







总体背景:在DCNN中主要存在以下三个问题:
(1)池化或者下采样操作会导致图像分辨率下降,从而损失图片信息;
(2)空间不敏感性(不变性)
(3)存在多个尺度对象
DeepLab V1
主要的创新点是:
(1)用空洞卷积解决图像分辨率下降的问题
(2)用条件随机场(CRF)解决了边界分割不精确的问题。
条件随机场不了解,所以不过多描述。
空洞卷积
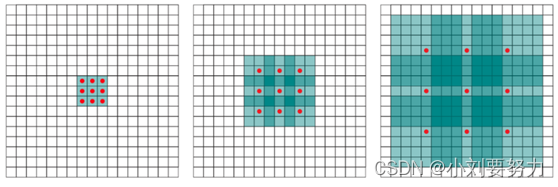
(1)左图是普通卷积,此时的dilate reate=1,卷积核的感受野是3x3
(2)中间图的dilate rate=2,卷积核的感受野为7x7
(3)右图是rate=4的空洞卷积,卷积核的感受野为15x15
感受野计算:
R
F
l
+
1
=
R
F
l
+
(
k
e
r
n
e
l
.
s
i
z
e
−
1
)
∗
s
t
r
i
d
e
RF_l+1=RF_l+(kernel .size-1)*stride
RFl+1=RFl+(kernel.size−1)∗stride
空洞率对应卷积核尺寸计算:
k
n
e
w
=
k
o
r
i
+
(
k
o
r
i
−
1
)
(
r
a
t
e
−
1
)
k_{new}=k_{ori}+(k_{ori}-1)(rate-1)
knew=kori+(kori−1)(rate−1)
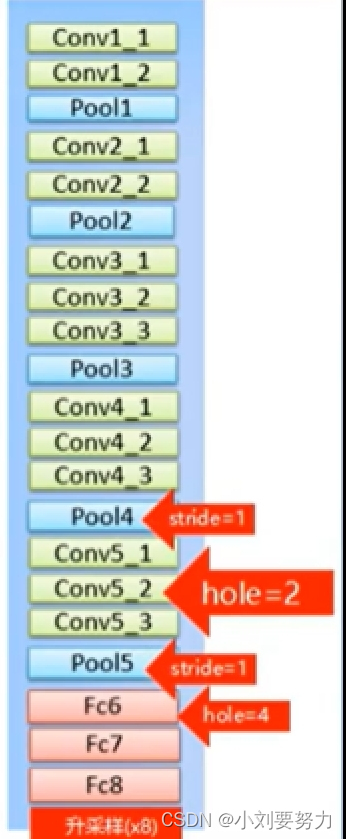
DeepLab V1以VGG16为backbone,并对其做出了以下改变:
(1)将fc层改成了卷积层;
(2)把最后两个池化层的步长由2改为1;
(3)将最后3个卷积层(conv5_1,conv5_2,conv5_3)的空洞率(dilate rate)设为2,且第一个全连接层的空洞率设为4(目的:保持感受野)
具体如下图所示
DeepLab V2
相较于DeepLab v1,DeepLab v2提出了多孔空间金字塔池化(ASPP),并且以ResNet作为backbone。
SPP模块(空间金字塔池化)
论文:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
SPPNet提出的初衷是为了解决CNN对图片输入尺寸的限制。由于全连接层的存在,与之相连的最后一个卷积层的输出特征需要固定的尺寸,因此要求输入图片的尺寸也要固定。常用的方法就是对图片进行裁剪或者变形,但是这两种方法会导致图片信息确实或变形影响识别精确度。
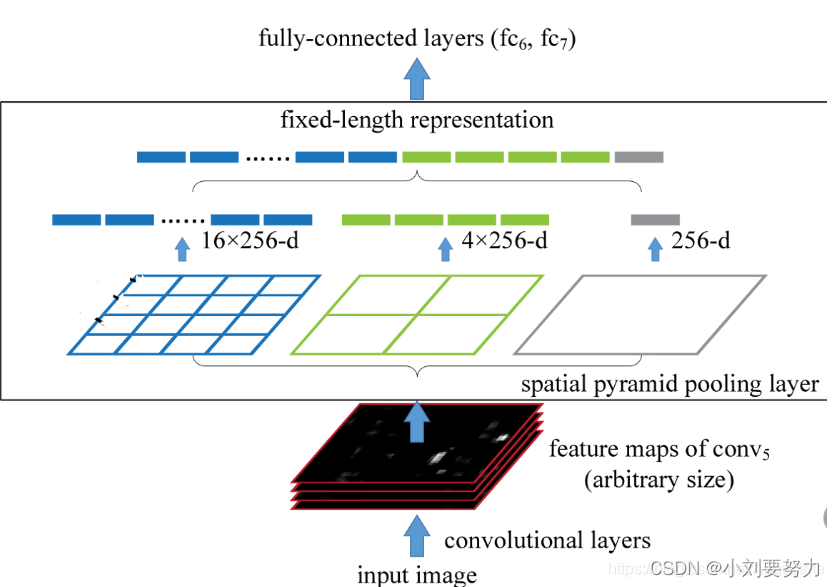
由图可见con5得到的特征图进行SPP层,进行不同尺度的池化即图中蓝色,青绿,银灰的窗口,蓝色窗口池化核为4x4,将特征图分成了16个块;青绿色窗口池化核为2 x 2 , 将特征图分成了4个块,银灰窗口池化核为1x1,将特征图分成了1个块,最后将不同尺度得到的特征拼接得到固定长度的特征向量,送入全连接层进行后续操作。
ASPP模块
受SPP启发,ASPP对所给定的输入用不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文,然后对每个采样率提取的特征在单独的分支中进一步处理并融合以生成最终结果,结构如下图所示:
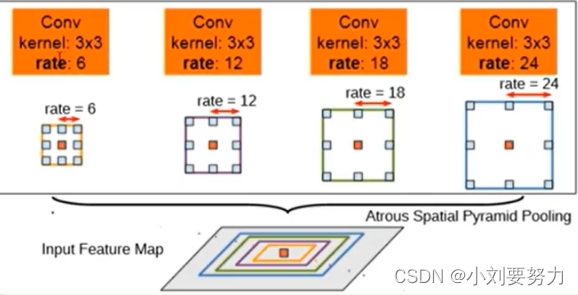
个人理解ASPP模块就是空洞卷积+SPP。















 1883
1883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









