹。

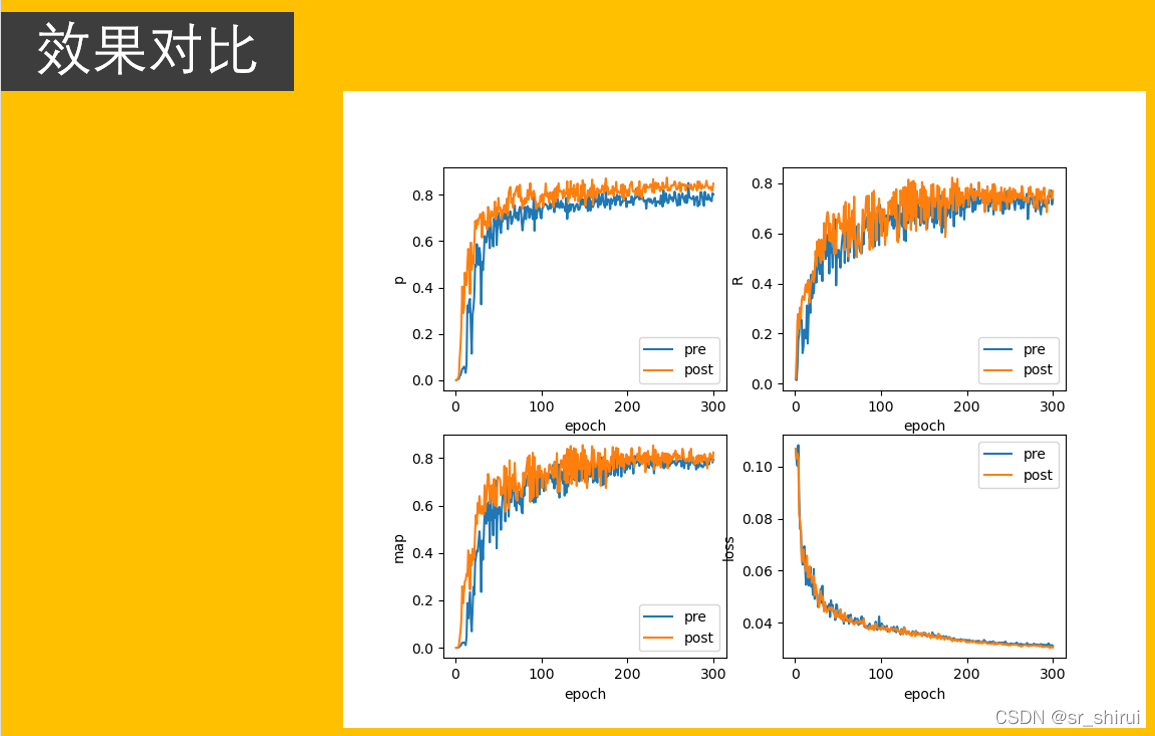
在处理图像的基础上我们也可以处理视频,不过在处理时间上有些长。视频处理的原理基础是将视频顺序截取,然后再对图像进行检测。但目前对图像检测的成果还不是十分优秀,我们训练的YOLO v5网络对视频有一定的检测能力,但由于视频清晰度不够,舰船过小,环境过于复杂等原因,对检测有一定阻碍。由于港口SAR视频较少,用以上视频作为示例,证明我们训练的网络可以检测有舰船特性的目标。若想增强视频检测能力可以增加不同环境下的数据集训练,但有可能降低实时性。
在现如今随人们对AI的运用能力大大提高,运用神经网络检测图像已经不是意见很难实现了。但是在未来对神经网络检测图像的发展中仍然有很多需要完善的地方。首先,完善所制作的SAR图像数据集,并将其用来训练YOLO v5模型,使之能识别SAR图像下的舰船特征。其次,优化网络,降低漏检错检概率。

我的视频演示见:【剪辑-哔哩哔哩】 https://b23.tv/N0LsAvc
数据集标注:https://app.roboflow.com/
工程源码:https://github.com/ultralytics/yolov5
(使用上述源码进行二次开发)
使用在线GPU训练模型:https://colab.research.google.com/


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











