







语义分割
本篇博客对语义分割大致框架进行讲解,本章的目录如下:
- 常见分割任务介绍(以语义分割为主)
- 语义分割常见评价指标
- 语义分割损失计算
本文参考:
- 语义分割前言
https://www.bilibili.com/video/BV1ev411P7dR
常见分割任务介绍
常见分割任务有语义分割,实例分割,全景分割,见下:

常见的语义分割网络
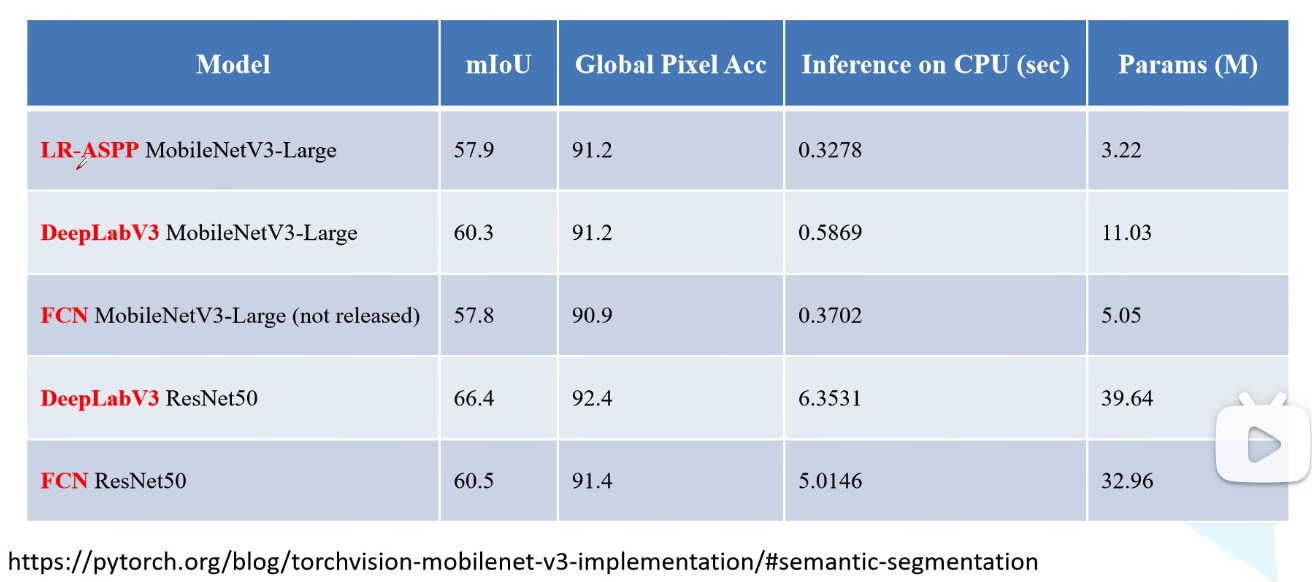
pytorch demmo中常见的语义分割网络如下:
语义分割常见数据集
语义分割常见数据集有PASCAL VOC和MS COCO。VOC数据集以调色板为主要组织形式,MS COCO以多边形为主要呈现形式。他们的数据集格式见下:


语义分割得到的结果
语义分割得到的结果即灰度图片,需要经过mask蒙版来将真实图片显示出来。最终我们得到的图片效果可能如下,每个像素数值对应类别索引:

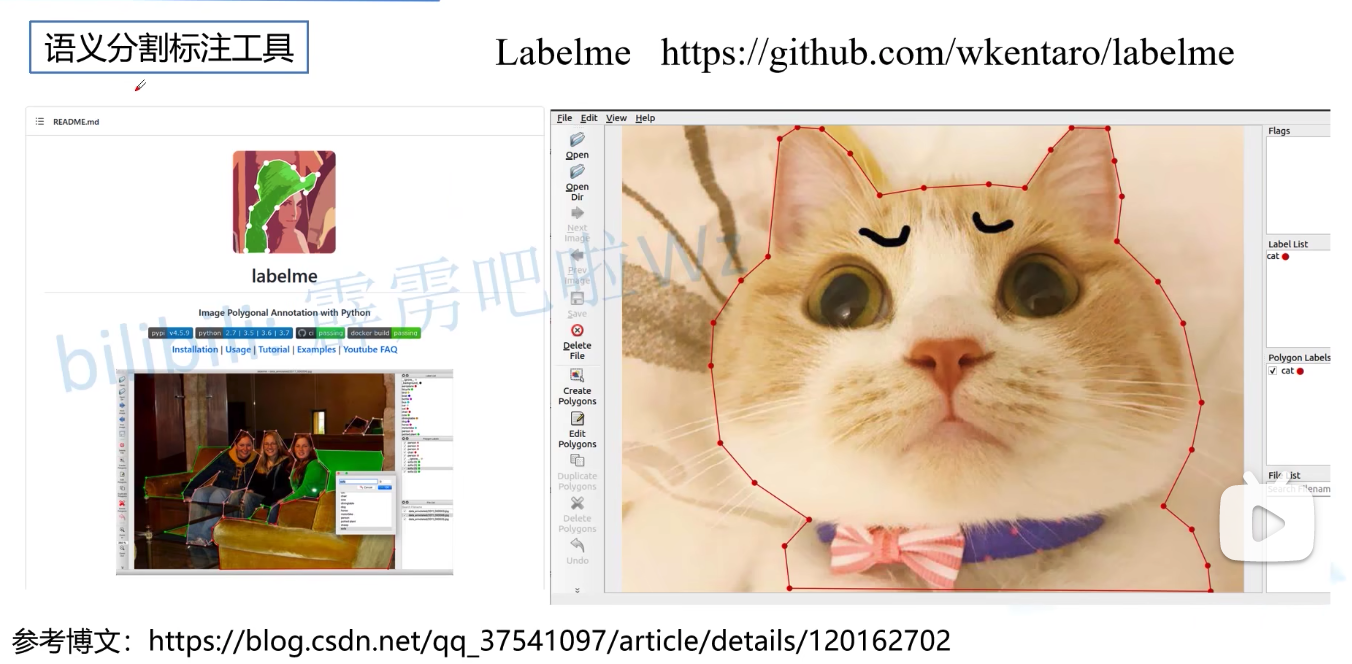
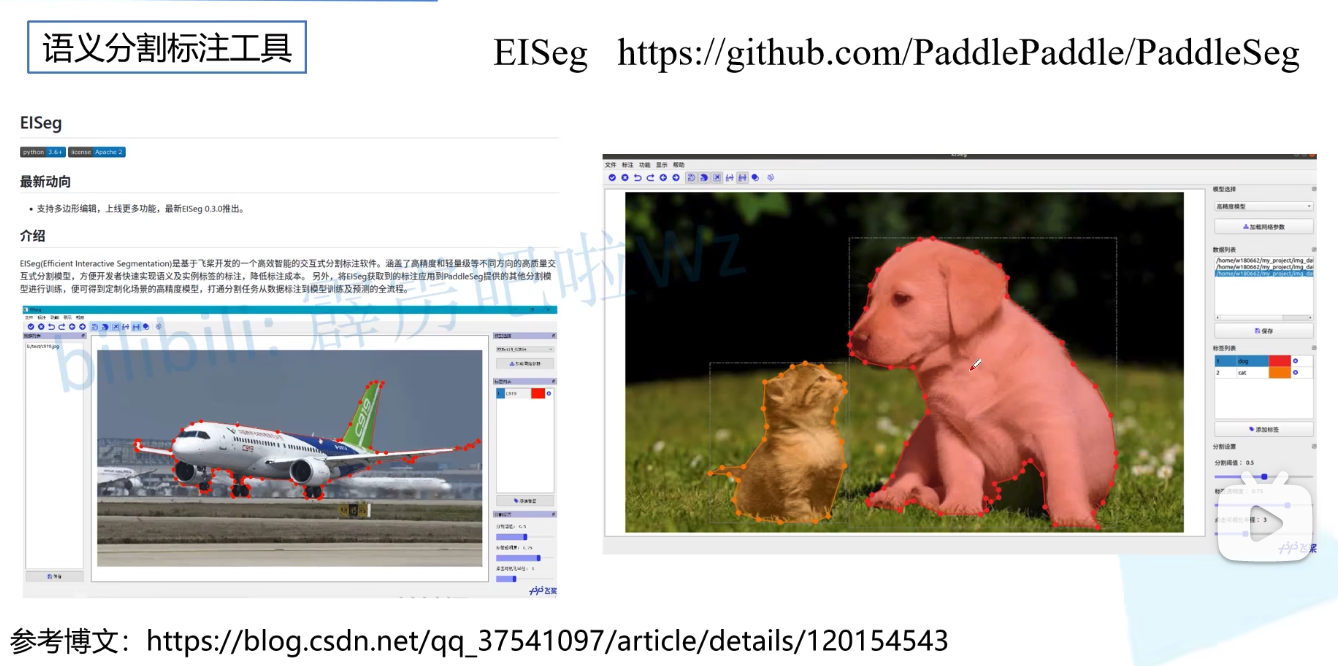
语义分割标注工具
常见的语义分割标注工具有labelme(同PS中无曲线钢笔使用),EISeg(百度paddle,点击后会自动抠图)
语义分割常见评价指标
常见评价指标有三种:Pixel Accuracy, mean Accuracy, mean IoU。这三种常见评价指标来自FCN网络,其计算公式如下:

Global Acc
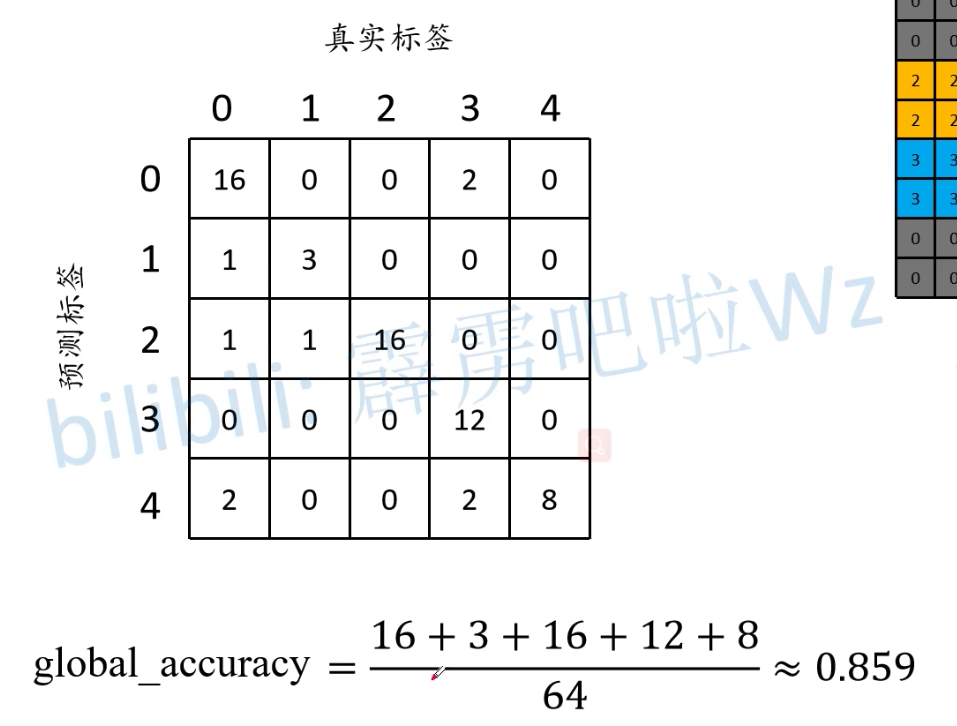
Global Acc评价指标指的是预测正确的像素总个数比上图片总像素个数。
mean Accuracy
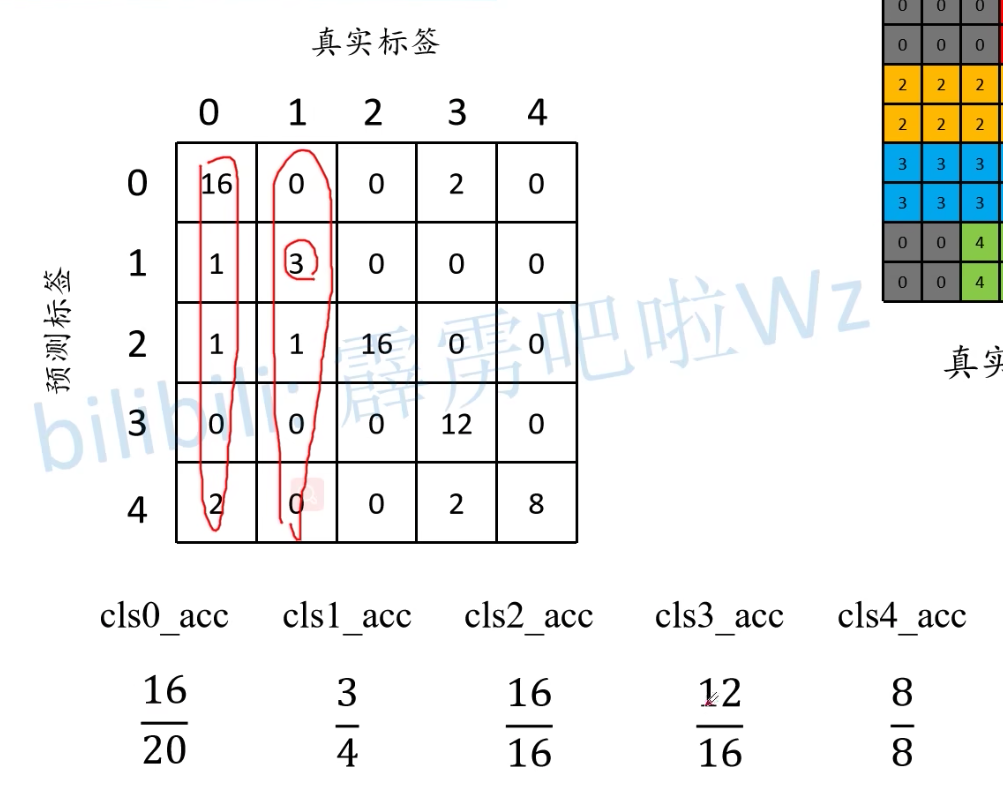
mean Accuracy指的是每个类别预测正确的像素个数比上该类别真正的像素个数,求和后取平均。
mean IoU
mean IoU每个类比的交并比,求和后取平均。
计算方法
上面三个值的计算方法,我们是使用混淆矩阵进行计算,如下:
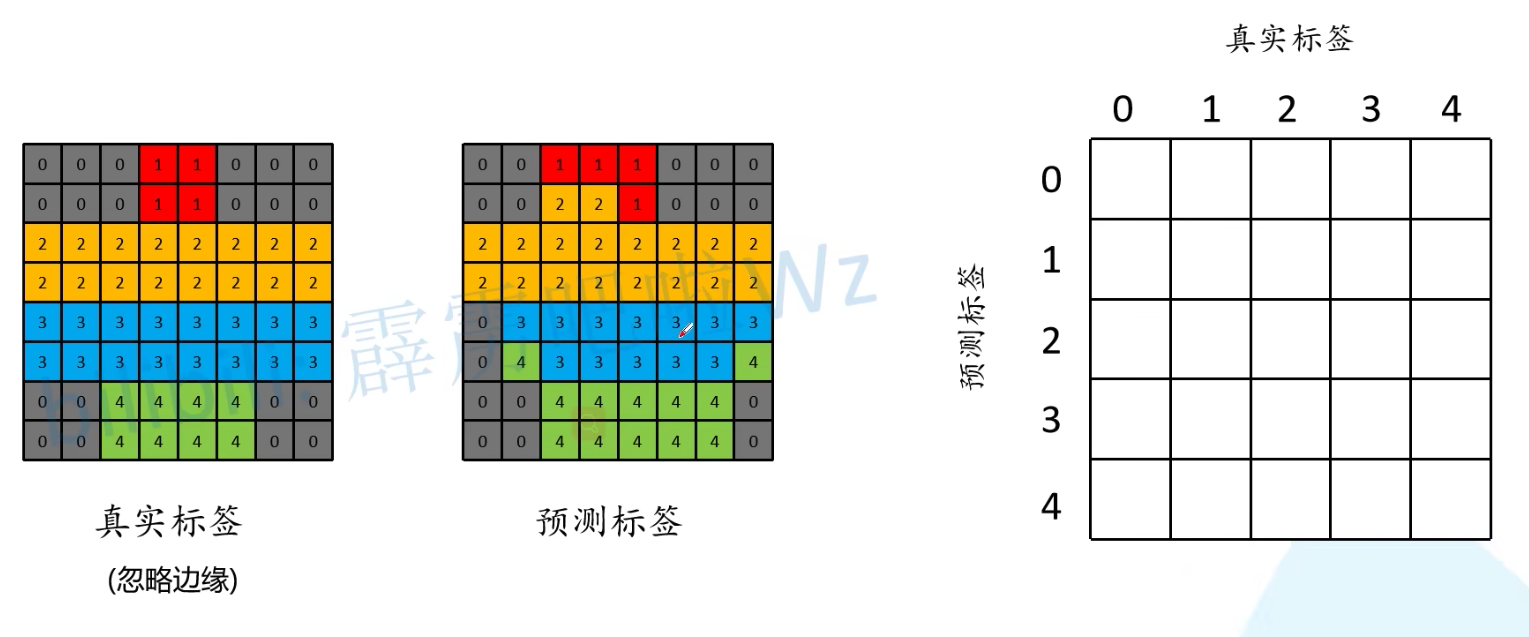
例如计算类别0的预测标签,我们就需要填写第一行各个元素的值:
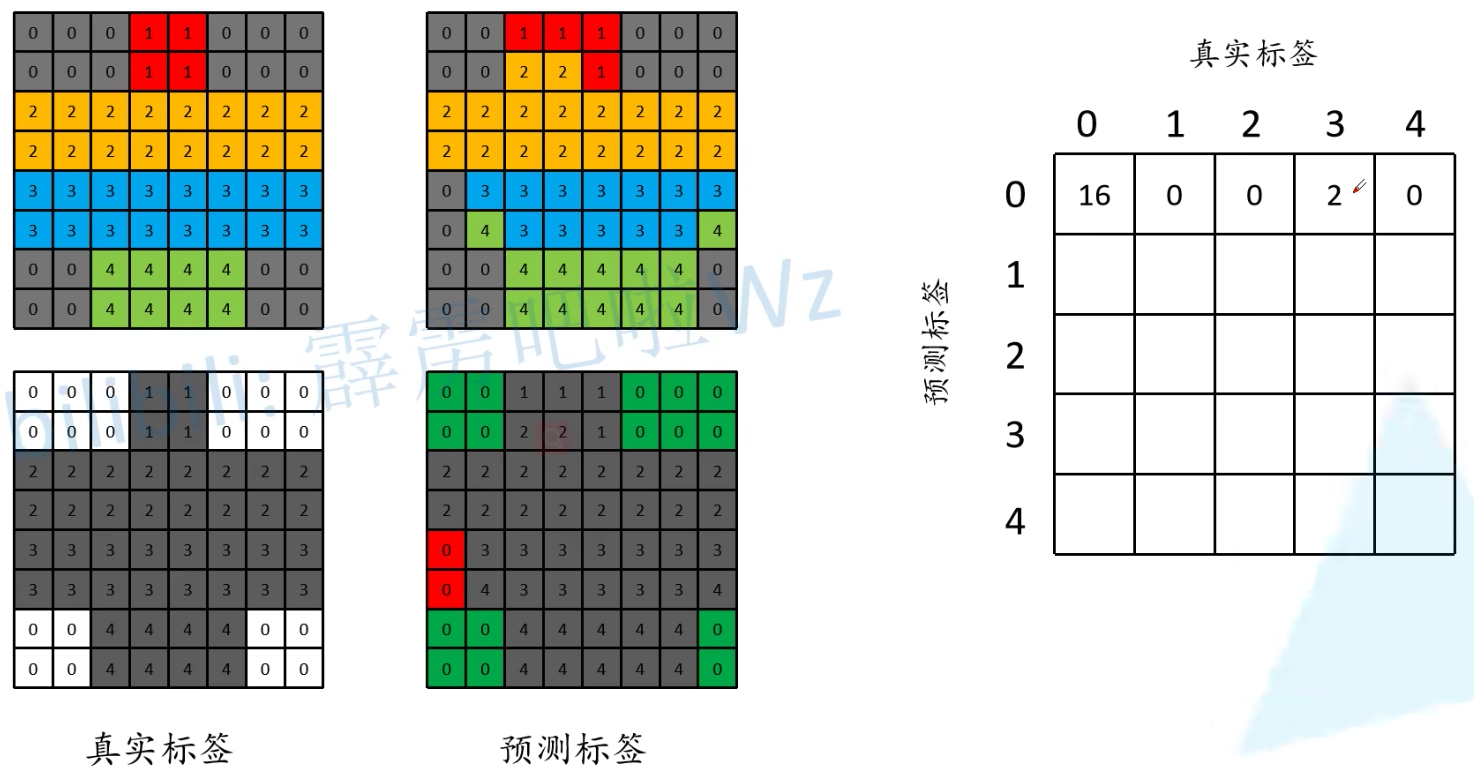
最终我们得到混淆矩阵,对角线上即为预测正确的标签个数,根据混淆矩阵,就能求得上述三个指标的值:
global accuracy计算:
mean Accuracy计算:
mean IoU计算:
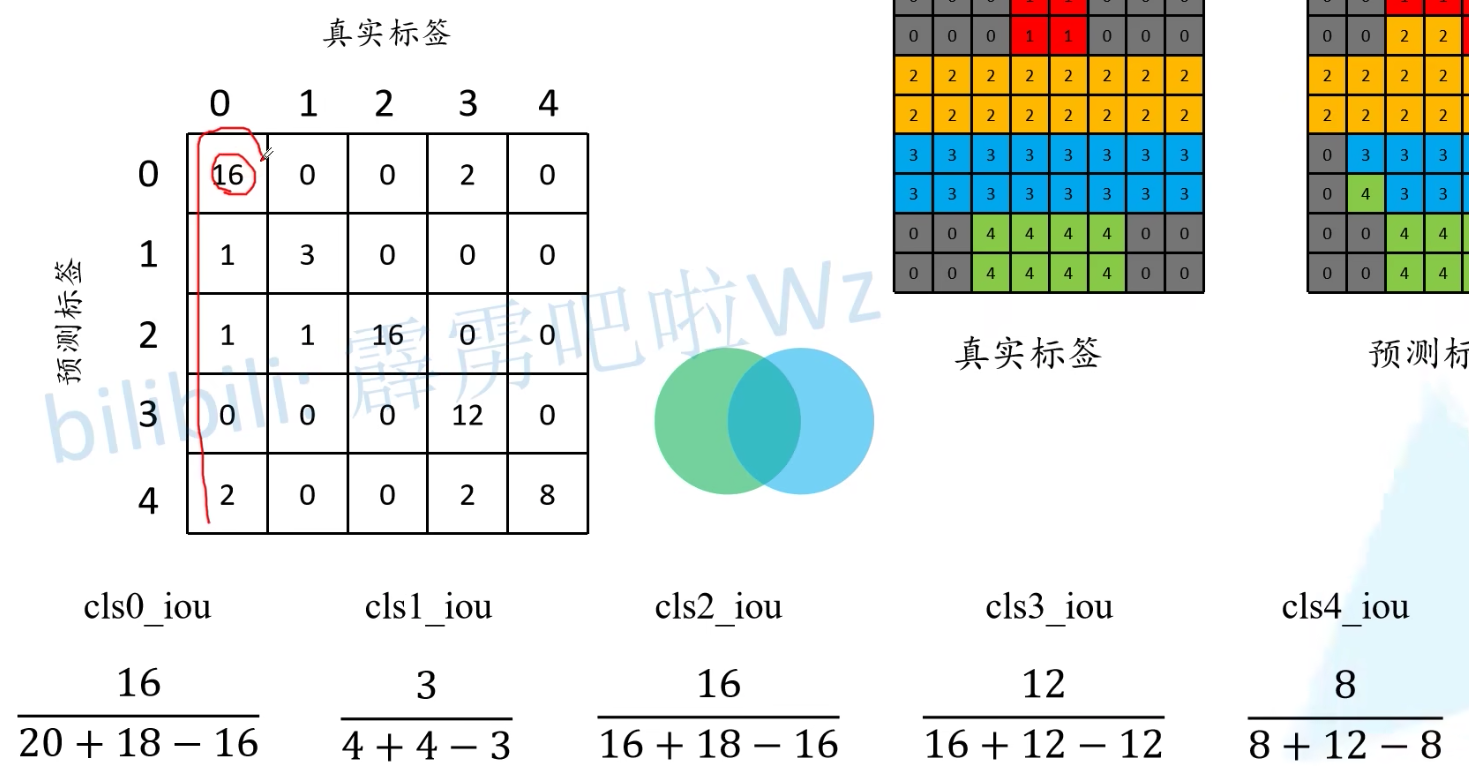
语义分割损失计算
根据不同网络模型会不同。















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









