







对必联网的url分析
该项目对招标信息网:必联网,进行爬取,要求如下:
汇总要求:每日16点汇总招标数据,更新最终项目动态,多个第三方网站取 得的相同项目需要去重,且保证项目信息的时效性。
首先我们在必联网创建用户,随后在关键字搜索中输入“路由器”进行搜索,得到一个搜索结果页面,通过url地址我们可以发现,搜索结果的第一页是一个GET请求
接下来我们查看第二页:
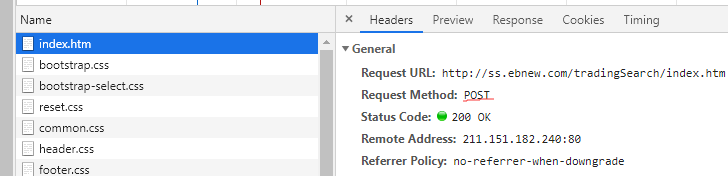
可以看到,第二页是一个POST请求,我们对第二页的Request Headers进行分析:

我们可以看到,要访问到这个页面,需要有相应的Cookie和User-Agent,以及在下面有一个Form表单提交数据,再对这个Form表单进行分析:

我们可以看到两个熟悉的标签,key和currentPage,很明显,这两个就是我们的搜索关键字和当前页码。
这样,我们就完成了对一级页面的分析,我们继续分析二级页面,点进一个招标详情查看二级页面:
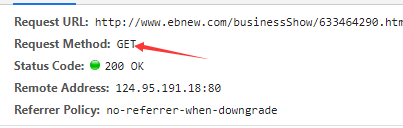
可以看到是一个GET请求,所以,我们通过url地址就可以找到对应的数据,这样,就完成了对二级页面的分析。
接下来我们通过Postman测试一下一级页面的获取数据,即将一级页面中的Form表单中的键值队粘贴进Postman,查看能否获取正确的页面:


(记得添加请求头)
在Postman中获得页面的body,可以在body中搜索项目名称,看能否得到,得到则说明页面一致。
总结一下,一级页面是POST请求,通过传递Cookie,User-Agent,Form表单进行访问,二级页面可以直接爬取。
标题创建项目并配置请求头与代理IP
流程图:

代码实例:
1、通过命令行创建scrapy项目,创建zhaobiao项目名及‘bilian’爬虫,爬取页面"ebnew".
2、将robot协议改写为False,取消DOWNLOAD_DELAY,DEFAULT_REQUEST_HEADERS,DOWNLOADER_MIDDLEWARES,ITEM_PIPELINES的注释,并对请求头DEFAULT_REQUEST_HEADERS进行配置,将必联网一级页面中的Cookie和User-Agent配置:
DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 'Cookie': '__cfduid=d8d40340380dc8827aeb2dbaa0b9318521568293861; Hm_lvt_ce4aeec804d7f7ce44e7dd43acce88db=1568293866; _cookie_from_source=""; supplier_token=%E7%99%BD%E6%B6%9B#13#4956b0d62a634905826b8b34ec1c186f; loginUser=B_tao; userType=13; JSESSIONID=463500B6C973D96470BA162DE56DA142; Hm_lpvt_ce4aeec804d7f7ce44e7dd43acce88db=1568298156', }
然后添加代理IP:在middlewares下的process_request中,我们添加代理IP服务:request.meta['proxy'] = 'http://' + ur.urlopen( 'http://api.ip.data5u.com/dynamic/get.html?order=be26b6c7f3ba0572251da6f613cb9926&sep=3').read().decode( 'utf-8').strip()
这样就可以通过代理IP访问目标url。
3、首先,我们要明确自己需要爬取的信息,因此,我们在bilian.py这个spider中的BilianSpider类下创建我们需要存储的数据格式,以及我们访问页面需要提交的Form表单,创建如下:
class BilianSpider(scrapy.Spider):
name = 'bilian'
allowed_domains = ['ebnew']
# 存储的数据格式
sql_data = dict(
projectcode='', # 项目编号
web='', # 信息来源网站
keyword='', # 关键字
detail_url='', # 招标详细页网址
title='', # 第三方网站发布标题
toptype='', # 信息类型
province='', # 归属省份
product='', # 产品范畴
industry='', # 归属行业
tendering_manner='', # 招标方式
publicity_date='', # 招标公示日期
expiry_data='', # 招标截止时间
)
# Form表单的数据格式
form_data = dict(
infoClassCodes='',
rangeType='',
projectType='bid',
fundSourceCodes='',
dateType='',
startDateCode='',
endDateCode='',
normIndustry='',
normIndustryName='',
zone='',
zoneName='',
zoneText='',
key='', # 搜索的关键字
pubDateType='',
pubDateBegin='',
pubDateEnd='',
sortMethod='timeDesc',
orgName='',
currentPage='', # 当前页码
)
4、接下来,我们在这个类中定义start_request函数和用于保存回传的response函数:
def start_requests(self):
"""提交表单数据"""
form_data = self.form_data # 引入Form表单
# 根据我们要搜索的关键字和页面修改Form表单
form_data['key'] = '消防柜'
form_data['currentPage'] = '2'
yield scrapy.FormRequest(
url='http://ss.ebnew.com/tradingSearch/index.htm',
formdata=form_data,
callback=self.parse_page1,
)
def parse_page1(self, response):
"""保存爬取的html文件"""
with open('2.html', 'wb') as f:
f.write(response.body)
5、在spider下创建start.py文件用于运行爬虫:
from scrapy import cmdline
cmdline.execute('scrapy crawl bilian'.split())
运行后,在spiders下就多了一个2.html文件,就是我们的一级页面文件。
对页面的数据进行过滤和提取
流程图:
代码实例:
1、定义一个函数,首先在这个函数中通过Xpath语句得到一个包含所有信息的列表,我们对这个列表进行遍历,对得到的数据进行过滤和提取:
def parse_page1(self, response):
"""一级页面中的数据过滤提取"""
content_list_x_s = response.xpath('//div[@class="ebnew-content-list"]/div') # 取得一个页面中所需要的全部信息
# 对页面遍历,分别取出对应的信息
for content_list_x in content_list_x_s:
# 取出信息
toptype = content_list_x.xpath('./div[1]/i[1]/text()').extract_first()
title = content_list_x.xpath('./div[1]/a[1]/text()').extract_first()
publicity_date = content_list_x.xpath('./div[1]/i[2]/text()').extract_first()
# 过滤字段名
if publicity_date:
publicity_date = re.sub('[^0-9\-]', ' ', publicity_date)
tendering_manner = content_list_x.xpath('./div[2]/div[1]/p[1]/span[2]/text()').extract_first()
product = content_list_x.xpath('./div[2]/div[1]/p[2]/span[2]/text()').extract_first()
expiry_date = content_list_x.xpath('./div[2]/div[2]/p[1]/span[2]/text()').extract_first()
# 过滤掉过期时间中的小时分钟秒
if expiry_date:
expiry_date = re.findall('\d{4}-\d{2}-\d{2}', expiry_date)[0]
province = content_list_x.xpath('./div[2]/div[2]/p[2]/span[2]/text()').extract_first()
# print(toptype, title, publicity_date, tendering_manner, product, expiry_date, province)
2、定义一个二级页面,同样得到信息的列表并且遍历:
def parse_page2(self, response):
li_x_s = response.xpath('//ul[contains(@class,"ebnew-project-information")]/li')
projectcode = li_x_s[0].xpath('./span[2]/text()').extract_first()
if not projectcode:
projectcode_find = re.findall('项目编号[::]{0,1}\s{0,3}([a-zA-Z0-9\-_]{10.30})', response.body.decode('utf-8'))
projectcode = projectcode_find[0] if projectcode_find else ""
industry = li_x_s[7].xpath('./span[2]/text()').extract_first()
tendering_manner = li_x_s[2].xpath('./span[2]/text()').extract_first()
expiry_date = li_x_s[3].xpath('./span[2]/text()').extract_first()
province = li_x_s[5].xpath('./span[2]/text()').extract_first()
product = li_x_s[6].xpath('./span[2]/text()').extract_first()
print(projectcode, expiry_date, province, product)
注:由于二级页面比较简单,它的信息都其实都保存在一个ul标签下的li标签中,所以我们对得到的列表直接遍历即可
随后,我们的得到的信息进行输出,查验是否正确。
异常请求写入LOG日志
在settings中配置LOG日志:
LOG_FILE = 'zhaobiao.log'
LOG_LEVEL = 'ERROR'
对请求链进行优化
链式请求由于上一条请求的结果会影响下一条请求,而且由于是顺序执行,所以运行速度也还会慢很多,因此,我们采用循环的方式对请求链进行优化
流程图:

代码实例:
1、创建start_requests,通过对关键字列表的循环实现对不同关键字的查询页面访问
def start_requests(self):
for keyword in self.keyword_s:
form_data = deepcopy(self.form_data) # 深拷贝
form_data['key'] = keyword
form_data['currentPage'] = '1'
request = scrapy.FormRequest(
url='http://ss.ebnew.com/tradingSearch/index.htm',
formdata=form_data,
callback=self.parse_start
)
request.meta['form_data'] = form_data # 将这个页面的form_data保存在meta中,以方便接下来调用
yield request
2、创建parse_start,实现循环体的创建,获取搜索页面的总页数,对总页数遍历,获得所有的一级页面
def parse_start(self, response):
a_text_s = response.xpath('//form[@id="pagerSubmitForm"]/a/text()').extract()
page_max = max(
[int(a_text) for a_text in a_text_s if re.match('\d+', a_text)]
)
page_max = 2 # 测试用,所以只取2页
self.parse_page1(response)
for page in range(2, page_max + 1):
form_data = deepcopy(response.meta['form_data'])
form_data['currentPage'] = str(page)
request = scrapy.FormRequest(
url='http://ss.ebnew.com/tradingSearch/index.htm',
formdata=form_data,
callback=self.parse_page1
)
request.meta['form_data'] = form_data
yield request
3、创建parse_page1,用于对一级页面的数据清洗,并且得到二级页面的地址,然后返回一个request请求,访问二级页面
def parse_page1(self, response):
"""一级页面中的数据过滤提取"""
form_data = response.meta['form_data']
keyword = form_data.get('key')
content_list_x_s = response.xpath('//div[@class="ebnew-content-list"]/div') # 取得一个页面中所需要的全部信息
# 对页面遍历,分别取出对应的信息
for content_list_x in content_list_x_s:
# 取出信息
sql_data = deepcopy(self.sql_data)
sql_data['toptype'] = content_list_x.xpath('./div[1]/i[1]/text()').extract_first()
sql_data['title'] = content_list_x.xpath('./div[1]/a[1]/text()').extract_first()
sql_data['publicity_date'] = content_list_x.xpath('./div[1]/i[2]/text()').extract_first()
# 过滤字段名
if sql_data['publicity_date']:
sql_data['publicity_date'] = re.sub('[^0-9\-]', ' ', sql_data['publicity_date'])
sql_data['tendering_manner'] = content_list_x.xpath('./div[2]/div[1]/p[1]/span[2]/text()').extract_first()
sql_data['product'] = content_list_x.xpath('./div[2]/div[1]/p[2]/span[2]/text()').extract_first()
sql_data['expiry_date'] = content_list_x.xpath('./div[2]/div[2]/p[1]/span[2]/text()').extract_first()
# 过滤掉过期时间中的小时分钟秒
if sql_data['expiry_date']:
sql_data['expiry_date'] = re.findall('\d{4}-\d{2}-\d{2}', sql_data['expiry_date'])[0]
sql_data['province'] = content_list_x.xpath('./div[2]/div[2]/p[2]/span[2]/text()').extract_first()
sql_data['detail_url'] = content_list_x.xpath('./div[1]/a/@href').extract_first()
sql_data['keyword'] = keyword
sql_data['web'] = '必联网 '
request = scrapy.Request(
url=sql_data['detail_url'],
callback=self.parse_page2
)
request.meta['sql_data'] = sql_data
yield request
4、创建parse_page2,用于对二级页面的数据清洗:
def parse_page2(self, response):
sql_data = response.meta['sql_data']
li_x_s = response.xpath('//ul[contains(@class,"ebnew-project-information")]/li')
sql_data['projectcode'] = li_x_s[0].xpath('./span[2]/text()').extract_first()
if not sql_data['projectcode']:
projectcode_find = re.findall('项目编号[::]{0,1}\s{0,3}([a-zA-Z0-9\-_]{10.30})', response.body.decode('utf-8'))
sql_data['projectcode'] = projectcode_find[0] if projectcode_find else ""
sql_data['industry'] = li_x_s[7].xpath('./span[2]/text()').extract_first()
sql_data['tendering_manner'] = li_x_s[2].xpath('./span[2]/text()').extract_first()
sql_data['expiry_date'] = li_x_s[3].xpath('./span[2]/text()').extract_first()
sql_data['province'] = li_x_s[5].xpath('./span[2]/text()').extract_first()
sql_data['product'] = li_x_s[6].xpath('./span[2]/text()').extract_first()
print('parse_2', sql_data)
yield sql_data
这样,我们通过循环体便完成了对请求链的优化,让每一个请求链独立出来,互不影响,达到了异步的作用。这其中要注意由于scrapy是一个异步的框架,可以理解为多线程。多线程在操作同一个内存地址的对象时很有可能出现问题,所以,对form_data的调用我们采用了深拷贝。另外,对上一次请求的form_data表单的拿取,我们可以通过request.meta[‘sql_data’]和response.meta[‘sql_data’]实现拿取。
将爬取的数据保存在Mysql中
pymysql可以通过python来操作Mysql数据库,一种轻量级的操作
pymysql操作:

流程图:

代码实例:
1、将提取后的数据交给管道文件
yield sql_data
在piplines中,我们创建Mysql的连接对象:
import pymysql
class ZhaobiaoPipeline(object):
def __init__(self):
self.mysql_conn = pymysql.Connection(
host='localhost',
port=3306,
user='root',
password='',
database='zhaobiao',
charset='utf8'
)
2、创建相应的数据库和数据表,用来存放爬取到的信息
3、在piplines中的process_item方法中创建光标对象:
def process_item(self, item, spider):
# 创建光标对象
cs = self.mysql_conn.cursor()
sql_column = ','.join([key for key in item.keys()])
sql_value = ','.join(['"%s"' % item[key] for key in item.keys()])
sql_str = 'insert into t_zhaobiao (%s) value (%s);' % (sql_column, sql_value)
cs.execute(sql_str)
self.mysql_conn.commit()
return item
运行之后查看数据表t_zhaobiao,可以看到,数据被存放在数据表中
通过Scrapy-Redis实现分布式架构
在以往的访问中,我们的访问都需要经过代理IP,但是,对于访问第三方的URL接口,返回时间都不确定,另外,如果爬取的速度过快,对这个接口造成的压力也比较大。因此,我们可以把代理IP写在本地的redis服务器中,并设置一个python文件,使这个python文件可以更新redis服务器中的代理IP。
Scrapy-Redis的配置

流程图:

代码实例:
1、set方法中,判断两次之间的代理IP是否相同,不同则更新:
def set_proxy(self):
proxy_old = None
while True:
proxy_new = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=be26b6c7f3ba0572251da6f613cb9926&sep=3').read().decode('utf-8').strip().split()
# 判断两次之间的代理IP是否相同,不同则更新
if proxy_old != proxy_new:
proxy_old = proxy_new
self.redis_conn.delete('proxy')
self.redis_conn.sadd('proxy', *proxy_new)
print("更换代理IP为:", proxy_new)
time.sleep(2)
else:
time.sleep(1)
2、get方法中,对于proxy_s列表不能直接取第0个元素,因为在异步中,上一个方法set有可能刚刚将这个列表更新,会清空这个列表,这个时候取第0个元素,可能会异常。所以我们加入一个判断,若proxy_s存在,则取其中第0个元素,若不存在,延时0.1S后再取。
3、proxyPool完整代码如下:
import redis
import urllib.request as ur
import time
class ProxyPool():
def __init__(self):
self.redis_conn = redis.StrictRedis(
host="localhost",
port=6379,
decode_responses=True,
)
def set_proxy(self):
proxy_old = None
while True:
proxy_new = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=be26b6c7f3ba0572251da6f613cb9926&sep=3').read().decode('utf-8').strip().split()
# 判断两次之间的代理IP是否相同,不同则更新
if proxy_old != proxy_new:
proxy_old = proxy_new
self.redis_conn.delete('proxy')
self.redis_conn.sadd('proxy', *proxy_new)
print("更换代理IP为:", proxy_new)
time.sleep(2)
else:
time.sleep(1)
def get_proxy(self):
proxy_s = self.redis_conn.srandmember('proxy',1)
# 对于列表proxy_s可能为空,采取保护机制
if proxy_s:
return proxy_s[0]
else:
time.sleep(0.1)
return self.get_proxy()
#测试用
if __name__ == '__main__':
ProxyPool().set_proxy()
# ProxyPool().get_proxy()
这样,我们就完成了通过scrapy-redis分布式架构对网站的爬取!
相关代码资源
资源已失效















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









