









ECANet(Efficient Channel Attention Network)是一种用于图像处理任务的神经网络架构,它在保持高效性的同时,有效地捕捉图像中的通道间关系,从而提升了特征表示的能力。ECANet通过引入通道注意力机制,以及在卷积层中嵌入该机制,取得了优越的性能。本文将对ECANet的核心思想、结构以及优势进行详细讲解。
1. 核心思想
ECANet的核心思想是在卷积操作中引入通道注意力机制,以捕捉不同通道之间的关系,从而提升特征表示的能力。通道注意力机制的目标是自适应地调整通道特征的权重,使得网络可以更好地关注重要的特征,抑制不重要的特征。通过这种机制,ECANet能够在不增加过多参数和计算成本的情况下,有效地增强网络的表征能力。
2. 结构
ECANet的结构主要分为两个部分:通道注意力模块和嵌入式通道注意力模块。
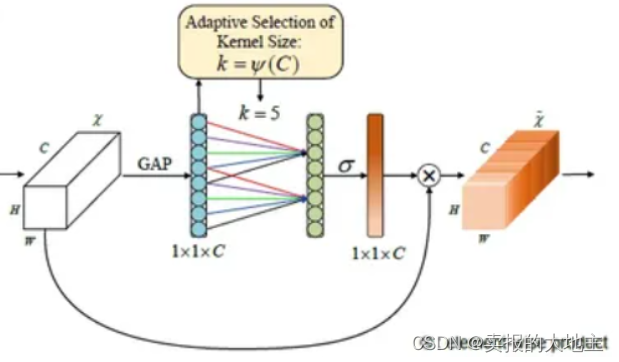
通道注意力模块是ECANet的核心组成部分,它的目标是根据通道之间的关系,自适应地调整通道特征的权重。该模块的输入是一个特征图(Feature Map),通过全局平均池化得到每个通道的全局平均值,然后通过一组全连接层来生成通道注意力权重。这些权重被应用于输入特征图的每个通道,从而实现特征图中不同通道的加权组合。最后,通过一个缩放因子对调整后的特征进行归一化,以保持特征的范围。
嵌入式通道注意力模块是ECANet的扩展部分,它将通道注意力机制嵌入到卷积层中,从而在卷积操作中引入通道关系。这种嵌入式设计能够在卷积操作的同时,进行通道注意力的计算,减少了计算成本。具体而言,在卷积操作中,将输入特征图划分为多个子特征图,然后分别对每个子特征图进行卷积操作,并在卷积操作的过程中引入通道注意力。最后,将这些卷积得到的子特征图进行合并,得到最终的输出特征图。
实现机制:
-
通过全剧平均池化层,将每个通道大的二维特征(h*w)压缩为一个实数, 特征图维变化: (C, H, W) -> (C, 1, 1)
-
计算得到自适应的一维卷积核的kernel_size,计算公式如下:
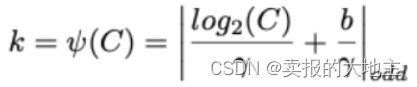
其中
b
=
1
γ
=
2
C
为通道数
b = 1 \\ \gamma = 2\\ C为通道数
b=1γ=2C为通道数
- 将kernel_size = k的一维卷积核(一维same核)用于特征图,得到每个通道的权重向量, 维度变化(C, 1, 1) -> (C, 1, 1).
- 将归一化后的权重加权乘以输入特征图 (C, H, W) * (C, 1, 1) -> (C, H, W)
3. 优势
ECANet的设计在以下几个方面具有优势:
ECANet通过嵌入式通道注意力模块,在保持高效性的同时,引入了通道注意力机制。这使得网络能够在不增加过多计算成本的情况下,提升特征表示的能力。
通道注意力机制能够自适应地调整通道特征的权重,使得网络能够更好地关注重要的特征。这种机制有助于提升特征的判别能力,从而提升了网络的性能。
通道注意力机制有助于抑制不重要的特征,从而减少了过拟合的风险。网络更加关注重要的特征,有助于提高泛化能力。
4. 代码实现
class ECANet(nn.Module):
def __init__(self, in_channels, gamma=2, b=1):
super(ECANet, self).__init__()
self.in_channels = in_channels
self.fgp = nn.AdaptiveAvgPool2d((1, 1))
kernel_size = int(abs((math.log(self.in_channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.con1 = nn.Conv1d(1,
1,
kernel_size=kernel_size,
padding=(kernel_size - 1) // 2,
bias=False)
self.act1 = nn.Sigmoid()
def forward(self, x):
output = self.fgp(x)
output = output.squeeze(-1).transpose(-1, -2)
output = self.con1(output).transpose(-1, -2).unsqueeze(-1)
output = self.act1(output)
output = torch.multiply(x, output)
return output
总结
ECANet是一种高效的神经网络架构,通过引入通道注意力机制,能够有效地捕捉图像中的通道关系,提升特征表示的能力。它的结构包括通道注意力模块和嵌入式通道注意力模块,具有高效性、提升特征表示和减少过拟合等优势。通过这种设计,ECANet在图像处理任务中取得了优越的性能。
















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











