









参考
一、Python神经网络编程
二、CSDN博客与简书
梯度下降法
如何训练神经网络(即找到合适的权重)一直是神经网络的核心问题,从第一节可知,我们通常是通过误差来指导我们如何一步步改进神经网络。但是一个复杂的神经网络包含很多层,每一层包含很多参与中间运算的神经元,每一个神经元都可能会产生误差。
然而,我们只有神经网络最终输出的误差,即输出层每个神经元的误差。在上一节—误差与学习中,我们指出了可以采用误差反向扩散的方式,从输出层的误差按照传递链的权重将各个输出神经元的误差前馈到上一层神经元。以此类推,在一次训练中,我们可以获得神经网络中每一个神经元的误差。
在这个过程中矩阵可以帮我们减轻计算量记作E=X.E’,这里的E是上一层的的误差矩阵,X是下一层与上一层之间的权重矩阵,E’是下一层的误差矩阵。所以我们可以通过这一个公式,只需要知道输出层即最终层的误差,就可以前馈到前面每一层,得到每一层的误差即每一个神经元的误差。
在得到了每个神经元的误差以后,我们关心的则变成了这些误差应该如何辅助我们更新神经网络各个传递链的权重。从而使得误差值减小,使输出结果接近我们的理想结果。
站在数学的角度来说这是求函数的最值问题,即Y=(x1,x2,x3…xn)记Y为某一个神经元的误差值,x1,x2,x3…xn分别表示输入这个神经元的所有传递链的权重。(这里稍微有点跳跃,我们没有采取输入而是采取了输入权重。因为实际上对于一个神经网络来说,我们一般都是调整权重,而传递的实际值实际上也只受权重影响,在一个确切的模型下)。
高中数学告诉我们,对于单一自变量的函数,我们可以使用导数求得函数的最小值和最大值。对于多元函数Y来说,我们使用梯度,即梯度为负数表面函数值在减小,称之为梯度下降。
结合第一节的分类器与预测器中,我们可以作图观察误差随权重变化的方向,如下图所示:

假设,上图中y代表的是误差值,x代表的某个神经元的某条输入链的权重(假如有多条则是多维度的)。梯度下降法的思想源自于人们在山谷中寻找下山的路,当坡度变陡峭的时候,我们会大步往前迈(也就是增大改变权重的幅度),相反当坡度变得平缓时,意味着我们接近一块平地了,我们要减小步长避免错过。
这一方法指导了我们该如何根据误差的变化调整权重的变化,但是这种方法存在两个问题:
① 熟悉数学的人可能很容易发现,导数也就是斜率为零的点不一定是函数的最小值只能是函数的极小值。因此我们找到的误差最小点对应的权重实际上不一定就是真正的最优解。
② 假如我们单纯地通过斜率来调整步长的话,那么倘若函数出现十分特殊的情况,即间断点。可以想象成在某一点,误差值突然下降变为整个函数的最小值时,由于该点附近的斜率极大,因此我们的步长也会极大这样就可能会错过这个窄缝。
针对上面两个问题,我们可以通过改变起始值的方式解决(即起始权重),如下图所示不同的起始值对结果有很大影响。

因此,我们在训练过程中可以尽可能多次改变起始权重并且横向比较找到的最小误差,从而确定真正的最小误差。
此外,在使用误差的时候,我们不得不注意误差的正负,因为在前馈误差的过程中,各个神经元的误差是有传递链求和得到的,倘若不注意正负符号直接求和的话那么正负误差会相消从而导致出现无误差的情况。因此,我们可以采取两种解决方案:
① 对误差求绝对值
② 求误差的平方
在这里我们倾向于第二种解决方案,因为平方可以使得误差函数更加平滑避免间跃的情况。
公式推导
尽管有了上面的理论基础,我们还是不得不推导出一个数学公式,否则计算机无法直接地帮我们完成神经网络的训练。
显然,我们的目标是推导出一个通式d(Y(x1,x2…xn))/dx1即某一个神经元误差函数Y对与其连接的传递链1的权重x1的导数(偏导数)。这里我们取误差为平方的形式。
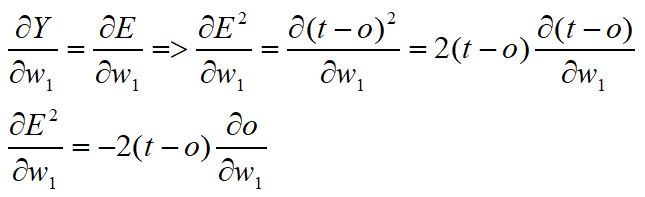
使用链式法则可以很快地帮助我们推导出结果,注意在推导过程中我们使用了一点点小技巧即令E=(t-o)虽然我们已经知道了E的具体值不过,为了得出一般性的结论,我们还是希望找到E的函数式。
某一节点的误差=该节点的理想输出-该节点的实际输出。该节点的理想输出记作 t ,实际输出记作o。显然在一次训练中,理想输出 t 与权重w1无关,这个值来自我们得到的训练数据。所以可以视为常数得出这些推导。
下一步,我们可以利用 o 的定义,o 定义为某一节点输出,实际上是前面所有输入链的值乘以输入链的权重求和应用S函数的结果。
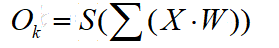
因为,S函数的表达式是已知的,所以我们经过导数最终可以得到如下表达式:
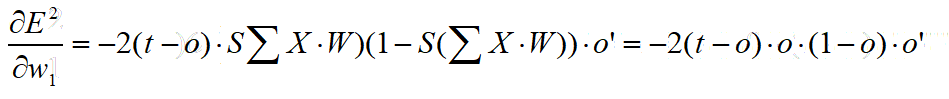
值得解释的是,o 表示该神经元的输出,S表示S函数,o’表示该神经元第一条输入链的输入(t-o)即该神经元的误差。
由此,我们只需要知道任意一个神经网络的中某一个节点的输出o输入o’以及误差E=2(t-o)即可以更新出权重的调整值(即偏导)。将这个调整值再乘以学习率L即得到一次训练的实际调整值。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









