







【强化学习纲要】1 概括与基础
周博磊《强化学习纲要》
学习笔记
课程资料参见: https://github.com/zhoubolei/introRL.
课件: https://github.com/zhoubolei/introRL/blob/master/lecture1.pdf.
1.1 课程简介
周博磊
研究方向:机器感知与机器决策结合
http://bzhou.ie.cuhk.edu.hk/
- 知乎:周博磊
https://www.zhihu.com/people/zhou-bo-lei
教材:Sutton and Barton
《Reinforcement Learning: An Introduction》

基础: - 线性代数,概率论,学过至少一门机器学习课程(数据挖掘,模式识别,深度学习,etc)
- 编程基础:python,pytorch
1.2 强化学习介绍
1.2.1 简介
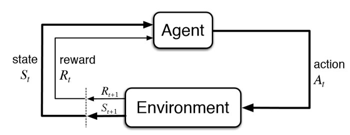
一个agent(智能体)在不确定的environment(环境)下怎样最大化它的reward(奖励),agent始终与environment在交互,agent采取action决策后,action会放入到环境中,环境接收到agent的action后,会进行下一步,输出下一个状态以及agent获取到的reward(奖励)。agent目的是尽可能多的从环境中获取到reward。
1.2.2 与监督学习的对比
监督学习:图像识别

网络训练中,是已经把真实的label给了网络,假设网络给了错误的决策,就会告诉它你错了。
有两个假设:
- data的数据是没有关联的
- 我们告诉了learner正确的label
强化学习:打砖块
- 不会得到立刻的反馈
- data之间是连续的
只有到最后游戏结束才有label,因此单个的action没有一个确切的label告诉你是否正确,存在奖励的延迟
对比:
- 强化学习是序列数据,监督学习样本之间是独立的
- learner并没有被告知正确的行为是什么,learner需要自己去发现哪些行为是可以得到最终的奖励的
- 强化学习是要通过不断的试错来获得能力(Trial-and-error exploration),平衡exploration(探索) 与 exploitation(开发) 的关系。
exploration(探索):通过尝试一些新的行为,这些行为可能让你获得更高的收益,也可能一无所有。
exploitation(开发) :采取已知的可以获得最大reward的action,重复这个行为。 - 没有一个监督者,只有奖励信号,且有延迟
- 强化学习过程中时间很重要,因为data间是有时间关联的,而不是i.i.d分布的
- 强化学习中agent的行为会影响他之后得到的数据,因此强化学习中很重要的是怎样使得agent的行为一直稳定的提升
为什么关注强化学习:
强化学习取得的结果可以有超人类的效果 ,监督学习是需要人类标定,因此永远不可能超越人类;而强化学习需要在环境中探索,有很大的潜力可以超越人类
AlphaGo:https://www.youtube.com/watch%3Fv=WXuK6gekU1Y
其他举例:
下棋,羚羊奔跑,股票交易
深度强化学习:
深度学习+强化学习
类比传统的CV和deep CV

通过训练一个整体的神经网络,使得它既可以做特征提取,又可以做分类。
传统RL与deep RL

Deep RL:直接输入状态,通过端到端神经网络来拟合直接得到action。
RL当今发展的优势:
- 更多的GPU支持trial-and-error的尝试
- 通过尝试可以使得agent能够在环境中获得更多的信息,获得更多的reward
- 端到端的训练,使得特征提取和价值估计可以一块优化
1.3 序列决策过程
1.3.1 介绍
强化学习研究的过程是agent和环境的交互

Reward(奖励)
- 标量反馈型号
- 决定了agent的某一时刻t做的动作是否得到奖励
- 强化学习的目的是极大化agent获得的reward
举例:
- 下棋的结果,胜负
- 股票,获得的收益或损失
- Atari游戏,是否获得分数
序列决策过程:
- 强化学习的目的是极大化agent获得的reward
- action有长期的影响
- reward有延迟
- 近期奖励和远期奖励之间的trade-off
- 可以把整个状态看成一个关于历史的函数

- 在agent内部,也有一个函数来更新状态。
- Full observability:当agent状态与环境状态等价的时候,我们就说这个环境是Full observability(全部可以观测)
- Partial observability: agent观测不能包含所有运作状态。(POMDP)
1.3.2 RL agent组成成分
- 决策函数(Policy function) :agent用来选取下一步的动作
- 价值函数(Value function):对当前状态进行估价,价值函数越大,说明你进入这个状态越有利
- 模型(Model):agent对于状态的理解,决定了它认为世界是怎样构成的
- Policy
- agent 行为,把输入的状态变成行为
- Stochastic policy(
π
\pi
π函数)

当你在状态s时,输出一个概率(所有行为的概率),然后进一步对概率分布进行采样,得到真实采取的行为。 - Deterministic policy:

采取极大化,采取最有可能的概率,是事先决定好了的。
- Value function
- 定义:一个折扣的未来奖励的加和,进行某一个行为未来将得到多大的奖励
- 折扣因子(Discount factor):由于我们希望尽可能在短的时间里面得到多的奖励,比如我们希望立刻得到一笔钱而不是以后。因此我们把折扣因子放入到价值函数中
- 价值函数的定义其实是一个期望,小标是Π函数,意味着在我们已知一个policy function的时候到底可以得到多少的奖励

- Q-function

s-状态,a-动作,Q函数是强化学习算法在学习的一个函数,是一个期望表示当前状态当前动作未来可以获得的奖励,得到Q函数后,进入某种状态的最优行为可以通过Q函数得到。
- Model
- 模型决定了下一个状态是什么样的
- 转移状态:状态是怎么转移的

- 奖励函数:当前状态采取某个行为可以得到多大的奖励

1.3.3 马尔可夫决策过程(MDPs)
这个决策过程可视化了状态之间的转移,以及之间采取的行为
之后详细讲解
1.3.4 示例:走迷宫

- 采取policy-based RL
知道每一个状态下最下的动作

- 采取Value-based RL
利用价值函数来导向,每一个状态会返回一个价值,越接近终点值越大

1.3.5 分类
-
基于价值函数的(Value-based) agent
- 简明学习:价值函数
- 隐式学习:策略(从价值函数中推断出来的)
-
基于策略的(Policy-based) agent
- 直接学习策略
- 没有价值函数
-
Actor-Critic agent
- 即学习了策略又学习了价值函数
-
Model-based
- 通过学习了状态转移来采取措施
-
Model-free
- 没有通过状态转移也没有学习价值函数
- 没有模型

1.3.6 探索与开发
- 强化学习是要通过不断的试错来获得能力(Trial-and-error exploration),平衡exploration(探索) 与 exploitation(开发) 的关系。
- exploration(探索):通过尝试一些新的行为,这些行为可能让你获得更高的收益,也可能一无所有。
- exploitation(开发) :采取已知的可以获得最大reward的action,重复这个行为。
1.4 RL代码实现
1.4.1 Python coding
- Deep learning libraries: PyTorch or TensorFlow
- https://github.com/metalbubble/RLexample
1.4.2 OpenAI
https://openai.com/
https://gym.openai.com/
https://github.com/openai/retro/tree/develop
1.4.3 测试案例
- Anaconda和OpenAI gym
- Download and install Anaconda here
- Install OpenAI gym
pip install gym
pip install gym[atari]
- Examples
- Play with the environment
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
- Random play with CartPole-v0
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
env.close()
- Example code for random playing (Pong-ram-v0,Acrobot-v1,Breakout-v0)
python my_random_agent.py Pong-ram-v0
- Very naive learnable agent playing
CartPole-v0orAcrobot-v1
python my_learning_agent.py CartPole-v0
- Playing Pong on CPU (with a great blog). One pretrained model is
pong_model_bolei.p(after training 20,000 episodes), which you can load in by replacing save_file in the script.
python pg-pong.py
- Random navigation agent in AI2THOR
python navigation_agent.py















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









