









深度学习中的注意力机制(Attention Mechanism)是一种模仿人类视觉和认知系统的方法,它允许神经网络在处理输入数据时集中注意力于相关的部分。通过引入注意力机制,神经网络能够自动地学习并选择性地关注输入中的重要信息,提高模型的性能和泛化能力。
卷积神经网络引入的注意力机制主要有以下几种方法:
- 在空间维度上增加注意力机制
- 在通道维度上增加注意力机制
- 在两者的混合维度上增加注意力机制
我们将在本系列对多种注意力机制进行讲解,并使用pytorch进行实现,今天我们讲解SENet注意力机制
SENet(Squeeze-and-Excitation Networks)注意力机制在通道维度上引入注意力机制,其核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的 。Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。
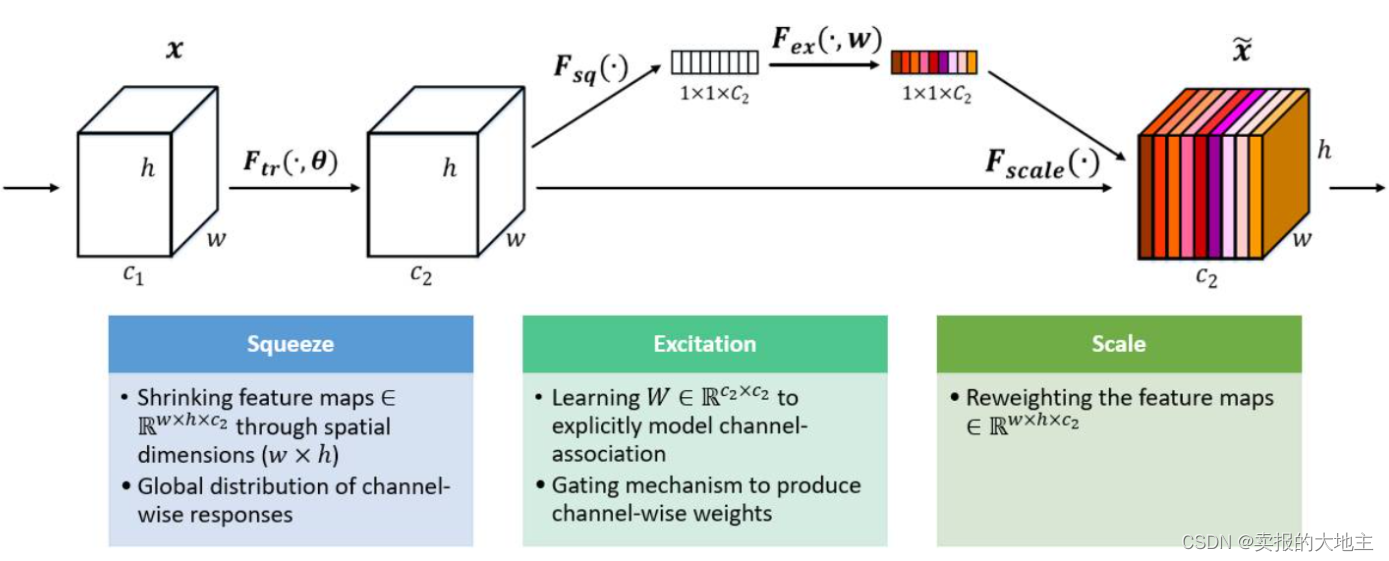
以上是SENet的结构示意图, 其关键操作为squeeze和excitation. 通过自动学习获得特征图在每个通道上的重要程度,以此为不同通道赋予不同的权重,提升有用通道的贡献程度.
实现机制:
- Squeeze: 通过全剧平均池化层,将每个通道大的二维特征(h*w)压缩为一个实数,维度变化: (C, H, W) -> (C, 1, 1)
- Excitation: 给予每个通道的一个特征权重, 然后经过两次全连接层的信息整合提取,构建通道间的自相关性,输出权重数目和特征图通道数一致, 维度变化: (C, 1, 1) -> (C, 1, 1)
- Scale: 将归一化后的权重加权道每个通道的特征上, 论文中使用的是相乘加权, 维度变化: (C, H, W) * (C, 1, 1) -> (C, H, W)
pytorch实现:
class SENet(nn.Module):
def __init__(self, in_channels, ratio=16):
super(SENet, self).__init__()
self.in_channels = in_channels
self.fgp = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Linear(self.in_channels, int(self.in_channels / ratio), bias=False)
self.act1 = nn.ReLU()
self.fc2 = nn.Linear(int(self.in_channels / ratio), self.in_channels, bias=False)
self.act2 = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
output = self.fgp(x)
output = output.view(b, c)
output = self.fc1(output)
output = self.act1(output)
output = self.fc2(output)
output = self.act2(output)
output = output.view(b, c, 1, 1)
return torch.multiply(x, output)



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











