









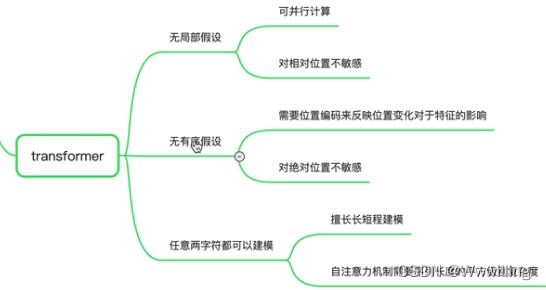
- Seq-to-Seq (encoder+attention+decoder)
- CNN

- RNN

- transformer
- CNN
Transformer


class Transformer



α
1
{\alpha}_1
α1就是
q
1
q_1
q1和
k
1
k_1
k1做点积然后softmax得到。
- self-attention
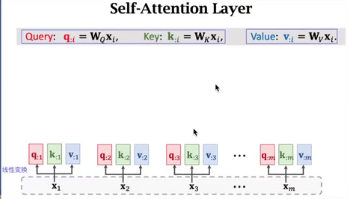
以 q 2 q_2 q2为例

q 2 q_2 q2和别的 k k k做点积,得到 α 1 . . . . α m {\alpha}_1....{\alpha}_m α1....αm

#########################################################
# 数据构建
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
device = 'cpu'
# transformer epochs
epochs = 100
# 德语转英语
sentences = [
# enc_input dec_input(训练时用) dec_output(目标句子)
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E'] # E 结束符 S 开始符 P 填充
]
# 输入序列和输出序列要分开建立词库
src_vocab = {'P':0,'ich':1,'mochte':2,'ein':3,'bier':4,'cola':5}
src_idx2word = {i:w for i,w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P':0,'i':1,'want':2,'a':3,'beer':4,'coke':5,'S':6,'E':7,'.': 8}
idx2word = {i:w for i,w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
# 输入输出长度可以不相同
src_len = 5
tgt_len = 6
# 参数
d_model = 512 # Embedding Size(token embedding 和 position 编码的维度)
d_ff = 2048 # Feedforward dimension(两次线性层中的隐藏层512-2048-512,线性层是用来做特征提取的)
d_k = d_v = 64 # dimension of K(=Q),V (Q和K的维度需要相同,这里为了方便让K=V)
n_layer = 6 # block的个数
n_heads = 8 # 有几套头,多套注意力机制发掘模型的关系
######################################
# 数据构建
def make_data(sentences):
# 把单词序列转换为数字序列
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
"""自定义DataLoader"""
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
# Transformer 模型
def get_attn_pad_mask(seq_q, seq_k):#第一个序列是扩展维度的,第二个序列才是有填充的序列
batch_size,len_q = seq_q.size()
batch_size,len_k = seq_k.size()
# 例如 seq_k = [[1,2,3,4,0],[1,2,3,5,0]],0是需要被mask的P,那么将0设为True,其余都设为0
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size,1,len_k],True is masked
return pad_attn_mask.expand(batch_size,len_q,len_k)
class PositionalEncoding(nn.Module):
def __init__(self,d_model,dropout=0.1,max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 在第1维(下标从0开始)上增加一维
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len,batch_size,d_model]
"""
x = x + self.pe[:x.size(0), :] # 输入直接加到位置编码
return self.dropout(x)
class ScaleDotProductAttention(nn.Module):
def __init__(self):
super(ScaleDotProductAttention,self).__init__()
# Q,V做点积,然后softmax,然后和V做加权平均
def forward(self,Q,K,V,attn_mask):
"""
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
说明:在encoder-decoder的Attention层中len_q(q1,..qt)和len_k(k1,...km)可能不同
"""
scores = torch.matmul(Q,K.transpose(-1,-2))/np.sqrt(d_k)
# mask矩阵填充scores(用-1e9填充scores中与attn_mask中值为1位置相对应的元素)
scores.masked_fill_(attn_mask,-1e9)# 把对应位置true的位置设成负无穷
attn = nn.Softmax(dim=-1)(scores)# 对最后一个维度(v)做softmax
# scores: [batch_size,n_heads,len_q,len_k]*V : [batch_size,n_heads,len_v(=len_k),d_v)
context = torch.matmul(attn,V) # context:[batch_size,n_heads,len_q,d_v]
# context:[[z1,z2,...],[...]]向量, attn注意力稀疏矩阵(用于可视化的)
return context,attn
class MultiHeadAttention(nn.Module):
"""这个Attention类可以实现:
Encoder的Self-Attention
Decoder的Masked Self-Attention
Encoder-Decoder的Attention
"""
def __init__(self):# 初始化一个大的参数矩阵
super(MultiHeadAttention,self).__init__()
self.W_Q = nn.Linear(d_model,d_k * n_heads,bias=False)#q,k必须维度相同
self.W_K = nn.Linear(d_model,d_k * n_heads,bias=False)
self.W_V = nn.Linear(d_model,d_v * n_heads,bias=False)
self.fc = nn.Linear(n_heads * d_v,d_model,bias=False) # 做线性变换
def forward(self,input_Q,input_K,input_V,attn_mask):
# 残差网络:将原来的输入保存到残差网络,保证不会比原来差
residual,batch_size = input_Q,input_Q.size(0) # residual原来的输入
# 下面的多头的参数矩阵是放在一起做线性变换的,然后再拆成多个头,这是工程实现的技巧
# B: batch_size, S:seq_len, D: dim
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, Head, W) -trans-> (B, Head, S, W)
# 线性变换 拆成多头
# Q:[batch_size,n_heads,len_q,d_k]
Q = self.W_Q(input_Q).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# K:[batch_size,n_hedas,len_k,d_k]# K和V的长度一定相同,维度可以不同
K = self.W_K(input_K).view(batch_size,-1,n_heads,d_k).transpose(1,2)
# V:[batch_size,n_heads,len_v(=len_k),d_v]
V = self.W_V(input_V).view(batch_size,-1,n_heads,d_v).transpose(1,2)
# mask矩阵也要扩充到4维
# attn_mask: [batch_size,seq_len,seq_len]->[batch_size,n_heads,seq_len,seq_len]
attn_mask = attn_mask.unsqueeze(1).repeat(1,n_heads,1,1)
# context:[batch_size,n_heads,len_q,d_v],attn:[batch_size,n_heads,len_q,len_k]
context,attn = ScaleDotProductAttention()(Q,K,V,attn_mask)
# 下面将不同头的输出向量拼接在一起
# context:[batch_size,n_heads,len_q,d_v]->[batch_size,len_q,n_leads * d_v]
context = context.transpose(1,2).reshape(batch_size,-1,n_heads * d_v)
# 再做一个projection
output = self.fc(context)# [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).to(device)(output+residual),attn # 残差连接
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet,self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model,d_ff,bias=False),
nn.ReLU(),
nn.Linear(d_ff,d_model,bias=False)
)
def forward(self,inputs):
"""
inputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).to(device)(output+residual) # [batch_size, seq_len, d_model] 残差连接
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer,self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs,enc_self_attn_mask):
"""E
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask or sequence mask)
"""
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
# 第一个enc_inputs * W_Q = Q
# 第二个enc_inputs * W_K = K
# 第三个enc_inputs * W_V = V
enc_outputs,attn = self.enc_self_attn(enc_inputs,enc_inputs,enc_inputs,enc_self_attn_mask) # enc_inputs to same Q,K,V(未线性变换前)
enc_outputs = self.pos_ffn(enc_outputs)# 全连接层
return enc_outputs,attn
class Encoder(nn.Module):
def __init__(self):
super(Encoder,self).__init__()
self.src_emb = nn.Embedding(src_vocab_size,d_model)# 把词转化成embedding向量,需要学习
self.pos_emb = PositionalEncoding(d_model)# Transformer中位置编码是固定的,不需要学习
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layer)])# 将一个block串到一起
def forward(self,enc_inputs):
"""Transformers的输入:两个序列
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
"""
enc_outputs = self.src_emb(enc_inputs) # [batch_size,src_len(单词长度),d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0,1)).transpose(0,1) #[batch_size,src_len,d_model] position_embedding 和src_emb 维度一样,直接相加了
# 在Encoder输入序列的pad mask矩阵,用于把‘P’的注意力去掉(无意义)
enc_self_attn_mask = get_attn_pad_mask(enc_inputs,enc_inputs)
enc_self_attns = []# 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系
for layer in self.layers:# for循环访问nn.ModelList的对象
# 上一个block的输出enc_output作为当前block的输入
# enc_outputs:[batch_size,src_len,d_model],enc_self_attn:[batch_size,n_heads,src_len,src_len]
enc_outputs,enc_self_attn = layer(enc_outputs,enc_self_attn_mask)# 传入的enc_outputs其实是input,出入mask矩阵是因为要做self-attention
enc_self_attns.append(enc_self_attn) # 这个只是为了可视化
return enc_outputs,enc_self_attns
def get_attn_subsequence_mask(seq):
attn_shape = [seq.size(0),seq.size(1),seq.size(1)]
#attn_shape:[batch_size,tgt_len,tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape),k=1)# 生成一个上三角为1的矩阵,np.triu (a, k)是取矩阵a的上三角数据,但这个三角的斜线位置由k的值确定
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # torch.from_numpy()方法把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变。
return subsequence_mask
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer,self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self,dec_inputs,enc_outputs,dec_self_attn_mask,dec_enc_attn_mask):
"""
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
"""
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs,dec_self_attn = self.dec_self_attn(dec_inputs,dec_inputs,dec_inputs,dec_self_attn_mask)# 这里的Q,K,V全是Decoder自己的输入
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs,dec_enc_attn = self.dec_enc_attn(dec_outputs,enc_outputs,enc_outputs,dec_enc_attn_mask)# Attention层的Q(来自decoder) 和 K,V(来自encoder)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs,dec_enc_attn,dec_enc_attn # dec_self_attn, dec_enc_attn这两个是为了可视化的
class Decoder(nn.Module):
def __init__(self):
super(Decoder,self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size,d_model)# Decoder输入的embed词表
self.pos_emb = PositionalEncoding(d_model)# 位置编码
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layer)])# Decoder的6个block
def forward(self,dec_inputs,enc_inputs,enc_outputs):
"""
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model] # 用在Encoder-Decoder Attention层
"""
# 和Encorder类似
dec_outputs = self.tgt_emb(dec_inputs)
dec_outputs = self.pos_emb(dec_outputs.transpose(0,1)).transpose(0,1).to(device)
# Decoder输入序列的pad mask矩阵(这个例子中decoder是没有加pad的,实际应用中都是有pad填充的)
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs,dec_inputs).to(device)
# Masked Self-attention 当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(device) # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask+dec_self_attn_subsequence_mask),0).to(device)
# 两个mask相加,如果大于0返回1,之后再赋值负无穷
# gt(a,b)函数比较a中元素大于(这里是严格大于)b中对应元素,大于则为1,不大于则为0,
# 这个mask主要用于encoder-decoder attention层
# get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量)
# dec_inputs只是提供expand的size的
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs,enc_inputs)# [batc_size, tgt_len, src_len]
# 接下来与Encoder类似
dec_self_attns,dec_enc_attns = [],[]
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
# Decoder的Block是上一个Block的输出dec_outputs(变化)和Encoder网络的输出enc_outputs(固定)
dec_outputs,dec_self_attn,dec_enc_attn = layer(dec_outputs,enc_outputs,dec_self_attn_mask,dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs,dec_self_attns,dec_enc_attns
class Transformer(nn.Module):
def __init__(self):
super(Transformer,self).__init__()
self.encoder = Encoder().to(device)
self.decoder = Decoder().to(device)
self.projection = nn.Linear(d_model,tgt_vocab_size,bias=False).to(device)
def forward(self,enc_inputs,dec_inputs):
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
# 经过Encoder网络后,得到的输出还是[batch_size, src_len, d_model]
enc_outputs,enc_self_attns = self.encoder(enc_inputs)# enc_self_attens是为了可视化参数
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs,dec_self_attns,dec_enc_attns = self.decoder(dec_inputs,enc_inputs,enc_outputs)
# dec_outputs: [batch_size, tgt_len, d_model] -> dec_logits: [batch_size, tgt_len, tgt_vocab_size]
dec_logits = self.projection(dec_outputs) # 用贪心解码得到下一个单词
return dec_logits.view(-1,dec_logits.size(-1)),enc_self_attns,dec_self_attns,dec_enc_attns
#########################################
# 模型的训练
model = Transformer().to(device)
# 这里的损失函数里面设置了一个参数 ignore_index=0,因为 "pad" 这个单词的索引为 0,这样设置以后,就不会计算 "pad" 的损失(因为本来 "pad" 也没有意义,不需要计算)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(),lr=1e-3,momentum= 0.99)
# 每个输出都算一个loss,全加起来
for epoch in range(epochs):
for enc_inputs,dec_inputs,dec_outputs in loader:
enc_inputs,dec_inputs,dec_outputs = enc_inputs.to(device),dec_inputs.to(device),dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs,enc_self_attns,dec_self_attns,dec_enc_attns = model(enc_inputs,dec_inputs)
loss = criterion(outputs,dec_outputs.view(-1))# dec_outputs.view(-1):[batch_size * tgt_len * tgt_vocab_size]
print('Epoch:','%04d' % (epoch+1),'loss=','{:.6f}'.format(loss))
optimizer.zero_grad()#根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。
loss.backward()# 计算导数
optimizer.step()# 更新模型
def greedy_decoder(model, enc_input, start_symbol):
"""贪心编码
For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
:param model: Transformer Model
:param enc_input: The encoder input
:param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
:return: The target input
"""
enc_outputs,enc_self_attns = model.encoder(enc_input)
dec_input = torch.zeros(1,0).type_as(enc_input.data)
terminal = False
next_symbol = start_symbol
while not terminal:
# 预测阶段:dec_input序列会一点点变长(每次添加一个新预测出来的单词)
dec_input = torch.cat([dec_input.to(device),torch.tensor([[next_symbol]],dtype=enc_input.dtype).to(device)],-1)
dec_outputs,_,_ = model.decoder(dec_input,enc_input,enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1,keepdim=False)[1]
# 增量更新(我们希望重复单词预测结果是一样的)
# 我们在预测是会选择性忽略重复的预测的词,只摘取最新预测的单词拼接到输入序列中
next_word = prob.data[-1]# 拿出当前预测的单词(数字)。我们用x'_t对应的输出z_t去预测下一个单词的概率,不用z_1,z_2..z_{t-1}
next_symbol = next_word
if next_symbol == tgt_vocab["E"]:
terminal = True
greedy_dec_predict = dec_input[:,1:]
return greedy_dec_predict
#################################################
# 预测阶段
enc_inputs,_,_ = next(iter(loader))
for i in range(len(enc_inputs)):
greedy_dec_predict = greedy_decoder(model,enc_inputs[i].view(1,-1).to(device),start_symbol = tgt_vocab["S"])
print(enc_inputs[i],'->',greedy_dec_predict.squeeze())
print([src_idx2word[t.item()] for t in enc_inputs[i]], '->',[idx2word[n.item()] for n in greedy_dec_predict.squeeze()])















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









