







同时进行embedding的学习和k-means聚类。
损失函数:
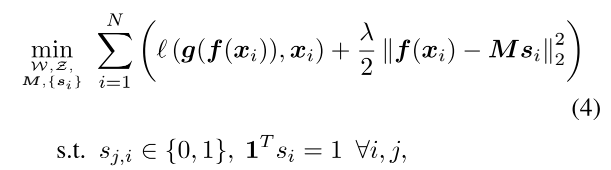
重构损失 + 聚类损失
重构损失可以避免聚类的平凡解
layer-wise pre-training
k-means初始化
交替学习参数:
基于梯度的自编码器参数
类别学习
基于梯度的类中心更新
同时进行embedding的学习和k-means聚类。
损失函数:
重构损失 + 聚类损失
重构损失可以避免聚类的平凡解
layer-wise pre-training
k-means初始化
交替学习参数:
基于梯度的自编码器参数
类别学习
基于梯度的类中心更新
 531
5443
531
5443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























