







 本文讨论了如何在Python、Matlab、Origin等工具中绘制平行坐标图,作者分享了解决现有库问题、使用Matlab在线工具、以及找到更满意GitHub解决方案的过程,最终实现了更美观的图形用于论文展示。
本文讨论了如何在Python、Matlab、Origin等工具中绘制平行坐标图,作者分享了解决现有库问题、使用Matlab在线工具、以及找到更满意GitHub解决方案的过程,最终实现了更美观的图形用于论文展示。
早上起来拥抱太阳,写小论文,看到人家的图怎么那么好看!!??
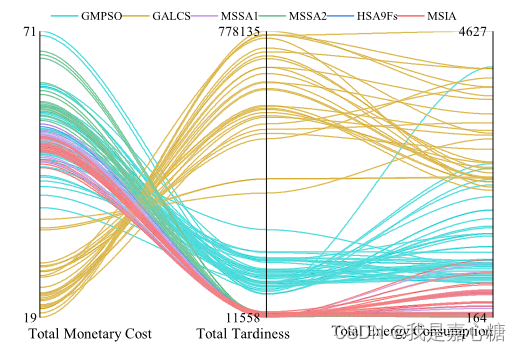
这不得赶紧抄下来,我也发一个顶刊?于是开始思考如何解决绘制这个问题,目前现有的大部分解决方案都是直接调库,查了一下现有的所有解决方案,
1.直接python调库
这篇文章直接调库,但是没有分类,而且也感觉不太好看
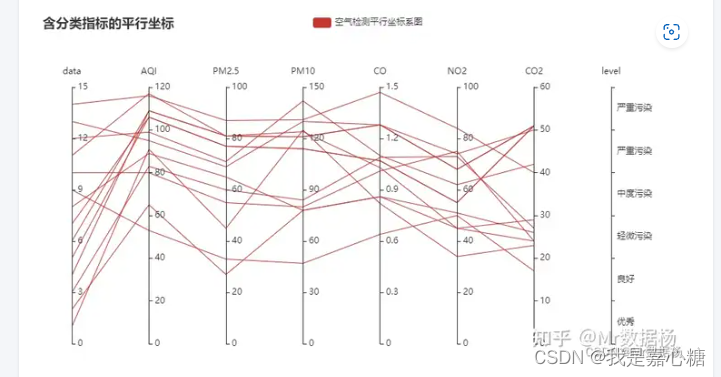
https://www.zhihu.com/question/571887313
这一个是调pandas库的,虽然有分类但是他的轴不能归一化调整。
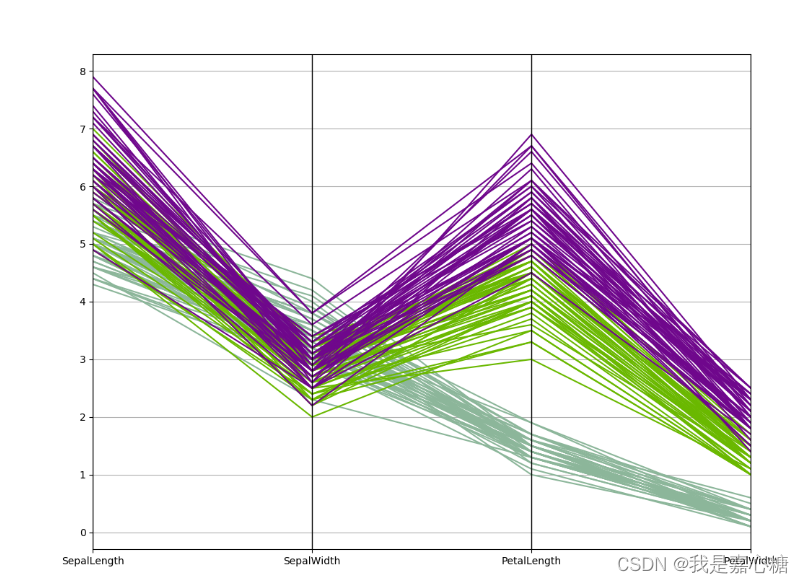
https://www.cnblogs.com/caiyishuai/p/12322671.html
2.matlab
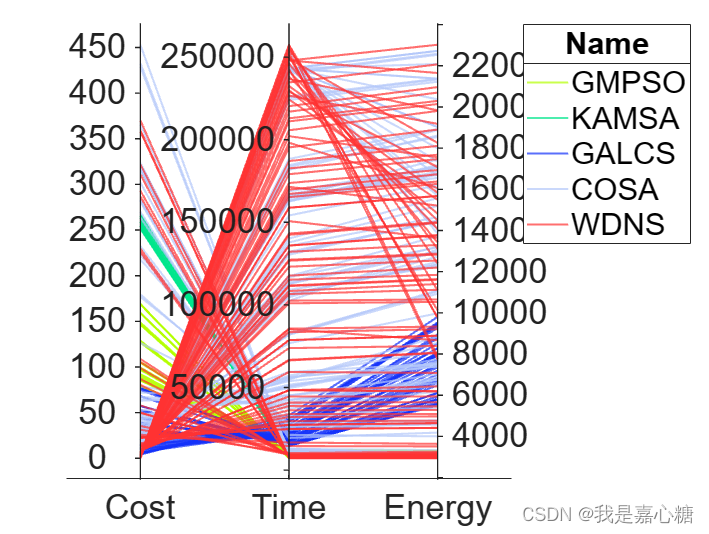
matlab作为强大的科研工具是众所周知的,他也提供了一个库来专门绘制平行坐标图。但是由于电脑内存不够,我就直接用线上matlab。经过学习之后,绘制出来这样的图,emmm老实说有点丑,但是指不定有人需要这个呢?
tbl = readtable('tt.csv');
head(tbl);
tbl.Name = categorical(tbl.Name);
p = parallelplot(tbl);
p.GroupVariable = 'Name';
p.CoordinateVariables = [3 2 4];
p.LineWidth = 1.5;
p.FontSize = 25;
p.Color = {'#B4FF00','#00E68C','#1432FA','#B4C8FA','#FF3232'}
%p.Color = {'#780001','#C11221','#FEF0D5','#002F49','#669BBB'}
其中csv的格式大概是这样的
cost time energy Name
0 2 20 GMPSO
0 8 90 KAMSA
6 5 30 COSA
太丑了还是下一个
3.用Origin绘制
Origin不愧是专业的绘图工具,绘制出来的图确实还不错。这里也是因为电脑内存原因所以我就没试着用Origin了。贴个参考文献:
https://cloud.tencent.com/developer/article/1623006?areaSource=102001.5&traceId=e-JyHo2xQfKU1fPJYmtbA
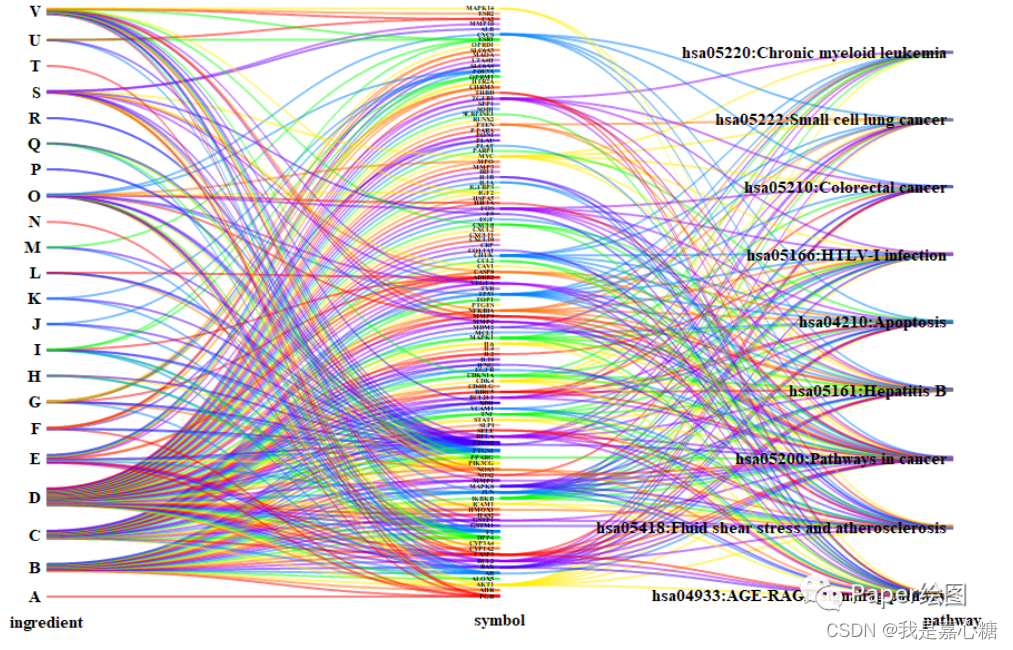
4.用高手做的轮子
上面尽管提供了三种方案,但是感觉也不能绘制出我想要的图形。于是乎我就上github寻找,肯定有大神。这个大神是我目前找到最满意的解决方案了。
https://github.com/jraine/parallel-coordinates-plot-dataframe
这个仓库提供了一个不错的解决方案,他能绘制出好看的平行坐标图,而且也不用引太多的库。
照着这个代码魔改了一下,我就绘制出来这样的图形了
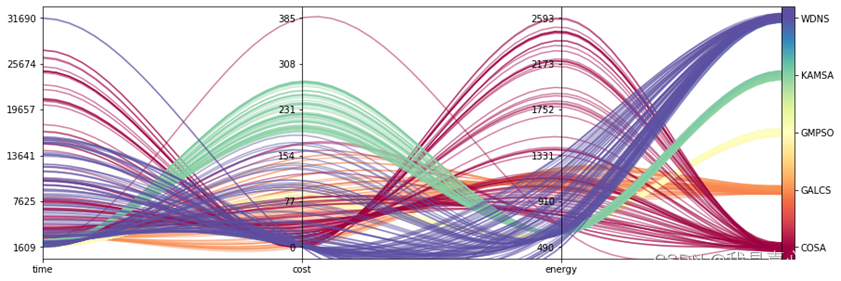
这不比上面的图要好看?我就是天才啊哈哈哈,现在先问问老师我最后一格要不要换成图例,不用的话论文就贴这个图了。下面是魔改后的代码:
import matplotlib
from matplotlib import ticker
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.interpolate import make_interp_spline
def read_and_add_method(file_path, method_name):
df = pd.read_csv(file_path)
if method_name == 'ChaoticOSA':
method_name = 'COSA'
if method_name == 'WDNMN':
method_name = 'WDNS'
df['method'] = method_name # 添加新列记录算法名
return df
def parallel_plot(df,cols,rank_attr,cmap='Spectral',spread=False,curved=0.1,curvedextend=0.05):
'''Produce a parallel coordinates plot from pandas dataframe with line colour with respect to a column.
Required Arguments:
df: dataframe
cols: columns to use for axes
rank_attr: attribute to use for ranking
Options:
cmap: Colour palette to use for ranking of lines
spread: Spread to use to separate lines at categorical values
curved: Spline interpolation along lines
curvedextend: Fraction extension in y axis, adjust to contain curvature
Returns:
x coordinates for axes, y coordinates of all lines'''
colmap = matplotlib.cm.get_cmap(cmap)
cols = cols + [rank_attr]
fig, axes = plt.subplots(1, len(cols)-1, sharey=False, figsize=(3*len(cols)+3,5))#绘制三个子图
valmat = np.ndarray(shape=(len(cols),len(df)))#定义需要绘制曲线的数组有df行,cols列
x = np.arange(0,len(cols),1)#貌似没什么用,有3列那么x=[0,1,2]
ax_info = {}
for i,col in enumerate(cols):#归一化数据
vals = df[col]
if (vals.dtype == float) & (len(np.unique(vals)) > 20):
minval = np.min(vals)
maxval = np.max(vals)
rangeval = maxval - minval#区间长度
vals = np.true_divide(vals - minval, maxval-minval)#归一化处理vals-minval/maxval-minval除法运算
nticks = 5
tick_labels = [round(minval + i*(rangeval/nticks),4) for i in range(nticks+1)]
ticks = [0 + i*(1.0/nticks) for i in range(nticks+1)]
valmat[i] = vals
ax_info[col] = [tick_labels,ticks]
else:
vals = vals.astype('category')#假如是目录型
cats = vals.cat.categories
c_vals = vals.cat.codes
minval = 0
maxval = len(cats)-1
if maxval == 0:
c_vals = 0.5
else:
c_vals = np.true_divide(c_vals - minval, maxval-minval)
tick_labels = cats
ticks = np.unique(c_vals)
ax_info[col] = [tick_labels,ticks]
if spread is not None:
offset = np.arange(-1,1,2./(len(c_vals)))*2e-2
np.random.shuffle(offset)
c_vals = c_vals + offset
valmat[i] = c_vals
extendfrac = curvedextend if curved else 0.05
for i,ax in enumerate(axes):
for idx in range(valmat.shape[-1]):
if curved:
x_new = np.linspace(0, len(x), len(x)*20)
a_BSpline = make_interp_spline(x, valmat[:,idx],k=3,bc_type='clamped')
y_new = a_BSpline(x_new)
ax.plot(x_new,y_new,color=colmap(valmat[-1,idx]),alpha=0.5)
else:
ax.plot(x,valmat[:,idx],color=colmap(valmat[-1,idx]),alpha=0.5)
ax.set_ylim(0-extendfrac,1+extendfrac)
ax.set_xlim(i,i+1)
for dim, (ax,col) in enumerate(zip(axes,cols)):
ax.xaxis.set_major_locator(ticker.FixedLocator([dim]))
ax.yaxis.set_major_locator(ticker.FixedLocator(ax_info[col][1]))
ax_info[col][0] = [int(label) for label in ax_info[col][0]]#y标签下取整
ax.set_yticklabels(ax_info[col][0])
ax.set_xticklabels([cols[dim]])
plt.subplots_adjust(wspace=0)
norm = matplotlib.colors.Normalize(0,1)#*axes[-1].get_ylim())
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
cbar = plt.colorbar(sm,pad=0,ticks=ax_info[rank_attr][1],extend='both',extendrect=True,extendfrac=extendfrac)
#if curved:
#cbar.ax.set_ylim(0-curvedextend,1+curvedextend)
cbar.ax.set_yticklabels(ax_info[rank_attr][0])
cbar.ax.set_xlabel(rank_attr)
plt.show()
return x,valmat
method_names = ['GALCS','GMPSO',"ChaoticOSA","KAMSA","WDNMN"]
data_size = 30
data_index = 50
data_set_name = 'CyberShake'
# 存储所有DataFrame的列表
all_dataframes = []
# 遍历目录下所有的CSV文件
for method_name in method_names:
fileName = 'D://demo//dataset/5.0-5.0/'+str(data_size)+'/'+str(data_size)+data_set_name+str(data_index)+method_name+'_0.csv'
df = read_and_add_method(fileName, method_name)
# 将DataFrame添加到列表中
all_dataframes.append(df)
# 将所有的DataFrame拼接在一起
final_dataframe = pd.concat(all_dataframes, ignore_index=True)
print(final_dataframe)
parallel_plot(final_dataframe,['time','cost','energy'],'method')
# 定义函数,读取CSV文件并添加一个新列'method'
解决了一个问题咯,拜拜咯


















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









