







一、论文简述
1. 第一作者:Shaoqian Wang、Bo Li
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:MVS、深度学习、动态代价体、GRU、迭代优化
5. 探索动机:由于正则化步骤需要较多的GPU内存和处理时间,因此现有方法只能处理低分辨率的图像。显然除了提高重建质量外,减少运行时间和GPU内存消耗也是非常重要的,这使得基于学习的MVS能够适应内存和计算有限的设备。
6. 工作目标:提高高分辨率MVS的计算速度并减少内存消耗,同时保证较高的重建质量。
7. 核心思想:
- 提出了一种新的非常轻量级的动态代价体,可以通过基于二维卷积的GRU迭代处理,并且在几个迭代步骤中即可收敛。因此避免了大尺寸静态代价体的内存和时间的开销问题。迭代和动态处理可以保证较大的搜索空间,这对精度至关重要。
- 提出了一种级联和分层的改进结构,利用多尺度信息,加快收敛速度。与之前的方法比较,进一步缩小了代价体的大小,并将多阶段策略推广为迭代的方式。特别是通过使用轻量级3D CNN,为GRU提供了可靠的初始的代价体,这是快速收敛和最终性能的关键。
- 该方法可以用于高分辨率的图像,可以通过在测试阶段调整迭代次数来更好地平衡精度和效率。
8. 实验结果:在DTU和Tanks & Temples基准上的大量实验表明,该方法在准确性、速度和内存方面可以达到最先进的结果。下图为在DTU数据集上该方法与其他方法的比较。运行时间(左)和GPU内存消耗(右)的Overall Error的准确性。图像分辨率为1600×1184。“iter”表示每个阶段的迭代次数。

9. 论文下载:
https://github.com/bdwsq1996/Effi-MVS
二、实现过程
1. Efficient MVS概述
Efficient MVS由多尺度特征提取器和基于GRU的优化器组成,该优化器包括动态代价体构造器和GRU模块。
- 提取多尺度特征,构建初级代价体;
- 输入至初始深度值预测模块,利用轻量级的3D CNN估计初始深度图;
- 利用深度图估计新的深度范围,构造局部代价体;
- 利用几何特征(局部体)、深度特征(深度图)、上下文特征(参考图)构建动态代价体;
- 输入迭代GRU模块,采用多尺度级联的GRU结构对多尺度信息进行聚合,更新深度图;
- 循环以上结构,进行多阶段多次迭代。

2. 多尺度深度特征提取
参考图像I0和N−1个源图像Ii组成大小为W × H的输入图像,并使用特征金字塔网络(FPN)提取多尺度特征。特征图有3个尺度(阶段k = 0,1,2),用Fk表示图像在k阶段的特征,分辨率分别为原始图像的1/8、1/4、1/2。同时,用另一个的FPN网络处理参考图像,用于提取基于GRU的优化器的多尺度上下文特征和初始隐藏状态。
3. 动态代价体
代价体在MVS问题中起着关键作用。如下图所示,不同于以往工作的静态代价体,我们将几何特征、深度特征和上下文特征聚合起来构建动态代价体。分别从局部代价体、深度特征和参考图像中提取几何特征、深度特征和上下文特征。得益于迭代策略,该方法可以在一个较窄的逆深度范围内更新深度假设,从而在每次迭代中构建局部代价体,这使得动态代价体比静态代价体小很多。

3.1. 局部代价体
与MVSNet一样,给定参考视图的深度假设dj={1,…,D}中,利用可微单应性变化,通过方差构建局部代价体,表示参考特征和源特征之间的相关性。
考虑到基于GRU的优化器可以迭代更新深度图,每次迭代中只在一个狭窄的逆深度范围内采样一些深度假设。具体来说,对于阶段k和迭代t的每个像素p,统一在逆深度范围Rk中采样Dk深度假设:

其中Im表示最小深度假设平面间隔。Dk t−1为迭代t−1中更新的深度图。为了用二维CNN处理局部代价体,并将其与上下文和深度信息融合,我们取消了深度维度,并沿着通道维度连接代价图。因此,与MVSNet不同,该局部代价体的形状是CL∈W×H×(C×D),其中C和D分别表示通道维度和深度维度。
3.2. 特征聚合
在每次迭代t中,使用两个轻量级提取器从局部代价体和深度图Dk t−1中提取几何特征和深度特征,该提取器由两个二维卷积层组成。上下文特征来源于多尺度上下文特征提取器,每个阶段只需要提取一次。为了构建最终的动态代价体C,首先利用二维卷积层处理几何特征和深度特征的连接。然后,将输出与上下文特征连接起来,形成动态代价体。所有的连接操作都在通道维度中执行。
4. 多阶段GRU
为了利用多尺度信息,加快收敛速度,结合金字塔特征图,构造了多尺度的GRU结构处理动态代价体。在每次迭代t中,优化模块输出深度图残差Δdt,并更新输入深度图Dt = Dt−1 + Δdt更新,被上采样至Dt+1作为下一次迭代t+1的输入。如下图所示,每次迭代后深度图的质量都有明显的提高。特别是从图4中可以看出,基于GRU的优化模块可以填充无纹理区域的孔洞,锐化边界。

4.1. 初始深度预测
基于GRU的优化模块根据局部空间信息更新深度值。由于MVS中的弱纹理区域和相似区域的共性问题,一个不可靠的初始深度图将使基于GRU的优化更容易输出错误的深度值。因此,文中提出了初始深度值预测模块,在最粗阶段预测可靠的初始深度值。

和其他基于学习的MVS方法一样,通过代价体构建、3D CNN正则化和回归三个模块预测概率体Pd和相应的深度图,如上图。
- 建立了一个很小的代价体,它由稀疏深度假设组成,但包含足够大的逆深度范围。
- 利用一个轻量级的3D CNN对代价体进行正则化,得到每个深度假设d对应的概率体Pd。
- 用softargmin回归初始深度图Dinit:

4.2. GRU
使用GRU模块来更新深度图,该模块细节如下:

其中σ为sigmoid激活函数,W为对应卷积网络的参数,conv为一个小的2D卷积模块,由一个1×5卷积和一个5×1卷积组成。GRU的输入是动态代价体Ct−1以及潜在隐藏状态ht−1。动态代价体Ct−1可以通过之前的深度图Dt−1进行更新。此外,在每个阶段,初始隐藏状态h0由上下文特征网络初始化。基于隐藏状态ht,利用深度头模块来预测残差深度Δdt。深度头模块包含两个卷积层,并使用tanh激活函数来约束输出值的范围。
在每个阶段k的最后一次迭代Tk之后,使用掩码上采样模块(GRU中提到的)对当前深度图进行上采样。
5. 损失函数
在训练阶段,计算初始深度预测模块和不同的迭代阶段基于GRU的多阶段优化模块中输出的深度图和相应分辨率的真实深度图的L1损失。最终损失是所有损失的加权和:

其中Linit是初始深度预测模块获得的初始深度图的损失。Tk为第k阶段的优化迭代次数。Lk i为Tk输出深度图和k阶段上采样深度图的损失,λk i为相应的权值。
6. 实验
6.1. 数据集
DTU Dataset、Tanks and Temples Dataset
6.2. 实现
训练:使用DTU数据集训练。输入视图数N = 5,图像大小裁剪到640 × 512,输入图像的总数设置为N = 3,对于初始深度预测模块,深度值的样本总数设置为D = 48。对于局部代价体,我们将所有阶段的深度假设数量Dk设为4。定义了逆深度的最小假设平面区间Im:

设Z为384,深度假设间隔在阶段0,1,2设为至4Im, 2Im, Im(阶段0为分辨率为W ×H = 80×64的粗阶段)。对于每个阶段的优化模块,我们设置阶段0,1,2到的迭代次数T k为3,3,3。使用AdamW在OneCycleLR调度器下训练模型48个epoch,学习率为0.001。批大小设置为4,并在1个NVIDIA GeForce RTX 3090 GPU上训练模型。
评估:对于DTU,设置输入图像数量N为5,输入图像大小为1600 × 1184。评估Tanks & Temples数据集,使用DTU训练的模型,并且没有任何微调。视图数N设为7、输入图像大小为1920 × 1056,初始深度预测模块中深度假设个数为96。Tanks & Temples数据集的相机位置、稀疏点云和深度范围由开源SfM软件OpenMVG得到。
滤波与融合:与MVSNet一致,使用光度一致性、几何一致性对输出深度图进行滤波。本文对滤波算法做了一些改进,具体细节详见补充资料。同时,对从初始深度预测模块获得的概率体Pd进行上采样,作为每个像素的置信度度量,丢弃估计的深度概率小于0.3的像素。
6.3. 结果
DTU数据集基准比较:SOTA

内存和时间比较:SOTA

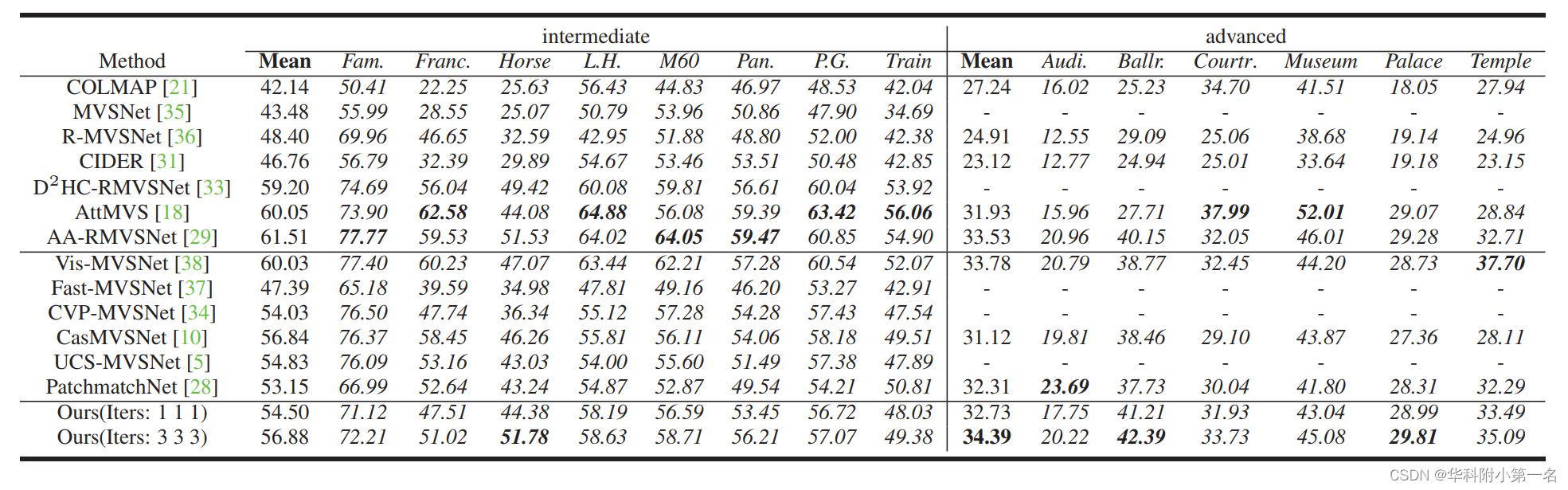
Tanks & Temples泛化性:SOTA ,advanced表现更好
6.4. 消融实验
迭代次数:It is not surprising, because our dynamic cost volume could aggregate distinctive context information, which could be further utilized by the GRU to fill in the holes. The similar conclusion could also be proven,which the holes are filled with the number of iteration increased.
初始深度预测:because our dynamic cost volume could aggregate distinctive context information, which could be further utilized by the GRU to fill in the holes. The similar conclusion could also be proven in the Fig. 4, in which the holes are filled with the number of iteration increased.
动态代价体:depth feature(DF) and context feature(CF) is important.
阶段次数:The performance has improved significantlywith the increase of the number of stages. At the same time, the running time and GPU memory consumption have also increased significantly.















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











