







PSO:particle swarm optimization
注:以下的鸟就是粒子。
总体思想
有若干只鸟 x i x_i xi,位置可能各不相同,但是每只鸟需要记录下自己的个体历史最优解 p b e s t i pbest_i pbesti,并分享给大家,在这些个体历史最优解中,记最优的那个为全局最优解 g b e s t gbest gbest。然后,每只鸟都根据 p b e s t i pbest_i pbesti和 g b e s t gbest gbest来调整自己的位置,其实就是希望在这两者的中间部分搜寻。
算法双要素
每只鸟都有一个位置 x x x和速度 v v v,其中 v v v由 p b e s t i pbest_i pbesti和 g b e s t gbest gbest决定, x x x由 v v v决定。
1. 我们先说
x
x
x如何由
v
v
v决定。假设当前某只鸟的位置
x
x
x和速度
v
v
v如下:

则这只鸟的下一个位置为:
x
=
x
+
v
x=x+v
x=x+v
即:

2. 我们再说
v
v
v如何由
p
b
e
s
t
i
pbest_i
pbesti和
g
b
e
s
t
gbest
gbest决定。假设当前某只鸟的位置
x
i
x_i
xi、速度
v
i
v_i
vi、该鸟的个体历史最优解
p
b
e
s
t
i
pbest_i
pbesti,以及鸟群的全局最优解
g
b
e
s
t
gbest
gbest如下。(注:
x
i
x_i
xi等等三个也和
v
i
v_i
vi一样,是一个向量,只是没显式地画出来而已。)

按照我们之前的思想,我们希望这只鸟既靠近 p b e s t i pbest_i pbesti又靠近 g b e s t gbest gbest,那么综合一下,就是往他们的中间方向靠近。
即做两个向量差,如下:

然后这两个向量加权相加,比如
y
=
0.1
y
1
+
0.2
y
2
y=0.1y_1+0.2y_2
y=0.1y1+0.2y2,随便你设置,假设我们相加后的
y
y
y是这样的。

然后我们再进行
v
i
v_i
vi的更新,即
v
i
=
v
i
+
y
v_i=v_i+y
vi=vi+y。即根据向量的加法得到红色的新
v
i
v_i
vi。

至此
v
i
v_i
vi的更新完毕了,最后一步我们也一起做完吧。即
x
i
=
x
i
+
v
i
x_i=x_i+v_i
xi=xi+vi。如下图,我们得到了新的粗蓝色新的
x
i
x_i
xi。

总结
PSO算法的标准形式:
在每只鸟分享完信息之后,先按公式1更新速度(下面的3个向量相加和我们上面的图解一模一样),然后按照公式2更新位置。
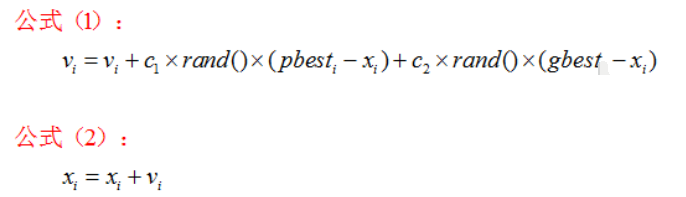
其中:
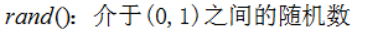

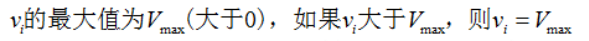
这个解释一下,如果
v
i
′
=
v
i
+
y
v_i^{'}=v_i+y
vi′=vi+y,如果
v
i
′
v_i^{'}
vi′的长度太大了,那么保留这个
v
i
′
v_i^{'}
vi′的方向,但是截断其长度,使其为
v
m
a
x
v_{max}
vmax的长度。
扩展

标准的PSO算法是上述公式(3)和公式(2),因为其引入了惯性因子 w w w,使得算法相对之前,更加灵活可变,成了标准。
上述其值较大,全局寻优能力强等等那里的分析,联系一下我们上面的图,向量相加那里,立马就能够理解了(全局寻优能力强就是迭代之后新的 x i x_i xi远远飞离现有的3个点:旧的 x i , p b e s t i , g b e s t x_i,pbest_i,gbest xi,pbesti,gbest,反之,如果迭代之后很靠近这三个点,就是局部寻优)
参考:
https://blog.csdn.net/daaikuaichuan/article/details/81382794















 5988
5988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











