







前言
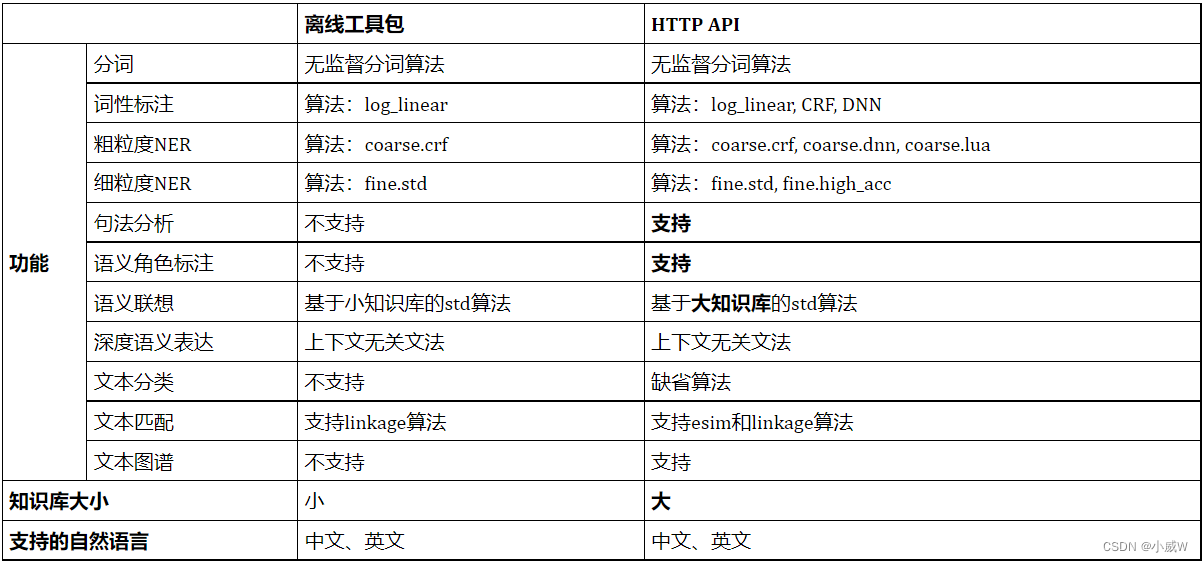
TexSmart 是由 腾讯人工智能实验室的 自然语言处理(NLP)团队 开发的一套自然语言理解工具与服务, 用以对中文和英文两种语言的文本进行词法、句法和语义分析。 除了支持分词、词性标注、命名实体识别(NER)、句法分析、语义角色标注、文本分类、文本匹配、文本规范化(自动恢复英文大小写)等常见功能外, TexSmart还提供细粒度命名实体识别、语义联想、深度语义表达等特色功能。 此外,我们还增加了文本图谱模块,支持对短文本或单词进行多种重要关系的知识查询。 文本理解技术广泛应用于搜索、个性化推荐、广告匹配、智能对话等场景, 用来对自然语言文本进行结构化分析与处理。
本文对如何使用进行介绍,提供了一个python的代码示例。
功能说明
代码示例
# -*- coding: utf8 -*-
import json
import requests
obj = {
"str": "他在看流浪地球。",
"options":
{
"input_spec": {"lang": "chs"},
"word_seg": {"enable": True},
"pos_tagging": {"enable": True, "alg": "log_linear"},
"ner": {"enable": True, "alg": "fine.std"},
"syntactic_parsing": {"enable": False},
"srl": {"enable": True},
"text_cat": {"enable": False},
}
}
req_str = json.dumps(obj).encode()
url = "https://texsmart.qq.com/api"
r = requests.post(url, data=req_str)
r.encoding = "utf-8"
print(r.text)
print("***********")
print(json.loads(r.text))
其中,input_spec表示输入的语言种类,它有三个取值,分别是自动识别语言(“auto”),中文(“chs”)和英文(“en”)。
”enable”可以取”true”或”false”,表示是否要激活对应的功能。
”alg”表示对应的功能需要调用什么算法,
”pos_tagging”中的”alg”有三种选择(“crf”, “dnn”, “log_linear”),
”ner“中的”alg”有五种选择(“coarse.crf”, “coarse.dnn”, “coarse.lua”, “fine.std"和"fine.high_acc”), ”coarse\fine”表示返回的是粗粒度/细粒度NER的结果。
“syntactic_parsing”, “srl”, "text_cat"分别表示句法分析、语义角色标注和文本分类工具;它们默认为缺省值。
”echo_data“的取值由用户自由定义,用户可以用它来记录当前request的标识信息,如request_id,它在异步调用等场合可能会有用。
参考资料
https://texsmart.qq.com/
https://ai.tencent.com/ailab/nlp/texsmart/zh/index.html
https://ai.tencent.com/ailab/nlp/texsmart/zh/instructions.html

















 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











