







文章:NIPS’17
代码:TensorFlow实现;Pytorch实现
经典的聚类算法具有离散结构:需要重新计算质心和数据点之间的关联,或者需要合并假定的聚类。
在任何一种情况下,优化过程都会被离散的重新配置打断。
连续聚类:在优化过程中没有考虑具体离散的类别,而是以优化节点表示和节点对连边这个连续问题为目标。最后通过连边的情况划分类别。
目标函数
由三部分构成:自编码器的重构损失;聚类嵌入Z和低维嵌入Y的距离;聚类嵌入Z的成对损失

图
ϵ
\epsilon
ϵ根据X的相互最近邻构建。由 kNN 图的最小生成树(minimum spanning tree)进行增强,以确保与所有数据点的连接。
ρ
1
\rho_1
ρ1,
ρ
2
\rho_2
ρ2,M估计量,使得属于同一个cluster的embedding尽可能接近。
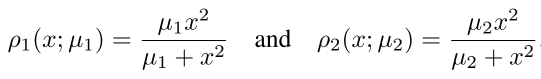
μ
1
\mu_1
μ1,
μ
2
\mu_2
μ2控制估计量的凸性。
ω
i
,
j
\omega_{i,j}
ωi,j,平衡数据点的成对损失。
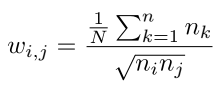
λ
\lambda
λ平衡各项损失,Y和A谱范数的比值。
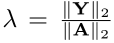
其中

优化中的问题
- 参数Ω是关于所有样本更新的,而Z只是关于单个样本和成对样本更新的,因此应该具有不同的学习率。使用Adam进行参数的学习。
- mini-batch中,随机抽取子样本点不可行,因为会有相邻的样本点在mini-batch之外,因此需要随机选取边,从而构成子图 ϵ \epsilon ϵ
- 在mini-batch中,reconstruction loss和data loss的权重会变大。因为按边采样的话,节点会出现在不同的batch中,因此小批量训练的时候需要修改前两个loss的权重,加入ω。

训练
- initialization
自编码器参数Ω: 使用stacked denoising autoencoder (SDAE)初始化
聚类低维嵌入Z:Z = Y
- Stopping criterion
小于0.1%边的连接状态改变,则停止
算法

思考小结
Y是真正输出的低维嵌入,Z是聚类相关的低维嵌入。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









