







学习链接:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
目录
0、安装 P1/2
先在anaconda中创建一个虚拟环境叫做pytorch
conda create -n pytorch python=3.6
之后可以激活这个环境
conda activate pytorch
conda deactivate
但此时这个名字叫做“pytorch”的房间里面还是没有pytorch包(相当于只是一个新建文件夹)
真正的pytorch安装链接:pytorch官网
我的这个实验室电脑没有独显,所以选择CPU版本
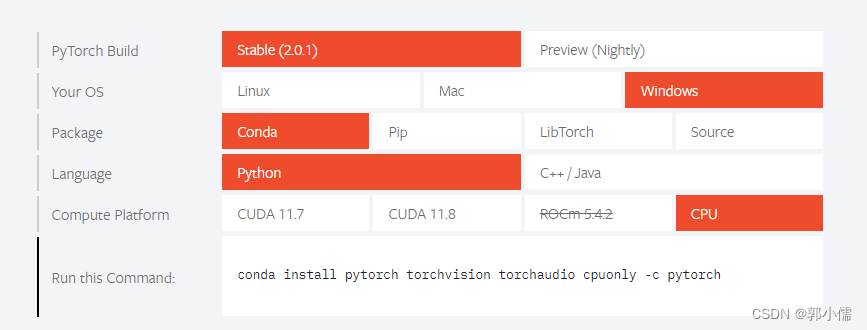
conda install pytorch torchvision torchaudio cpuonly -c pytorch
记录一下有独显的电脑,CUDA 最好选择9.2,因为10以上有时候会有问题,我之后安装看一下
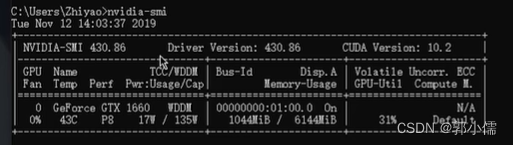
首先检查电脑是否有独显,打开cmd.exe,输入nvidia -smi,CUDA9.2以上只支持Driver Version>396.26以上
然后可以在pycharm中使用,或者用Jupiter
首先先进入pytorch虚拟环境,然后安装ipython包
conda install nb_conda
然后输入
jupyter notebook
酱酱,,like this:

然后再google网页中就有了
之后选择虚拟环境pytorch
小tip:shift+enter就是到下一个代码块

False是因为我的电脑没有独显
参考链接:pytorch安装
** python学习两大法宝函数P4 **
- dir():打开,看见工具箱(包)中有什么
小tip:ctrl+f可以搜索对应模块 - help():说明书,能知道每个工具的使用方法
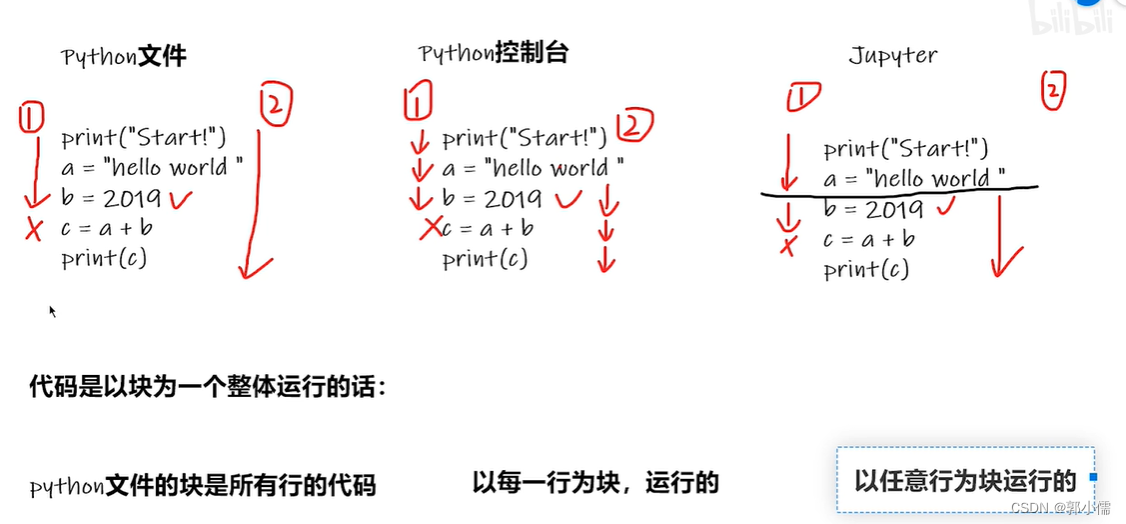
pycharm和pycharm控制台和jupyter的区别
1、导入数据P6/P7
导入数据使用两个类:
Dataset:
Dataloader:
下载数据集:蚂蚁蜜蜂分类数据集
导入Dataset类
from torch.utils.data import Dataset
jupyter运行,之后使用help()或者Dataset??可以看到官方的帮助文档
安装opencv包的时候学习到了一个新方法,不是再打开anaconda prompt,而是直接在pycharm里面的终端(terminal)进行:
这个语句显示有问题,我在anaconda.org中使用另一个语句下载的cv2
conda install -c fastchan opencv
土堆(up)觉得下载有点太大了,就换成了另一个语句来导入数据
from PIL import Image
然后在控制台导入图片地址:
from torch.utils.data import Dataset
from PIL import Image
import os #python中系统的库
class MyData(Dataset):#创建一个自已的类MyData,继承Dataset中的内容
def __init__(self,root_dir,label_dir):#初始化类,为整个类提供全局变量root_dir,label_dir
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(root_dir,label_dir) #将根路径"hymenoptera_data/hymenoptera_data/train"和ants路径"ants"合并
self.img_path = os.listdir(self.path) #获取这个路径下所有图片的列表
def __getitem__(self, idx):
img_name = self.img_path[idx] #获得这个图片的名称:'0013035.jpg'
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #获得了对应序号的图片的相对路径
img = Image.open(img_item_path)
label = self.label_dir #ants or bees
return img,label #返回图片和图片所属的类别
def __len__(self):
return len(self.img_path) #返回图片列表的长度
root_dir = "hymenoptera_data/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset
2、tensorboard的使用 P8/P9
(1)、安装tensorboard包
conda install -c conda-forge tensorboard
(2)、SummaryWriter类
查看help:小tips:在pycharm中,按下ctrl+点击对应的类名(SummaryWriter)
A、add_scalar()函数
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for i in range(100):
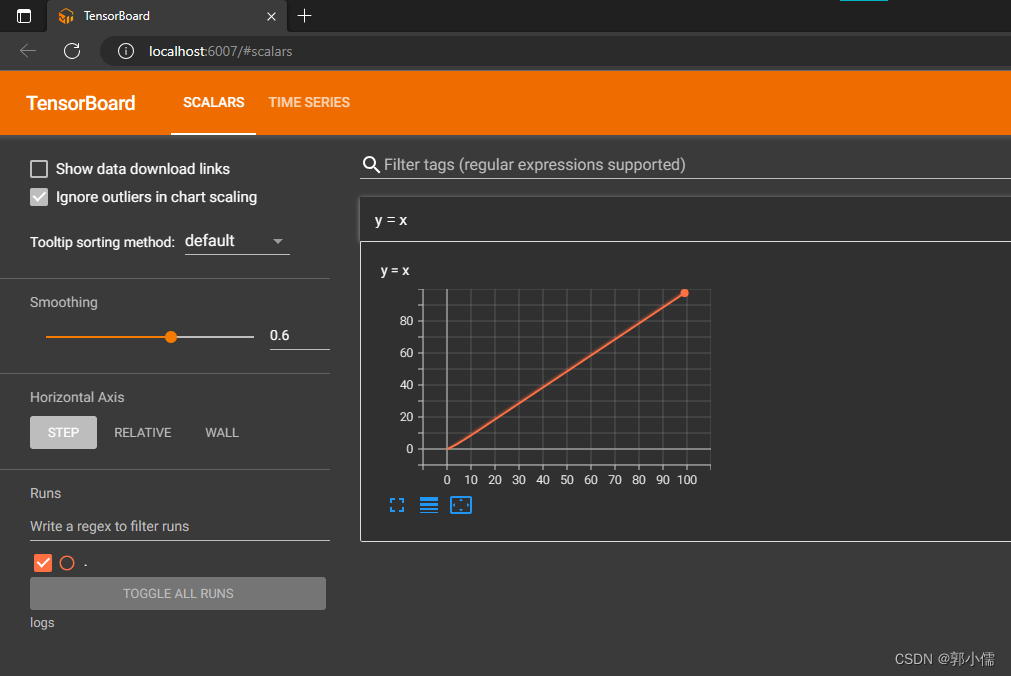
writer.add_scalar("y = x",i,i) # scalar: 标量
writer.close()
运行后会生成logs文件夹,可以在pycharm中的终端开出一个端口来看这个图像,具体操作:
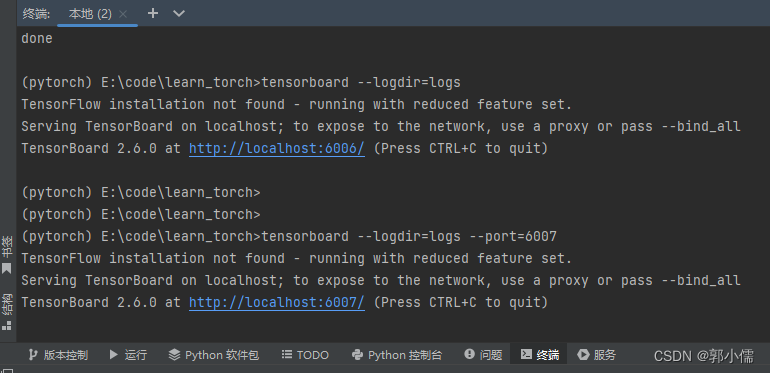
之后打开端口对应的网页就能看到图像
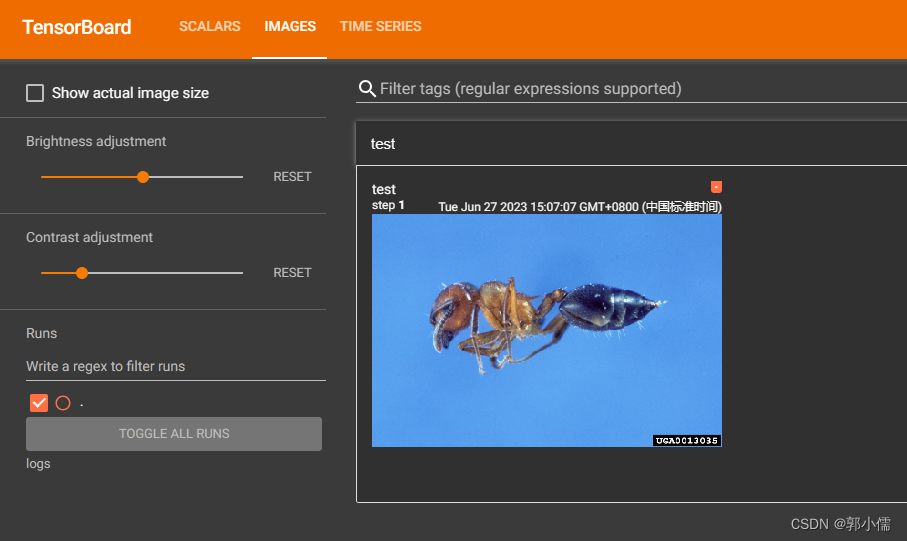
 B、add_image()函数
B、add_image()函数
# add_image()函数:画图片
from PIL import Image
import numpy as np
img_path = "hymenoptera_data/hymenoptera_data/train/ants/0013035.jpg"
img = Image.open(img_path)
print(type(img))
img_array = np.array(img)
print(type(img_array)) #转换成numpy类型才能输入到add_image中
writer.add_image("test",img_array,1,dataformats='HWC') #dataformats='HWC':代表图片格式,可以通过控制台查看
writer.close()
3、transforms的使用 P10/P11
是啥:pytorch提供的torchvision.transforms 模块是专门用来进行图像预处理的,包括对图片进行剪切、翻转、平移、仿射等操作。

4、torchvision中数据集的使用 P14
tochvision主要处理图像数据,包含一些常用的数据集、模型、转换函数等。torchvision独立于PyTorch,需要专门安装。
torchvision主要包含以下四部分:
torchvision.models: 提供深度学习中各种经典的网络结构、预训练好的模型,如:Alex-Net、VGG、ResNet、Inception等。
torchvision.datasets:提供常用的数据集,设计上继承 torch.utils.data.Dataset,主要包括:MNIST(手写数字)、CIFAR10/100(物体识别)、ImageNet、COCO(目标检测)等。
torchvision.transforms:提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
torchvision.utils:工具类,如保存张量作为图像到磁盘,给一个小批量创建一个图像网格。
来源:添加链接描述
2、入门:
张量: 基于向量和矩阵的推广,是一种新的数据类型
张量:基于向量和矩阵的推广,是一种新的数据类型
0维张量 代表的是标量(数字)
1维张量 代表的是向量
2维张量 代表的是矩阵
3维张量 时间序列数据 股价 文本数据 单张彩色图片(RGB)
4维 = 图像
5维 = 视频
它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
for example:
表示一个图像可以用三个变量表示:(width, height, channel) = 3D
那么表示100000张图像可以用4个变量:4D张量
(batch_size, width, height, channel) = 4D
**创建tensor **
torch.tensor(data, dtype=None, device=None,requires_grad=False)
x = torch.empty(5, 3) # 构造一个未初始化的5*3的矩阵
x = torch.rand(5, 3) # 构造一个随机初始化的矩阵
x = torch.zeros(5, 3, dtype=torch.long) #构造一个矩阵全为 0,而且数据类型是 long(长整型,是long int的缩写,长度至少32位).
x = torch.tensor([5.5, 3]) #构造一个张量 输出:tensor([5.5000, 3.0000])
x = x.new_ones(4, 3, dtype=torch.double)
# 创建一个新的全1矩阵tensor,返回的tensor默认具有相同的torch.dtype tensor类型(dtype=torch.float64)和torch.device 返回的设备(device=torch.device('cuda:0'))
# 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
3、pytorch的主要组成模块:
(1)、基本配置
- 导入包
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
其他:比如涉及到表格信息的读入很可能用到 pandas ,对于不同的项目可能还需要导入一些更上层的包如cv2等。如果涉及可视化还会用到 matplotlib、seaborn 等。涉及到下游分析和指标计算也常用到 sklearn。
- 设置超参数
batch_size = 16
# 批次的大小
lr = 1e-4
# 优化器的学习率
max_epochs = 100
除了直接将超参数设置在训练的代码里,我们也可以使用yaml、json,dict等文件来存储超参数,这样可以方便后续的调试和修改
- 设置GPU:默认是CPU,为了加速模型的训练,需要调研GPU
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
(2)、数据读入
Dataset+DataLoade:Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
学习链接:深入浅出pytorch
















 2880
2880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











