







周博磊老师课程:
https://www.bilibili.com/video/BV1LE411G7Xj?from=search&seid=16640883969039274910&spm_id_from=333.337.0.0
Github代码:
https://github.com/cuhkrlcourse/RLexample
强化学习
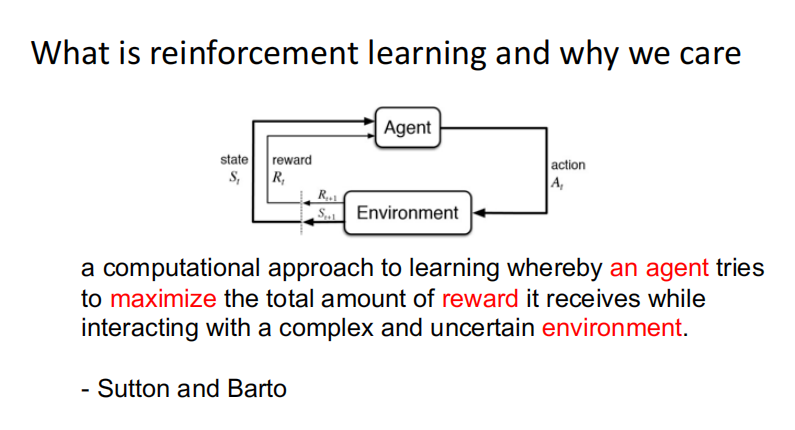
什么是强化学习:
智能体从环境中获得样例不断学习,获得样例后不断更新优化自己的模型参数,并利用模型来指导下一步的行为action,不断迭代后使得模型收敛,获得的reward最大化。
监督学习和强化学习的对比:
- 输入为序列数据
- 每一步的对错要通过奖励进行调整,所以需要不断地试错
- Trial-and-error不断试错,exploration尝试新的行为获得奖励;expoitation采取已知的获得最大奖励的行为
- 只有一个奖励信号,不能得到及时反馈,delayed reward
强化学习的特点:
-
Traial-and-error exploration 不断试错
-
Delayed reward 延迟奖励
-
Time matters 时间问题(强序列,无id data)
-
智能体的行为会影响即将得到的数据
强化学习一个重要的问题是如何使他稳定的学习,甚至能获得超人类的知识水平
强化学习的例子:
- 围棋
- 羚羊学跑步
- 股票序列
- 游戏
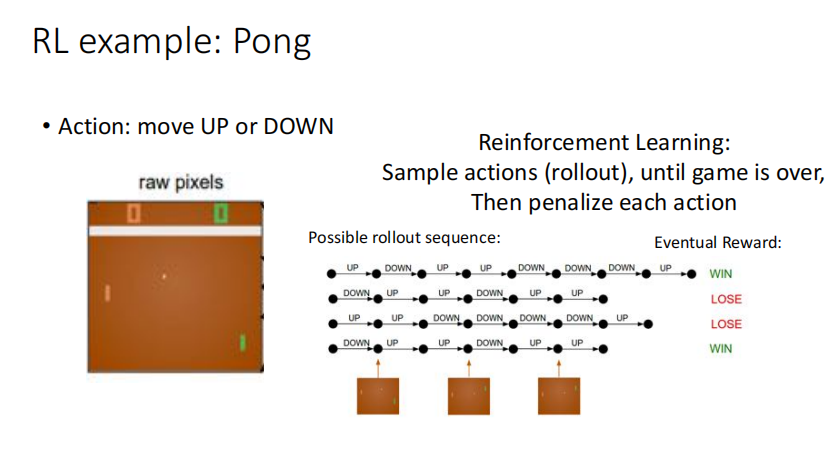
DRL:
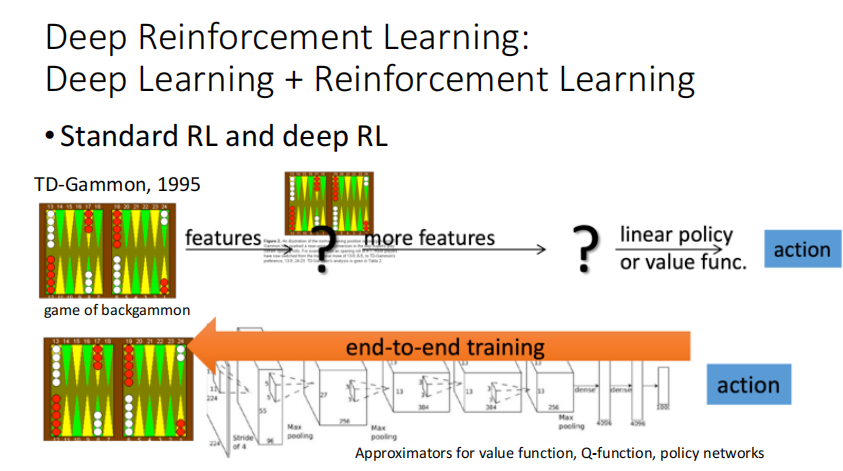
DRL快速发展:高算力+获得更高维的特征+端对端训练
Sequential Decision Making
关键问题:
- 学习的目的:选择一个行为序列使得未来总收益最大化
- 行为可能是一个长时间的序列
- 奖励的可能会被延迟
- 如何权衡即时奖励和长期奖励
agent和环境
Full observability:
agent可以观察到所有的环境(MDP)
Partial observability:
agent只能观察到部分的环境(POMDP)
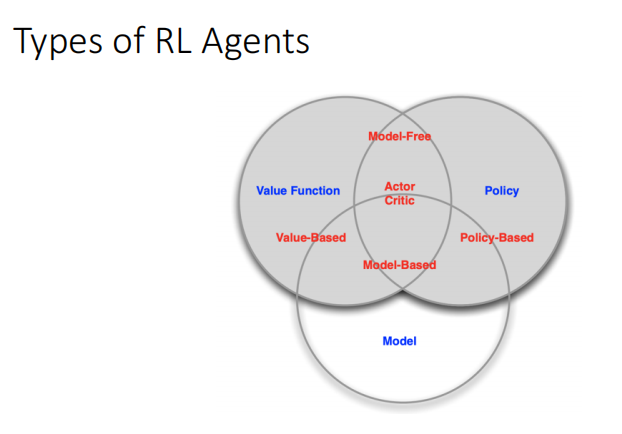
RL主要成分
-
Policy: agent’s behavior function (agent的行为)
-
Value function: how good is each state or action(某种策略下的累计期望收益)
-
Model: agent’s state representation of the environment



分类:


Exploration:探索尝试新的(试错)
Exploitation:选择已知奖励最大的行为
RL example:
https://github.com/metalbubble/RLexample
Exploitation:选择已知奖励最大的行为
















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











