






1、监督学习:算法处理有标记的数据,无监督学习:处理的数据都是未经过标记的,在线学习、批量学习。
2、过拟合:过度概括,欠拟合:模型过于简单。
机器学习的主要挑战是数据的缺乏,数据质量差,代表性不足,信息量不足,模型过拟合、欠拟合。
超参数调整和模型选择
训练两个模型,对比他们对不同测试集的数据泛化能力。但是为了避免过拟合,必须调整不同的超参数,正则化超参数的值。但是你在同一个测试集上一直调整超参数最后得到一个误差很小的模型,这个模型可能对于新数据集的表现可能很差。
保持验证:将训练集分为两部分,一部分用来训练,训练具有各种超参数的多个模型,并且将这些模型在另一部分(验证集)上验证模型效果。
如果你对数据绝 对没有任何假设,那么就没有理由更偏好于某个模型,这称为没有免 费的午餐(No Free Lunch,NFL)定理。
开始设计系统。首先,你需要回答框架问题:是有监督学习、无监督学习还是强化学习?是分类任务、回归任务还是其他任务?应该使用批量学习还是在线学习技术?如果数据庞大,则可以跨多个服务器拆分批处理学习(使用 MapReduce技术)或使用在线学习技术。
检测指标:RMSE:均方根误差
MAE: 平均绝对误差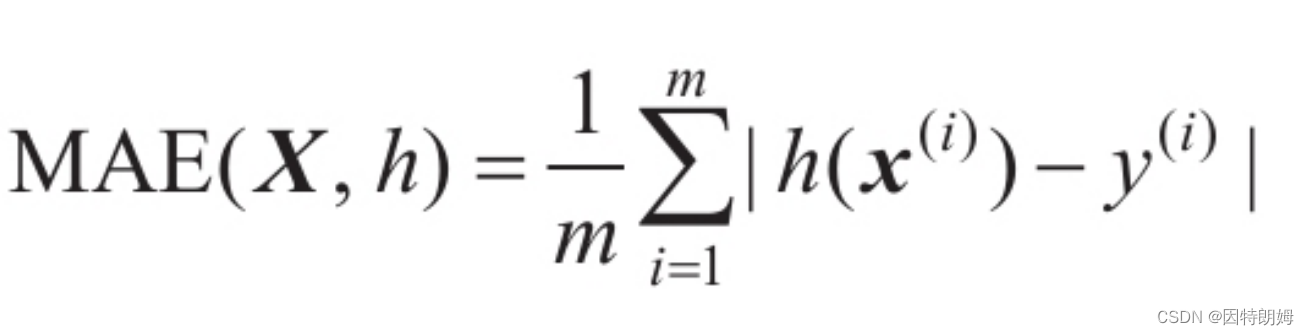
rmse其实是2范数,mae是1范数,k范数;![]()
k越大,对大值的变化越敏感,因此rmse对于异常值的敏感性较好。
















 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











