






- VOC2007数据集结构(目标检测+图像分割)
-
#VOC2007数据集结构如下: VOC2007 |-Annotations#里面存放的是每一张图片对应的标注结果,为XML文件, #标注完成后JPEGImages每张图片在此都有一一对应的xml文件 |-ImageSets#存放的是每一种类型对应的图像数据,为txt文件 |-Layout#存放的是具有人体部位的数据(如人的head、hand、feet等等) |-Main#存放的是图像物体识别的数据 |-Segmentation#存放的是可用于分割的数据 |-JPEGImages#存放的是原图片 |-SegmentationClass#按类别进行图像分割,同一类别的物体会被标注为相同颜色 |-SegmentationObject#按对象进行图像分割,即使是同一类别的物体会被标注为不同的颜色。本次的是目标检测,对应的如下结构
-
#VOC2007数据集结构如下: VOC2007 |-Annotations#里面存放的是每一张图片对应的标注结果,为XML文件, #标注完成后JPEGImages每张图片在此都有一一对应的xml文件 |-ImageSets#存放的是每一种类型对应的图像数据,为txt文件 |-Main#存放的是图像物体识别的数据 |-JPEGImages#存放的是原图片1、安装工具
此次数据标注使用labelImg工具,我是在pycharm终端中进行pip安装的,安装方式很多,就不一一列举了,还需要安装lxml库和pytq可以,安装步骤如下:
pip3 install labelImg
pip install lxml
pip install pytq进入标注工具,只需要在pycharm终端处输入LabelImg,LabelImg工具自动弹出打开,如下:
2、数据集准备
在VOC2007文件夹下创建这三个文件夹:

- Annotations文件夹该文件下存放的是xml格式的标签文件,每个xml文件都对应于JPEGImages文件夹的一张图片。
- JPEGImages文件夹:该文件夹下存放的是数据集图片(原图),包括训练和测试图片。把原图数据放到此文件夹下
- ImageSets文件夹该文件夹下存放了三个文件,分别是Layout、Main、Segmentation。在这里我们只用存放图像数据的Main文件
在ImageSets下创建Main文件夹,在该文件夹下创建如下4个txt文件:
- test.txt:测试集
- train.txt:训练集
- val.txt:验证集
- trainval.txt:训练和验证集
对数据重命名
- 处理代码:
import os
path = r"D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\JPEGImages" # JPEGImages文件夹所在路径
filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹)
count = 0
for file in filelist:
print(file)
for file in filelist: # 遍历所有文件
Olddir = os.path.join(path, file) # 原来的文件路径
if os.path.isdir(Olddir): # 如果是文件夹则跳过
continue
filename = os.path.splitext(file)[0] # 文件名
filetype = '.jpg' # 文件扩展名
Newdir = os.path.join(path, str(count).zfill(6) + filetype) # 用字符串函数zfill 以0补全所需位数
os.rename(Olddir, Newdir) # 重命名
count += 1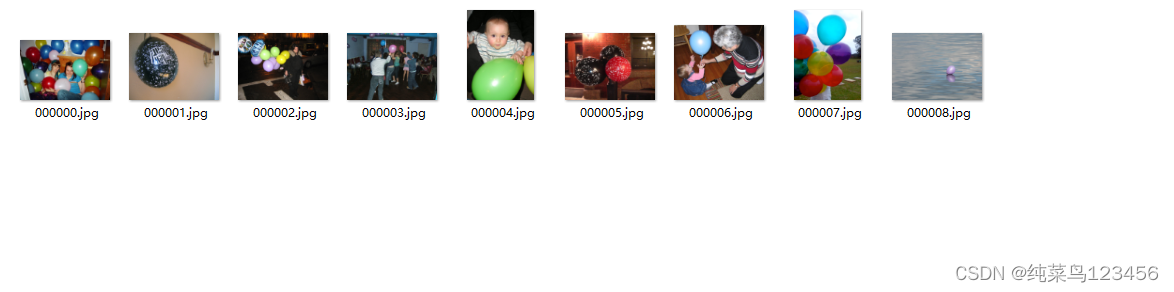
4、数据标注
- 添加标注数据集
安装好的工具,输入LabelImge打开标注工具,然后添加需要标注的数据文件夹,数据原图是放在JPEGImages‘文件夹中的,操作如下图: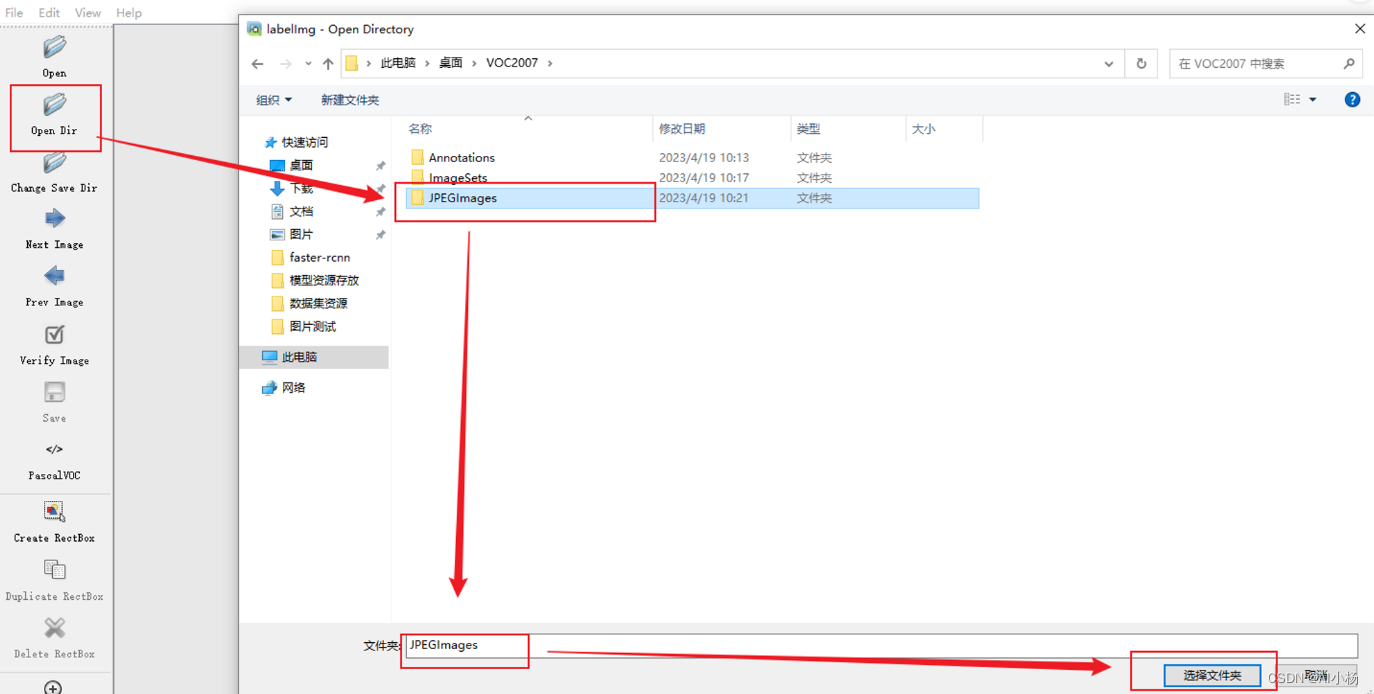
- 标注方式选择
标注方式选择Create rectBox矩形标注,或者选择快捷键w键快速标注:
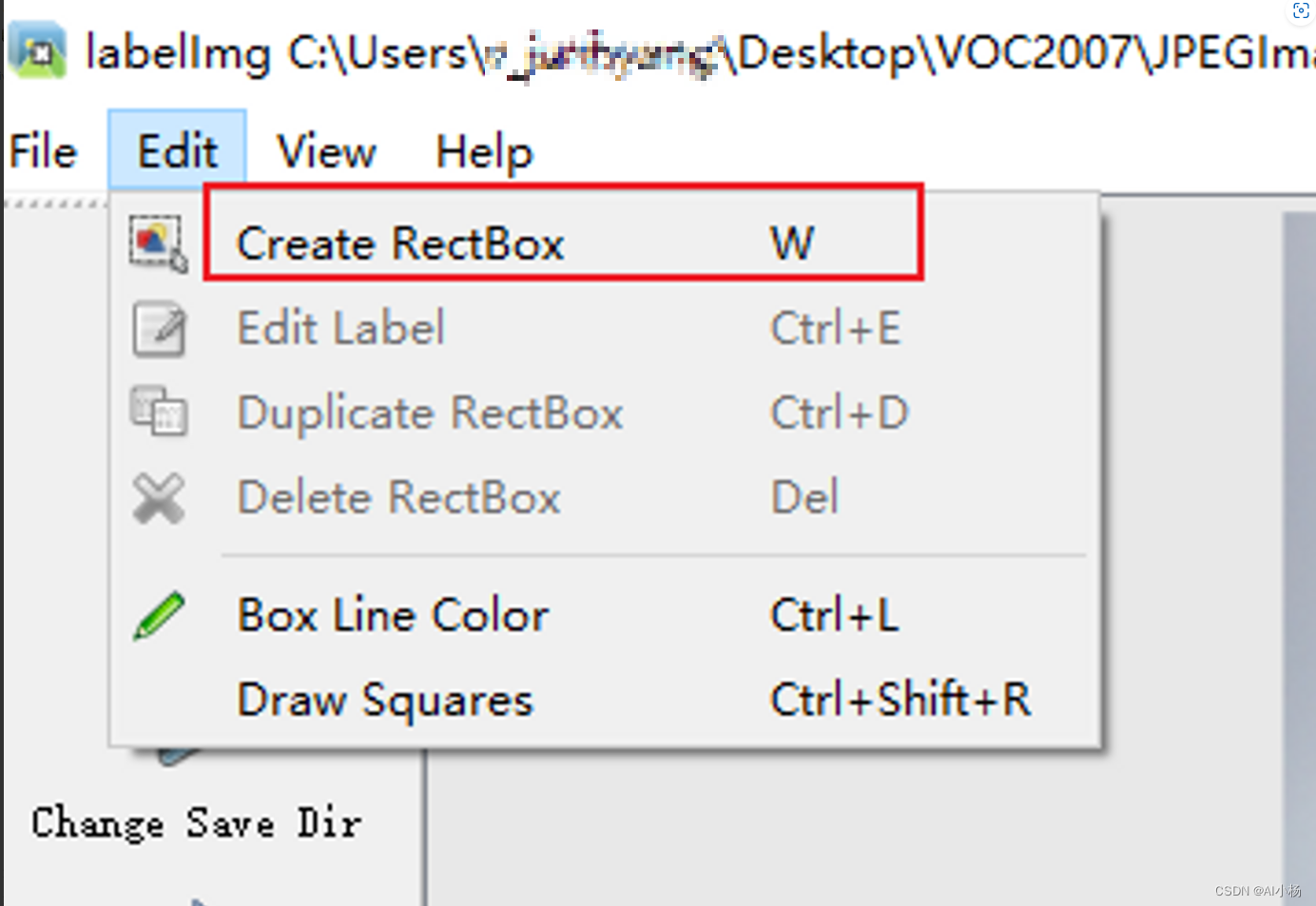
- 标注及标签设置
用框框住标注目标,标注完成后,弹出标签值框,输入需要添加的标签,点击ok: - 标注结果保存
标注结果默认方式每一次保存都需要选择保存文件夹,快捷键选择默认保存文件夹,使用快捷键Ctrl+r键,选择默认保存的文件夹为Annotation: 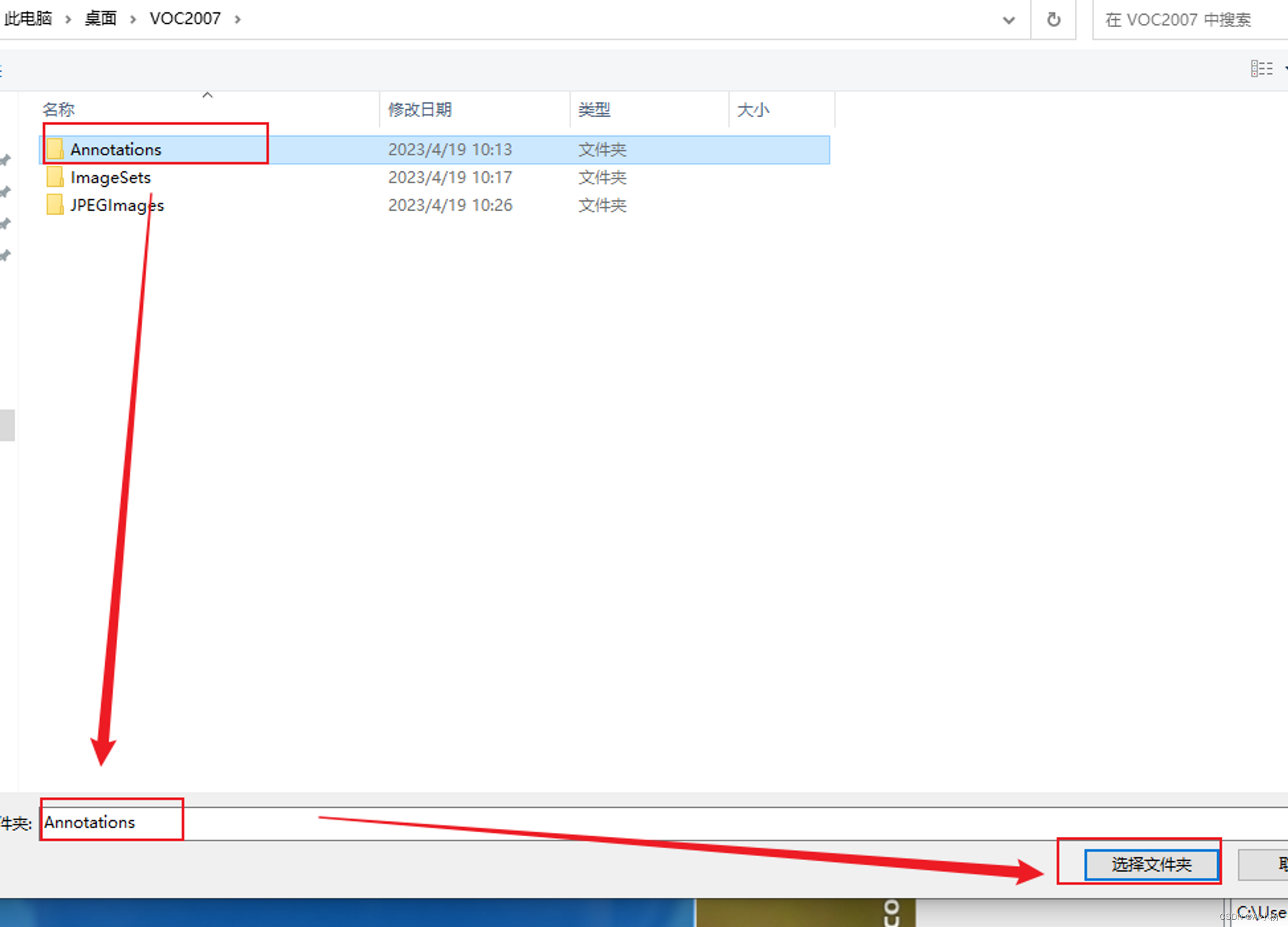 第一次标注设置好后,接下来就是快速标注,快捷键:
第一次标注设置好后,接下来就是快速标注,快捷键:
w键选择标注,Ctrl+s键保存,d键切换下一张图片直到标注完成。- 标注结果展示
标注好后,标注结果保存在VOC2007下的Annotation文件内,内容展示如下:
5、数据处理
- 对标注结果xml文件夹进行数据处理
import os import random trainval_percent = 0.9 # 验证集和训练集占的百分比 train_percent = 0.7 # 训练集占的百分比 xmlfilepath = r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\Annotations' # Annotation文件夹所在位置 txtsavepath = r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\ImageSets\Main' # ImageSets文件下的Main文件夹所在位置 total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) # Main文件夹下所对应的四个txt文件夹路径 ftrainval = open(r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\ImageSets\Main\trainval.txt', 'w') ftest = open(r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\ImageSets\Main\test.txt', 'w') ftrain = open(r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\ImageSets\Main\train.txt', 'w') fval = open(r'D:\pythonProject\ssd-pytorch\VOCdevkit\VOC2007\ImageSets\Main\val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()至此,VOC2007格式数据集制作完成。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









