







第一课上为综述
第一课(下)笔记
Sequntial Decision Making
奖励对Agent如何学习起到向导作用,如何设置reward是一门学问。
action造成的影响导致获得的奖励也许存在延迟,所以近期奖励和长期奖励的trade-off变得格外重要。
在RL中,history定义为observation、actions、rewards的序列
H
t
=
O
1
,
R
1
,
A
1
,
.
.
.
,
A
t
−
1
,
O
t
,
R
t
H_t = O_1, R_1, A_1, ... , A_{t-1}, O_t ,R_t
Ht=O1,R1,A1,...,At−1,Ot,Rt
一般来说下一个状态是
H
t
H_t
Ht的函数
S
t
=
f
(
H
t
)
S_t =f( H_t )
St=f(Ht)
其实State可以分为environment state和agent state(agent观测到的状态)
S
t
e
=
f
e
(
H
t
)
S^e_t = f^e(H_t)
Ste=fe(Ht)
S
t
a
=
f
a
(
H
t
)
S^a_t = f^a(H_t)
Sta=fa(Ht)
当
O
t
=
S
t
e
=
S
t
a
O_t =S^e_t = S^a_t
Ot=Ste=Sta的时候就是FOMDP(FO=full observability)或者简单直接说MDP
但是如果不能就是POMDP(Partial observability)比如斗地主。
Major Components of an RL Agent
一个Agent主要包括以下或者更多的组建:
- Policy策略
- Value fuction价值函数:对当前state的好坏估计
- model模型
Policy
Policy决定agent行为,有两种policy
- 概率型: π ( a ∣ s ) = P [ A t = a ∣ S t = s ] \pi(a|s) = P[A_t = a|S_t =s] π(a∣s)=P[At=a∣St=s]
- 确切型:
a
∗
=
arg max
a
π
(
a
∣
s
)
a^* = \underset a {\operatorname {arg\,max} } \pi(a|s)
a∗=aargmaxπ(a∣s)
DRL输入的S_t一般是一帧画面
Value fution
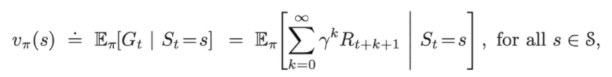 价值函数是折扣的未来奖励的加和,注意两个词:折扣和未来
价值函数是折扣的未来奖励的加和,注意两个词:折扣和未来
因为我们希望之后的奖励越快得到越好。
价值函数的意义是在我们已知一个policy的时候,在s此状态之后平均可以得到多少奖励。
我们还有一个Q函数,价值函数V函数是根据s和pi(Latex下为
π
\pi
π,之后为了方便,非latex下称pi)得到的平均回报,而Q函数是根据s和a(action,泛指当前状态i下选择的行为,省略下标
a
t
a_t
at)
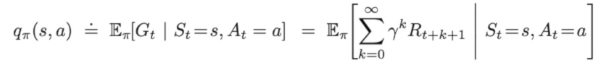 q函数也是ValueBase的RL算法学习的函数(或者说值)
q函数也是ValueBase的RL算法学习的函数(或者说值)
Model
模型是Agent脑海中对世界的建模,预测下一步环境的state和reward
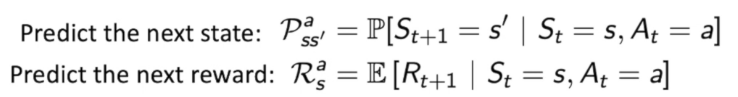
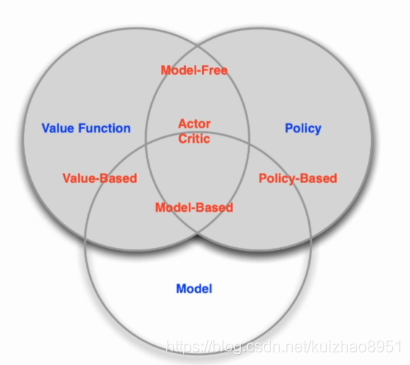
Valuebase和Policybase的差别
 Valuebase直接学习的是value,隐式学习policy
Valuebase直接学习的是value,隐式学习policy
policybase直接学习policy,不学习value function
还有一种结合Valuebase和policybase的方法:Actor-Critic agent
同时学习policy和value,通过两者的交互决定最佳的行为
还有一个分类准则是有无学习model
- model base
- model free
 强化学习中exploration探索和exploitaion趋利(直接选择当前已知最优)
强化学习中exploration探索和exploitaion趋利(直接选择当前已知最优)
实践
http://github.com/metalbubble/RLexample 里面有部分可供实践的代码
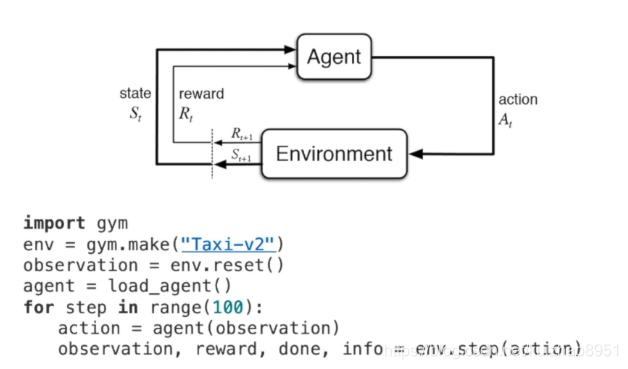 代码gitclone下来可以好好的研究一下。
代码gitclone下来可以好好的研究一下。
作业



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









