







文章目录
Titanic - Machine Learning from Disaster
Description:
In this challenge, we ask you to build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
Evaluation:
Start here! Predict survival on the Titanic and get familiar with ML basics
Goal
It is your job to predict if a passenger survived the sinking of the Titanic or not.
For each in the test set, you must predict a 0 or 1 value for the variable.
Metric
Your score is the percentage of passengers you correctly predict. This is known as accuracy.
Data
PassengerId => 乘客ID
Pclass => 客舱等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 兄弟姐妹数/配偶数
Parch => 父母数/子女数
Ticket => 船票编号
Fare => 船票价格
Cabin => 客舱号
Embarked => 登船港口
ariable Notes
pclass: A proxy for socio-economic status (SES)
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way…
Sibling = brother, sister, stepbrother, stepsister
Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way…
Parent = mother, father
Child = daughter, son, stepdaughter, stepson
Some children travelled only with a nanny, therefore parch=0 for them.
运行环境
运行环境:python3.5.6 + jupyter notebook;
可视化工具 matplotlib,seaborn,tableau;
数据分析,模型构建 pandas sklearn
EDA
运行环境:jupyter
数据概览
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
#读取数据
train_data = pd.read_cdv("trian.csv")
#查看数据基本信息
#数据规模 数据缺失情况 特征类型
train_data.info()
#PassengerId 没有贡献,drop
train_data.drop(columns='PassengerId',inplace=True)

Analysis:
Name, Sex, Ticket, Cabin, Embarked为object型(其中sex,Embarked为标签类离散数据,所以后续需要做类别数据的转换),其他的特征都是数值型.
Age,Embarked存在少量缺失值(考虑多种填充方法对比效果),Cabin缺失严重可以考虑直接删除(其实乘客所在船舱和存活的关系还是挺大的,例如位置靠近碰撞区域,肯定生存几率比较小,但是缺失实在太严重了)
(Name,以及Ticket涉及文本,暂时不作处理)
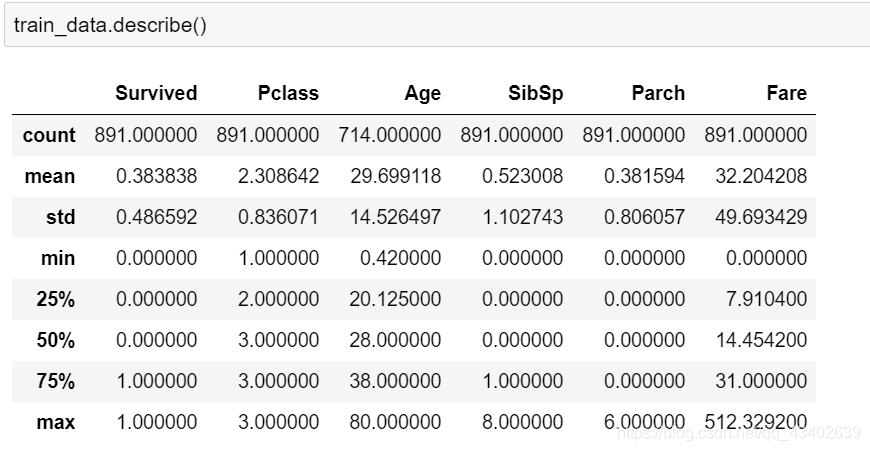
# describe()方法可以通过最小最大值以及分位值帮助初步观察数值型特征的数值分布情况,如偏离,异常值,逻辑缺失值等。
# 可以看出Fare 最大值偏离严重,且存在0值,按常理Fare不应该为0,进一步查看数据。
train_data.describe()
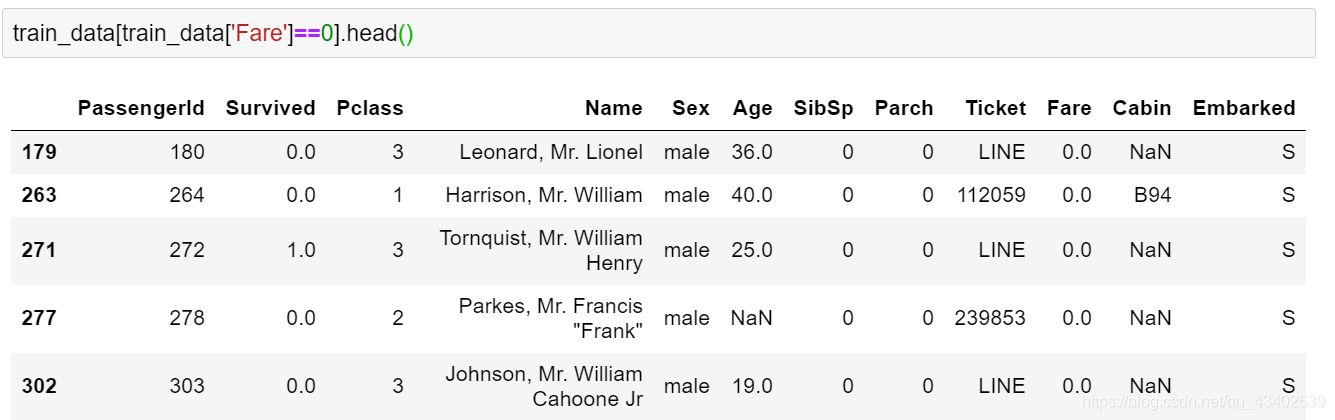
# 观察发现这些乘客有船票,所以认为这些0值其实是缺失值,替换为np.nan
train_data[train_data['Fare']==0].head()
train_data['Fare'].replace(0,np.nan,inplace=True)
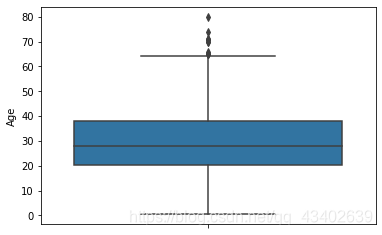
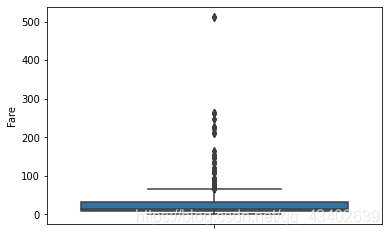
# 进一步查看特征的数值分布,看看是否存在偏离值,异常值
# 筛选掉类别特征和非数值特征
# 可以看出特征fare存在大量离群值 后续可以针对离群值做处理 但是需要考虑不同价位存在可能
for col in train_data.columns:
if train_data[col].dtypes!='object' and train_data[col].unique().shape[0]>10:
plt.figure()
sns.boxplot(y=train_data[col])
# 本题是分类预测问题,所以先关注训练集中给出的类别比例分布
# 大约2/3为类别0, 1/3为类别1, 没有出现严重的类别失衡, 可以不考虑采样
# 同时类别0占比66%,所以之后的预测结果应该要高于66%才有效果
plt.figure()
sns.countplot(train_data['Survived'])
plt.show()
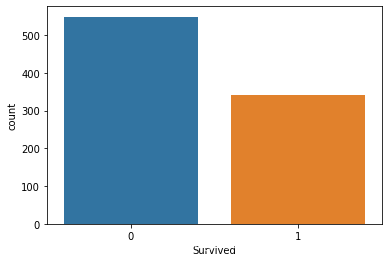
数据分布
# 各数值特征和label(Survived)之间的关系
for col in train_data.columns:
plt.figure()
# 连续型数值 Age Fare
if train_data[col].dtypes!='object' and train_data[col].unique().shape[0]>10:
sns.distplot(train_data[col].dropna()[train_data['Survived']==0],hist=True,label='0')
sns.distplot(train_data[col].dropna()[train_data['Survived']==1],hist=True,label='1')
# 类别值 <10过滤掉Name Ticket Cabin
elif train_data[col].unique().shape[0]<10:
sns.countplot(train_data[col],hue=train_data['Survived'])
plt.show()
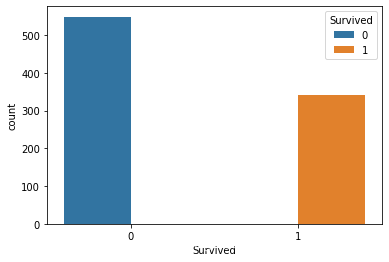
Pclass=1,Pclass=2存活率明显高于Pclass=3

female存活率明显高于male
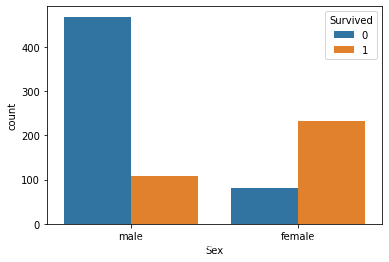
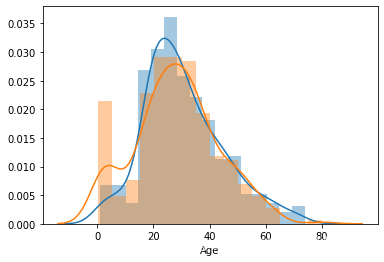
乘客年龄分布
SibSp=0的乘客最多,但是存活率最高的是SibSp=1,SibSp=2的乘客
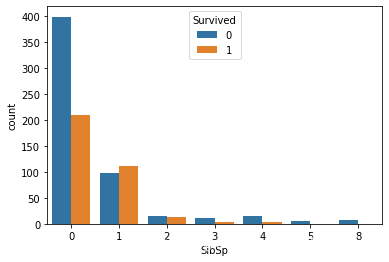
Parch和SibSp呈现出相同的特性
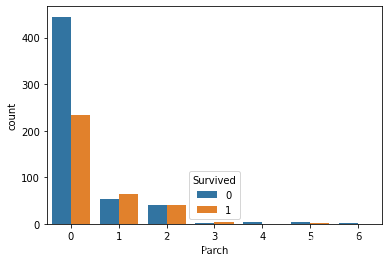
Fare特征中部分高价的船票的存在使得数据分布右偏
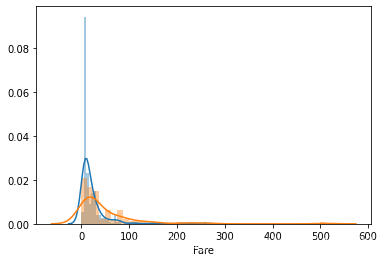
Embarked=C,Embarked=Q存活率明显大于Embarked=S
通过之前可视化可以发现male和female的幸存率完全不同,为了进一步探索sex,age,fare和存活率之间的关系,绘制下图(tableau绘制):
其中年龄按10分段,Fare按50分段统计存活率,并且加上了Sex维度比较男女差异
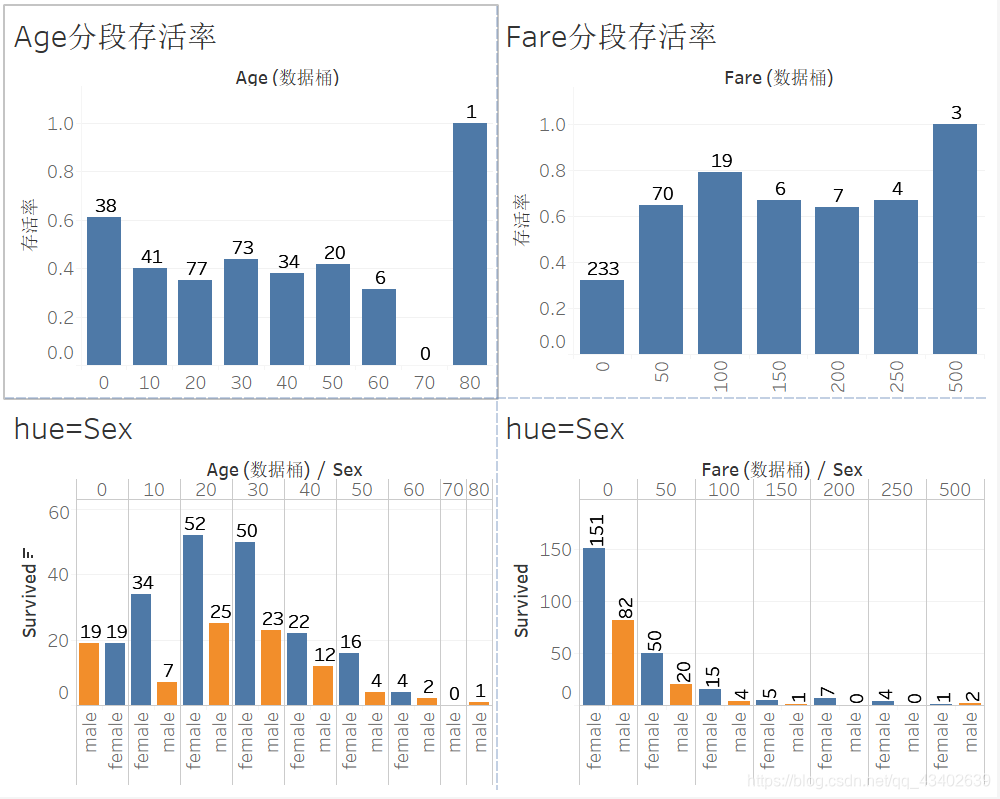
可以发现幼儿以及妇人的存活率明显较高,船票费用在0-50区间的存活率只有0.3。数据特征不多,可以考虑增加Age和Fare的分桶特征。
缺失值处理
# 1.Cabin列缺失值过多,暂时清除,Name,Ticket包含文本数据,暂时认为和姓名,ticket无关,后续可进一步处理
train_data.drop(columns=['Cabin', 'Name', 'Ticket'],inplace=True)
# 查看存在缺失的位置 train_data[train_data[col].isnull()]
# Age Nan 暂时用 median 填充,Embarked 用第四种类别 A 替代 Nan
# 缺失值处理的方式多种多样,后续可进一步处理
values = {'Age': train_data['Age'].median(), 'Embarked': 'A'}
train_data.fillna(value=values,inplace=True)
类别型特征转换
LableEncoder 和 OneHotEncoder:

# 数据处理
# 暂时将离散型值转换为数值Categorical
# 可以尝试不同的转换方法作对比
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train_data['Embarked'] = le.fit_transform(train_data['Embarked'])
train_data['Sex'] = le.fit_transform(train_data['Sex'])

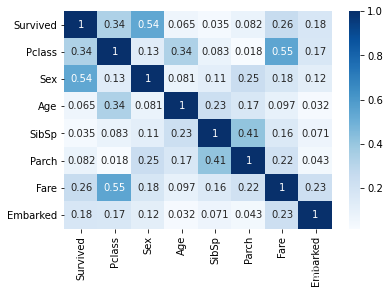
相关性分析
pearson系数百度百科

#correlation heatmap of dataset
# 和label相关性较大的为Sex,Pclass,Fare,Embarked
# 部分特征之间存在较高相关性 SibSp,Parch,父母儿女,兄弟姐妹其实都属于家庭成员,可以另外创建一个特征,Fnums=SibSp+Parch+1
train_data.corr() #相关系数
sns.heatmap(abs(train_data.corr()),cmap=plt.get_cmap('Blues'),annot=True)
数据处理方案
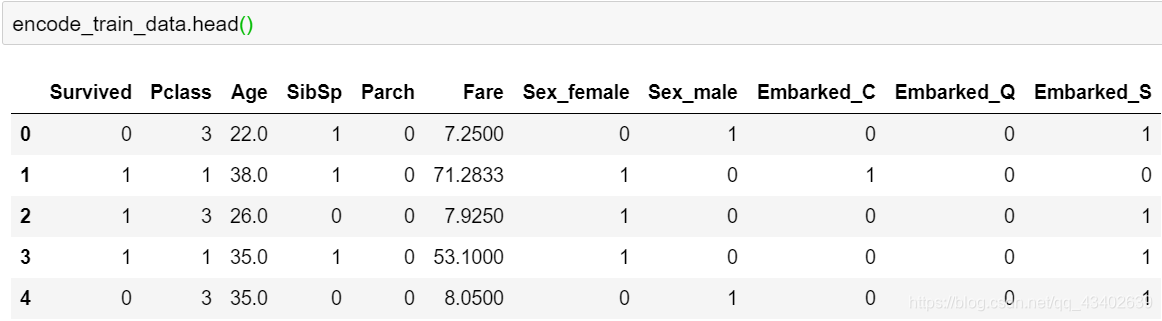
类别型特征(Sex,Embarked)转换:LableEncoder or OneHotEncoder
# LableEncoder
from sklearn.preprocessing import LabelEncoder
def labelEncoding():
le = LabelEncoder()
train_data['Embarked'] = le.fit_transform(train_data['Embarked'])
train_data['Sex'] = le.fit_transform(train_data['Sex'])
# OneHotEncoder 需要考虑到训练集和测试集单独encoding后的特征数可能不一样
def oneHotEncoding():
dum = pd.get_dummies(train_data[['Sex','Embarked']],)
data = pd.concat([train_data.drop(columns=['Sex','Embarked']), dum],axis=1)
return data
缺失值(Age 714 non-null,Embarked 889 non-null)填充:
缺失值填充方案:Embarked 889 non-null 只缺失两个,查看一下缺失的行,可以发现缺失的两行是幸存者,结合前面Embarked特征的幸存者分布,C类是幸存率最高的,所以我们手动填充Embarked缺失值为C;
values = {'Embarked': 'C'}
train_data.fillna(value=values,inplace=True)

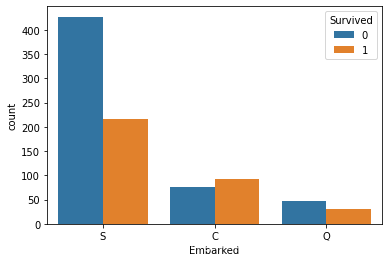
Age 714 non-null :Age的缺失值相对较多,手工填充太麻烦,考虑简单有效的中值填充,以及sklearn的KNNImputer方法。
sklearn.impute.KNNImputer¶
class sklearn.impute.KNNImputer(*, missing_values=nan, n_neighbors=5, weights=‘uniform’, metric=‘nan_euclidean’, copy=True, add_indicator=False)[source]
Imputation for completing missing values using k-Nearest Neighbors.
Each sample’s missing values are imputed using the mean value from n_neighbors nearest neighbors found in the training set. Two samples are close if the features that neither is missing are close.
values = {'Age': train_data['Age'].median()}
train_data.fillna(value=values,inplace=True)
from sklearn.impute import KNNImputer
imputer = KNNImputer()
train_data[['Pclass','Age','SibSp','Fare']] = imputer.fit_transform(train_data[['Pclass','Age','SibSp','Fare']])
特征工程
# 增加特征
# AgeBin FareBin 家庭成员
train_data['AgeBin'] = pd.cut(train_data['Age'].astype(int), 5)
train_data['FareBin'] = pd.cut(train_data['Fare'].astype(int), 25)
train_data['Fnums'] = train_data['SibSp'] + train_data['Parch'] + 1
数据标准化
X=train_data.drop(columns=['Survived'])
y=train_data['Survived']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X)
X = scaler.transform(X)
模型构建
本题为分类预测问题,选用以下模型(不涉及调参):
sklearn.linear_model.LogisticRegression
sklearn.linear_model.RidgeClassifier
sklearn.linear_model.SGDClassifier
sklearn.naive_bayes.GaussianNB
sklearn.neighbors.KNeighborsClassifier
sklearn.svm.LinearSVC
sklearn.svm.SVC
sklearn.tree.DecisionTreeClassifier
sklearn.ensemble.AdaBoostClassifier
sklearn.ensemble.BaggingClassifier
sklearn.ensemble.GradientBoostingClassifier
sklearn.ensemble.RandomForestClassifier
sklearn.ensemble.StackingClassifier
sklearn.ensemble.VotingClassifier
XGBClassifier
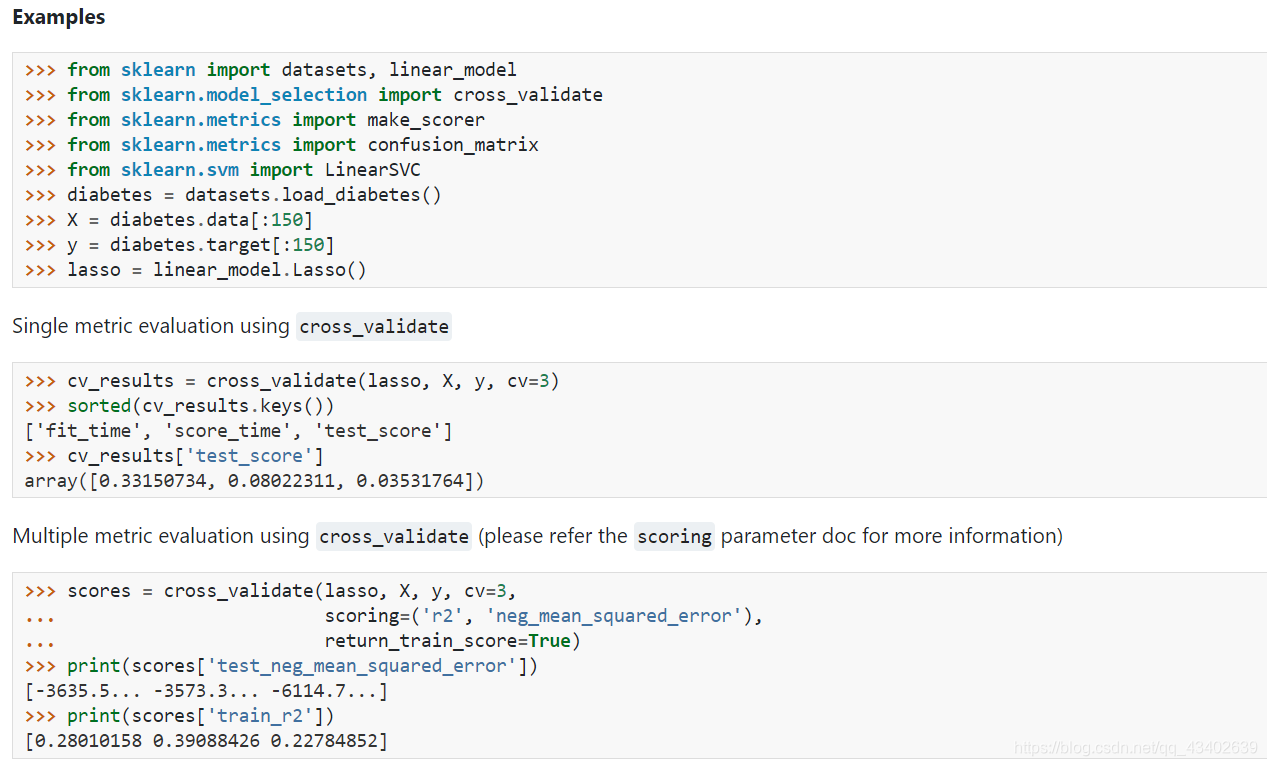
因为训练集的数据较小,所以采用交叉验证的方式构建模型。
这里用到sklearn的cross_validate方法
cross_validate官方文档
import warnings
#忽略警告
warnings.filterwarnings("ignore")
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from svm import LinearSVC
from svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier,BaggingClassifier,GradientBoostingClassifier,RandomForestClassifier,StackingClassifier,VotingClassifier
from sklearn.model_selection import cross_validate
from sklearn.linear_model import LogisticRegression,RidgeClassifier,SGDClassifier
LR = LogisticRegression()
cv_results = cross_validate(LR, X, y, cv=10)
print(cv_results['test_score'].mean())
RC = RidgeClassifier()
cv_results = cross_validate(RC, X, y, cv=10)
print(cv_results['test_score'].mean())
SGD = SGDClassifier()
cv_results = cross_validate(SGD, X, y, cv=10)
print(cv_results['test_score'].mean())
0.7957428214731586
0.7934956304619225
0.7698751560549313
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
GNB = GaussianNB()
cv_results = cross_validate(GNB, X, y, cv=10)
print(cv_results['test_score'].mean())
KNN = KNeighborsClassifier()
cv_results = cross_validate(KNN, X, y, cv=10)
print(cv_results['test_score'].mean())
DTC = DecisionTreeClassifier()
cv_results = cross_validate(DTC, X, y, cv=10)
print(cv_results['test_score'].mean())
0.7867915106117354
0.8002621722846441
0.7789637952559301
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
LSVC = LinearSVC()
cv_results = cross_validate(LSVC , X, y, cv=10)
print(cv_results['test_score'].mean())
SVC = SVC()
cv_results = cross_validate(SVC , X, y, cv=10)
print(cv_results['test_score'].mean())
0.7912484394506867
0.8260674157303372
from sklearn.ensemble import AdaBoostClassifier,BaggingClassifier,GradientBoostingClassifier,RandomForestClassifier
ABC = AdaBoostClassifier()
cv_results = cross_validate(ABC , X, y, cv=10)
print(cv_results['test_score'].mean())
BC = BaggingClassifier()
cv_results = cross_validate(BC , X, y, cv=10)
print(cv_results['test_score'].mean())
GBC = GradientBoostingClassifier()
cv_results = cross_validate(GBC , X, y, cv=10)
print(cv_results['test_score'].mean())
RFC = RandomForestClassifier()
cv_results = cross_validate(RFC , X, y, cv=10)
print(cv_results['test_score'].mean())
0.813732833957553
0.8115106117353308
0.8328089887640449
0.8204993757802747
# Stacking和Voting是需要提供基分类器的,基于前面的分类表现,这里选择RFC,LR,KNN,SVC作为基分类器,并且将SVC作为Stacking的最后的分类器。
from sklearn.ensemble import StackingClassifier,VotingClassifier
estimators = [
('RFC', RFC),
('LR', LR),
("KNN",KNN),
("SVC",SVC)
]
SC = StackingClassifier(estimators=estimators, final_estimator=SVC)
cv_results = cross_validate(SC , X, y, cv=10)
print(cv_results['test_score'].mean())
VC = VotingClassifier(estimators=estimators)
cv_results = cross_validate(VC , X, y, cv=10)
print(cv_results['test_score'].mean())
0.8260549313358302
0.8226841448189763
测试集预测
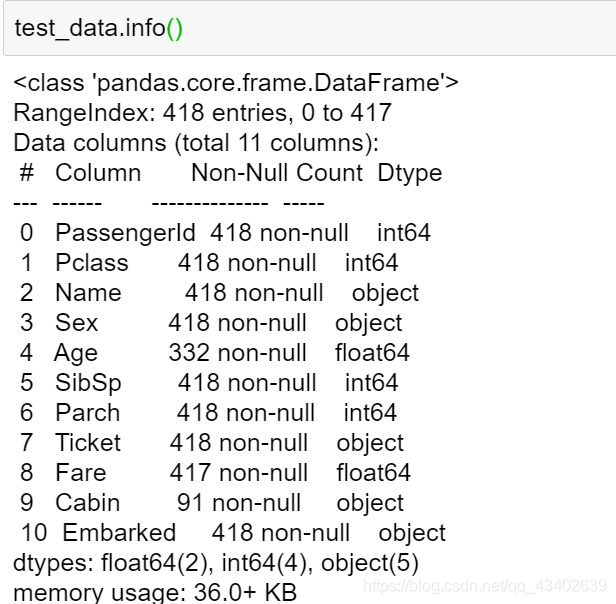
读取测试集,查看基本信息,发现Age和Fare存在缺失值,所以除了要额外处理Fare的缺失值,其余的操作和train_data一致
#读取测试数据
test_data = pd.read_csv('test.csv')
PassengerId = test_data['PassengerId']
# 删除无关列
test_data.drop(columns=['PassengerId','Cabin', 'Name', 'Ticket'],inplace=True)
# 缺失值处理 中值或者KNNImputer
values = {'Embarked': 'C'}
test_data.fillna(value=values,inplace=True)
imputer = KNNImputer()
test_data[['Age','Fare']] = imputer.fit_transform(test_data[['Age','Fare']])
#将离散型值转换为数值Categorical
def labelEncoding():
le = LabelEncoder()
test_data['Embarked'] = le.fit_transform(test_data['Embarked'])
test_data['Sex'] = le.fit_transform(test_data['Sex'])
labelEncoding()
# 标准化
scaler = StandardScaler()
test_data = scaler.fit_transform(test_data)
GBC = GradientBoostingClassifier().fit(X,y)
test_y = GBC.predict(test_data)
predict = pd.DataFrame()
predict['PassengerId'] = PassengerId
predict['Survived'] = test_y
predict.to_csv('predic.csv',index=False)
提交答案查看结果
比训练集真是差了挺多。
部分:
GBClassifier
KNN

StackingClassifier

SVC

改进
受别人的code启示,发现其实Name大有文章,其中的前缀,决定了乘客的身份,而乘客的身份和存活率是存在很大关系的,比如乘客是船长,他存活的可能性基本为零了…提取name特征中的prefix,统计不同类别下存活率。果然。
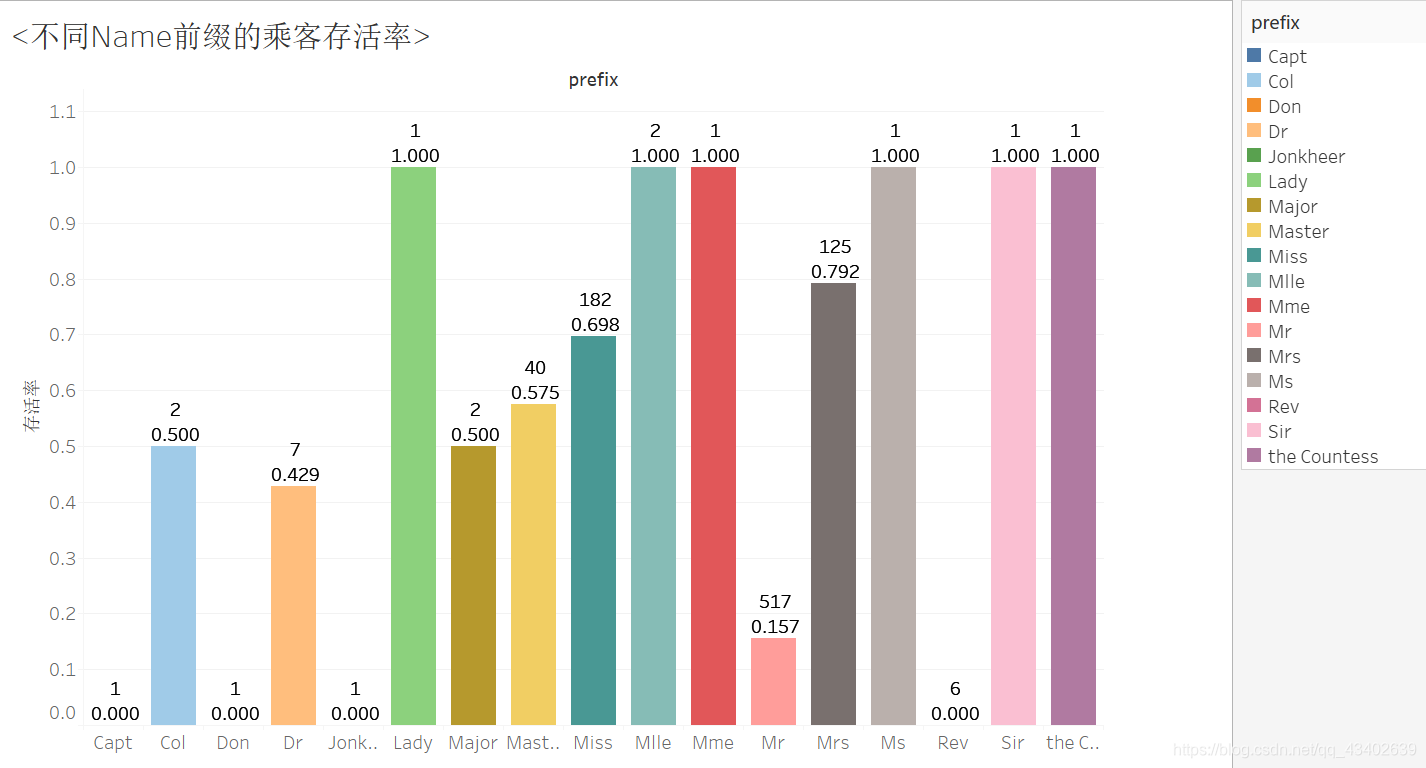
所以加入新特征,prefix,并作特征转换。
# 新增特征
train_data['prefix'] = train_data['Name'].apply(lambda x : x.strip().split(',')[1].strip().split('.')[0])
还是有进步的

完整代码
https://github.com/wang-hui-shan/titanic














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









