







前言
论文地址: Understanding the difficuty of training deep feedforward neural networks
发表于 2010年
Abstract
作者写此文目的就是位了更清楚直观的理解,为什么随机初始化网络参数会让梯度下降优化DNN的效果变得很差。
作者先是研究了非线性激活函数对优化效果的影响,发现sigmoid并不适合作为DNN的激活函数,因为它很容易饱和。
作者还发现了当一个达到饱和了的神经元可能会在后续训练过程中自己恢复未饱和状态。
另外,训练过程中,如果梯度矩阵(雅可比矩阵)的奇异值远大于1或者远小于1,就会造成优化困难问题。基于此,作者提出了一种可以让优化更快收敛的初始化参数的方法,即Xavier方法
Our objective here is to understand better why standard gradient descent from random initialization is doing so poorly with deep neural networks, to better understand these recent relative successes and help design better algorithms in the future. We first observe the influence of the non-linear activations functions. We find that the logistic sigmoid activation is unsuited for deep networks with random initialization because of its mean value, which can drive especially the top hidden layer into saturation. Surprisingly, we find that saturated units can move out of saturation by themselves, albeit slowly, and explaining the plateaus sometimes seen when training neural net works. We find that a new non-linearity that saturates less can often be beneficial. Finally, we study how activations and gradients vary across layers and during training, with the idea that training may be more difficult when the singular values of the Jacobian associated with each layer are far from 1. Based on these considerations, we propose a new initialization scheme that brings substantially faster convergence.
一.Deep Neural Networks
在这一部分,作者简单介绍了一下DNN,如果想让DNN拥有更强的表示能力,那么必须让其层数更多,隐藏单元更多。
Theoretical results reviewed and discussed by Bengio (2009), suggest that in order to learn the kind of complicatedfunctionsthatcanrepresenthigh-levelabstractions (e.g. in vision, language, and other AI-level tasks), one may need deep architectures.
二.Experimental Setting and Datasets
作者在这部分主要介绍了论文中进行实验使用的数据集以及模型参数。
1.Infinite Dataset
Shapeset-3x2 该数据集是作者自己合成的,每副图片均是RGB彩色图像,大小为
32
×
32
32\times 32
32×32,其中包含了1个或者2个图形(平行四边形、三角形、椭圆之一),这两个图形可以互相覆盖,但是覆盖面积不能超过被覆盖的50%,并且每个图形会有旋转、放缩等变换,每个样本有9种可能的标签(
c
3
2
+
3
+
3
c^2_3+3+3
c32+3+3)。这个数据集是无限大的,因为这是作者自己生成的。

2.finite Dataset
在选择有穷数据集上,作者使用了如下三个数据集
- MNIST
- CIFAR-10
- Small-ImageNet
3.ExperimentalSetting
作者在进行实验时,DNN的有5个隐藏层数,每层有1000个隐藏单元,输出层使用的是softmax回归,使用批量随机梯度下降法进行优化参数。
We optimized feedforward neural networks with one to five hidden layers, with one thousand hidden units per layer, and with a softmax logistic regression for the output layer.
作者对选择sigmoid、tanh、softsign分别作为DNN的激活函数,以此比较其性能。
We varied the type of non-linear activation function in the hidden layers
作者在初始化参数时,使用的是uniform distribution,如下

三、激活函数对训练的影响
1.sigmoid function

从上图可以看到最后一层隐藏层的激活值迅速达到了饱和(0区域附近),但是随着训练的进行,又会慢慢的跳出饱和区(当然了这个想要跳出饱和区是需要很长的训练时间的)。
作者推测上述产生上述问题的原因如下:
因为网络的初始权重在最开始是被随机初始化的,所以在最开始,每一层的输出都的随机的,对分类的结果影响非常小,对于最后一层的softmax回归 s o f t m a x ( w h + b ) softmax(wh+b) softmax(wh+b),因为h对分类基本没有作用,所以网络就让h趋向为0,,这个时候整个网络的分类结果就非常依赖于b了,但是不巧的是,sigmoid函数的饱和区就在0附近,所以导致梯度消失,无法训练。然而像tanh、softsign这些激活函数,其在0附近的值是梯度是比较大的,所以就可以比较轻松的训练。
We hypothesize that this behavior is due to the combina-
tion of random initialization and the fact that an hidden unit
output of 0 corresponds to a saturated sigmoid. Note that
deep networks with sigmoids but initialized from unsuper-
vised pre-training (e.g. from RBMs) do not suffer from
this saturation behavior. Our proposed explanation rests on
the hypothesis that the transformation that the lower layers
of the randomly initialized network computes initially is
not useful to the classification task, unlike the transforma-
tion obtained from unsupervised pre-training. The logistic
layer output softmax(b+ W h) might initially rely more on
its biases b (which are learned very quickly) than on the top
hidden activations h derived from the input image (because
h would vary in ways that are not predictive of y, maybe
correlated mostly with other and possibly more dominant
variations of x). Thus the error gradient would tend to
push Wh towards 0, which can be achieved by pushing
h towards 0. In the case of symmetric activation functions
like the hyperbolic tangent and the softsign, sitting around
0 is good because it allows gradients to flow backwards.
However, pushing the sigmoid outputs to 0 would bring
them into a saturation regime which would prevent gradi-
ents to flow backward and prevent the lower layers from
learning useful features. Eventually but slowly, the lower
2.tangent function and softsign function
下图即分别为使用tangent和sigsign,网络的中隐藏层激活值随训练过程的变化,可以发现tangent作为激活函数的时候,不会像sigmoid函数一样,而是每一层逐渐达到饱和状态,第一层最先饱和。但是softsign就不会有这种情况

下图为训练完成后,各个层激活值的分布直方图,上为tanh,下为softsign。可以明显看到softsign作为激活函数,其效果要好很多,因为其函数激活值大部分分布在[0.4,0.8]([-0.8,-0.4])之间,该区域不饱和而且是非线性的,但是梯度较小,训练起来可能较慢。

四.Gradients and their Propagation
4.1 Effect of the Cost Function
作者先是探究了损失函数对于优化的影响,下图黑色为使用cross entropy作为损失函数时的可视化,红色为quadratic cost作为损失函数时的可视化。可以看到,很明显cross entropy cost的损失函数更加陡峭,梯度更明显。而quadratic cost的损失函数则更加平稳,难以优化。

4.2 Gradientsatinitialization
Bradley在2009年发表论文,提出在初始化之后,反向传播的时候,从输出层到输入层梯度会越来越小
Bradley(2009)found that back-propagated gradients were smaller as one moves from the output layer towards theinputlayer,just after initialization
作者在此部分,提出一种初始化权重的方法normalized initializatio,如下
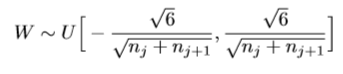
下图分别是随机初始化和normalized initialization初始化时,tangent作为激活函数各个层的激活值。可以看出,后者明显更稳定一些。

五、Error Curves and Conclusions
下图是基于Shapeset-3x2的分类任务时,不同模型的test error。可以发现使用normalized initialization初始化时,大大优化了Tanh作为激活函数的模型。

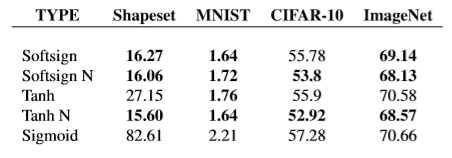
最终训练好的模型其test error如下
-
在训练过程中,监控隐藏层的激活值与梯度的在不同层之间的变化是很好的分析工具。
-
normalized initializatio 是一种比较好的初始化方法
-
softsign 作为激活函数时,效果要比tanh好很多,而且鲁棒性更好。
















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











