







 该文介绍了一个大规模的、带注释的早餐动作数据集,包含10种不同的烹饪活动,如juicecereals,由52位参与者在18个厨房环境中自然执行。数据集共有超过77小时的视频,旨在促进对目标导向人类活动的语法和语义恢复的研究。
该文介绍了一个大规模的、带注释的早餐动作数据集,包含10种不同的烹饪活动,如juicecereals,由52位参与者在18个厨房环境中自然执行。数据集共有超过77小时的视频,旨在促进对目标导向人类活动的语法和语义恢复的研究。
Breakfast(The Breakfast Action Dataset)
简介
早餐动作数据集包括与早餐准备相关的10个动作,由18个不同厨房的52个不同的人执行。该数据集是最大的完全带注释的数据集之一。这些动作是在“自然环境下”记录的,而不是在单一的受控实验室环境中记录的。它由超过77小时(>4万帧)的录像组成。为了减少数据总量,所有视频都被下采样到320×240像素的分辨率,帧速率为15 fps。
来源:
@article{HildeKuehne2014TheLO,
title={The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities},
author={Hilde Kuehne and Ali Bilgin Arslan and Thomas Serre},
journal={Computer Vision and Pattern Recognition},
year={2014}
}
主页:https://serre-lab.clps.brown.edu/resource/breakfast-actions-dataset/

细节
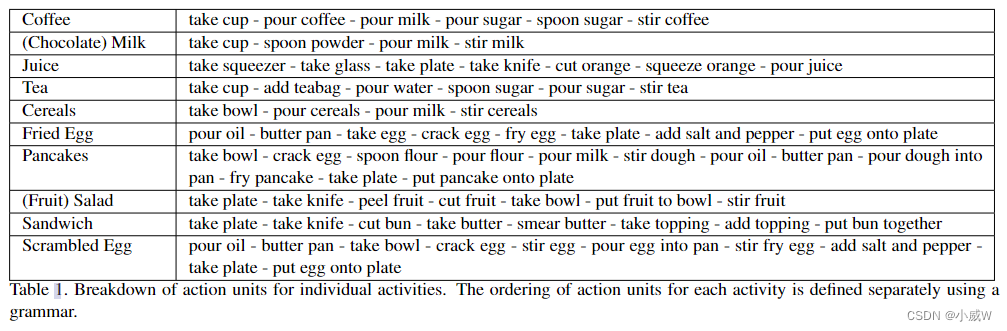
Cooking actibities
一共 10 种,包括:

illustration of the actions
juice
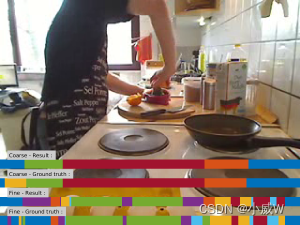
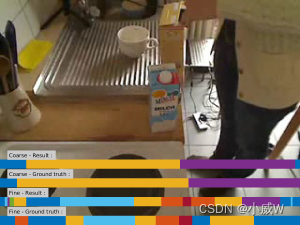
cereals
论文讲解
参见论文中第三章:Breakfast dataset
相关内容:
An end-to-end generative framework for video segmentation and recognition
The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities



















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











