







文章目录
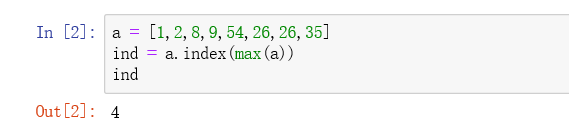
- 1、返回列表最大元素的索引
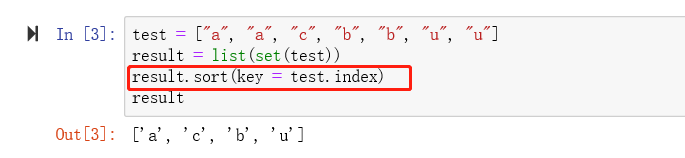
- 2、将列表元素去重并保持原有顺序
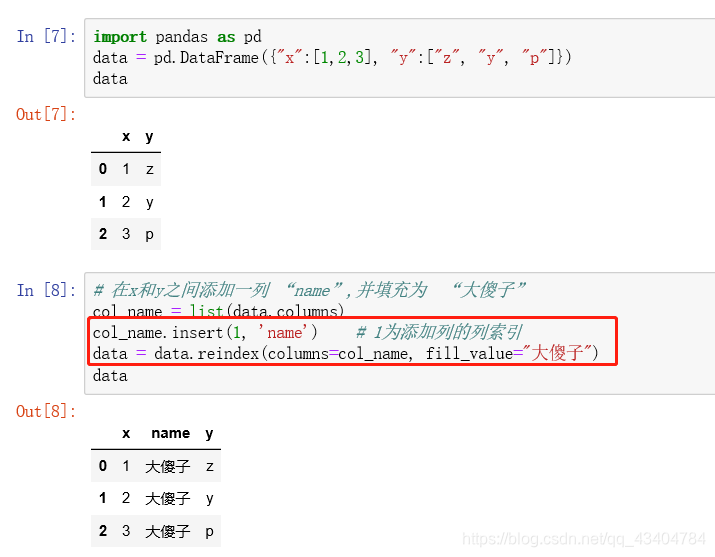
- 3、数据框指定位置添加列
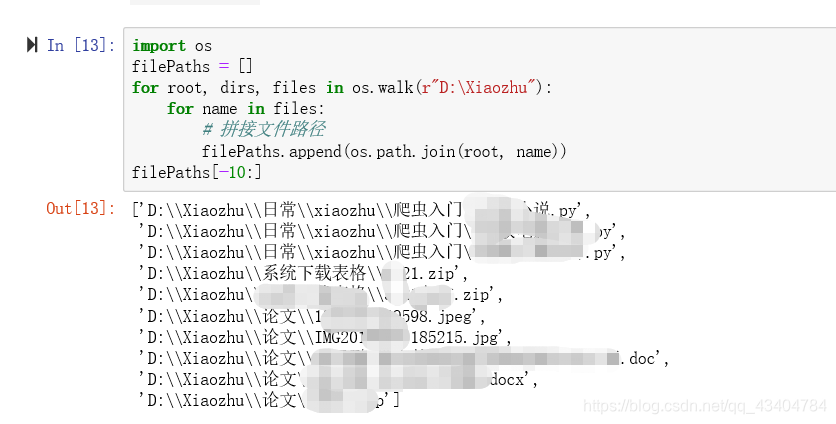
- 4、获得某个文件夹下所有文件名称(包括子文件夹内的文件)
- 5、获取N天之前,或者N天之后的日期 *`“%Y-%m-%d %H:%M:%S”`*
- 6、获取两个日期之间相差的天数
- 7、返回今日日期、此时此刻、构造日期
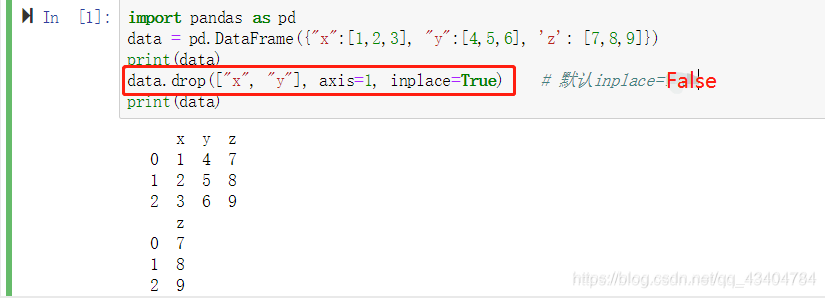
- 8、删除数据框多个列
- 9、匹配中文 `u"[\u4e00-\u9fa5/]+"`
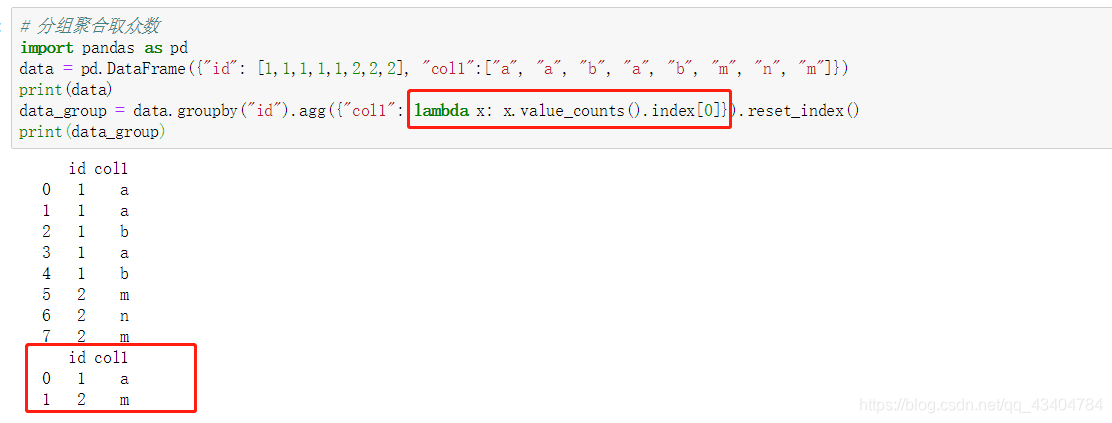
- 10、分组聚合取众数 `lambda x: x.value_counts().index[0]`
- 11、根据链接保存图片
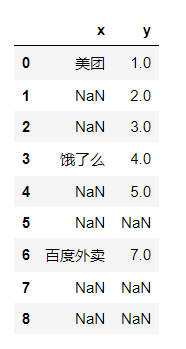
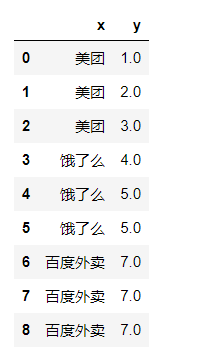
- 12、数据框向下填充空值 `data.fillna(method='ffill')`
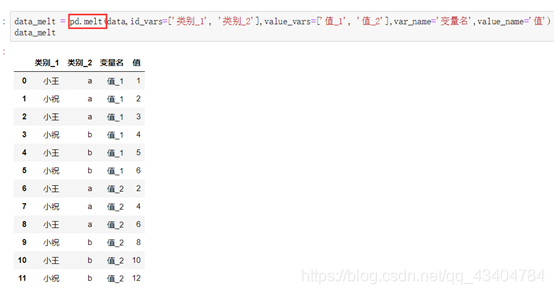
- 13、部分列变行 `pd.melt(df,id_vars=['**'],value_vars=['**'],var_name='**',value_name='***')`
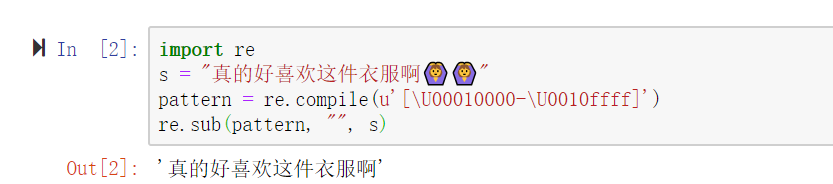
- 14、删除颜文字 `pattern = re.compile(u'[\U00010000-\U0010ffff]')`
- 15、排列组合
- 16、通过Dataframe建立数据库表格
1、返回列表最大元素的索引
2、将列表元素去重并保持原有顺序
3、数据框指定位置添加列
4、获得某个文件夹下所有文件名称(包括子文件夹内的文件)
5、获取N天之前,或者N天之后的日期 “%Y-%m-%d %H:%M:%S”
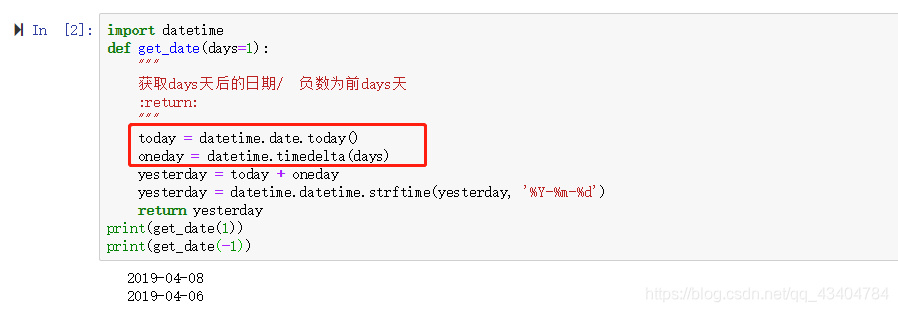
6、获取两个日期之间相差的天数

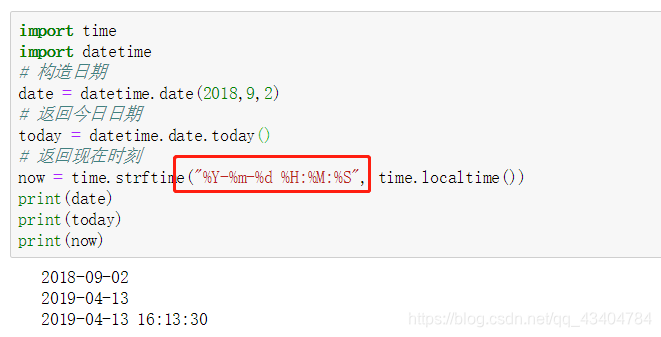
7、返回今日日期、此时此刻、构造日期
8、删除数据框多个列
9、匹配中文 u"[\u4e00-\u9fa5/]+"

10、分组聚合取众数 lambda x: x.value_counts().index[0]
11、根据链接保存图片
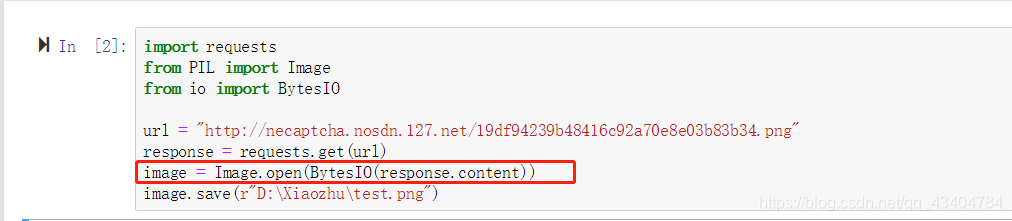
12、数据框向下填充空值 data.fillna(method='ffill')

13、部分列变行 pd.melt(df,id_vars=['**'],value_vars=['**'],var_name='**',value_name='***')

14、删除颜文字 pattern = re.compile(u'[\U00010000-\U0010ffff]')
15、排列组合
C
5
2
的
实
现
如
下
所
示
:
C_{5}^{2}的实现如下所示:
C52的实现如下所示:
from itertools import combinations

A
5
2
的
实
现
如
下
所
示
:
A_{5}^{2}的实现如下所示:
A52的实现如下所示:
from itertools import permutations

16、通过Dataframe建立数据库表格
# 将数据写入mysql的数据库,但需要先通过sqlalchemy.create_engine建立连接,且字符编码设置为utf8,否则有些latin字符不能处理
# coding=utf-8
import pandas as pd
import pymysql # 数据库模块
pymysql.install_as_MySQLdb() # 引入mysqldb不然会出错
from sqlalchemy import create_engine # 引入sqlalchemy #引擎
data = pd.read_excel(r"E:\桌面\xz\666.xls")
# 创建连接
yconnect = create_engine('mysql+mysqldb://xiaozhu:用户名@数据库id:3306/数据库名称?charset=utf8')
# 创建数据库
pd.io.sql.to_sql(data, '表名', con=yconnect, schema='数据库名称', if_exists='append')














 2023
2023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









