







逻辑回归算法
一、逻辑回归(LR)基本概念
1. 引入背景
1.1 概述logistics回归
Logistics回归是一种分类算法,面对一个分类问题,建立代价函数,通过优化方法求解出最优的模型参数,之后验证模型的好坏。logistics回归主要用于二分类问题,本文也集中介绍二分类的logistics回归模型。
(Tips:logistics回归也可以用于多分类问题,从logistics推导出softmax,在文末有相关参考资料)
1.2 模型引入
在二分类问题中,因变量y有“是”、“否”两个取值,可记作1和0。假设在自变量 x 1 x_{1} x1 、 x 2 x_{2} x2 、 x 3 x_{3} x3 、…、 x p x_{p} xp 作用下(自变量 x i x_{i} xi 即为特征),y取“是”的概率为p,取“否”的概率为1-p,logistics回归模型研究的便是当y取“是”发生的概率p与自变量 x 1 x_{1} x1 , x 2 x_{2} x2 , x 3 x_{3} x3 ,…, x p x_{p} xp之间的关系。当p>0.5时,y取1,当p<0.5时,y取0,所以logistics回归本质上求解的还是概率问题。
结合Regression常规步骤:
- 寻找h函数(即预测函数)
- 构造J函数(即损失函数)
- 想办法最小化J函数并求得回归参数 Θ \Theta Θ
对logistics回归的过程进行阐述:
1.3 构造h函数(预测函数)
上文已经说明,logistics回归研究的是y取“是”发生的概率p与自变量
x
i
x_{i}
xi之间的关系。在此基础上,提出事件的“优势比”(odds)概念,即
o
d
d
s
=
p
1
−
p
odds=\frac{p}{1-p}
odds=1−pp,对odds取自然对数即得logistics变换
L
o
g
i
t
(
p
)
=
ln
p
1
−
p
Logit(p)=\ln \dfrac{p}{1-p}
Logit(p)=ln1−pp,当p在(0,1)之间变化时,odds的取值范围为(0,+∞),则
l
o
g
i
t
(
p
)
logit(p)
logit(p) 的取值范围是(-∞,+∞),logistics回归模型就是建立
l
o
g
i
t
(
p
)
logit(p)
logit(p)与自变量
x
i
x_{i}
xi 的线性回归模型:
ln
p
1
−
p
=
Θ
0
x
0
+
Θ
1
x
1
+
Θ
2
x
2
+
.
.
.
+
Θ
p
x
p
+
ε
,
右
式
记
作
g
(
x
)
\ln \frac{p}{1-p} =\Theta _{0}x_{0} +\Theta _{1}x_{1} +\Theta _{2}x_{2}+...+\Theta _{p}x_{p}+\varepsilon,右式记作g(x)
ln1−pp=Θ0x0+Θ1x1+Θ2x2+...+Θpxp+ε,右式记作g(x)。Tips:在数据预处理中,通常加一项特征
x
0
x_{0}
x0,且令
x
0
=
1
x_{0}=1
x0=1。基于上述公式,便得到了p与
x
x
x之间的关系:
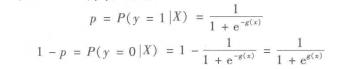
上式中
g
(
z
)
=
1
1
+
e
−
z
g\left( z\right) =\dfrac{1}{1+e^{-z}}
g(z)=1+e−z1叫做sigmod函数,也称为logistics函数,图像如下:

sigmod函数是一种阶跃函数,能够很好地把概率值映射到0~1之间。

以上就是构造预测函数的整个思维过程。
Tips:从这一层意义上说,logistics回归在本质上依然是线性回归模型,只是在最后加了一层连接函数——sigmod函数,使概率值非线性地映射到了(0,1)之间,这种模型称为“广义线性模型”。具体资料参考文末相关链接。
所以与SVM、神经网络等非线性分类器相比,如果要针对大规模数据进行快速分类预测,logistics回归具有相当大的时间优势。
1.4 构造损失函数J并最小化J
学习资料:
- https://blog.csdn.net/zjuPeco/article/details/77165974?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
- https://blog.csdn.net/weixin_41960890/article/details/104939240?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159474045019724843307052%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159474045019724843307052&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v3~pc_rank_v2-2-104939240.first_rank_ecpm_v3_pc_rank_v2&utm_term=%E5%A6%82%E4%BD%95%E4%BB%8E%E5%AF%B9%E6%95%B0%E4%BC%BC%E7%84%B6%E7%9A%84%E8%A7%92%E5%BA%A6%E7%90%86%E8%A7%A3logistics%E5%9B%9E%E5%BD%92
- https://blog.csdn.net/geeksu/article/details/78061881?biz_id=102&utm_term=%E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92%E7%9A%84%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E7%AE%97%E6%B3%95&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-2-78061881&spm=1018.2118.3001.4187【线性回归中的代价函数推导,与逻辑回归中的代价函数作对比学习】
关键点:
- 损失函数针对的是单个样本,代价函数针对的是整个样本集合;
- logistics回归的代价函数是基于极大似然估计理论得出的,求样本集合的似然函数的最大值,就相当于找代价函数的最小值,采用梯度下降/梯度上升算法来求出最佳的参数 Θ \Theta Θ。
- Logistic回归只是在线性回归上增加了一个 g(x) 的限制,而在模型训练的过程中实际上还是对线性回归中的 Θ \Theta Θ进行训练。我们是怎么对线性回归中的 Θ \Theta Θ进行计算的?梯度下降/上升!要使用梯度下降/上升,就存在一个前提,即损失函数可导。而以 Sign函数 为假设函数列出来的损失函数明显在 x = 0 x=0 x=0处不可导(左导 = 0,右导 = 1)。而反观 Sigmoid函数,在(+∞,-∞)内均有导数存在,这也是选择sigmod函数作为激活函数的原因之一。
- logistics回归模型的损失函数称为“交叉熵损失函数”,是通过极大似然估计得出来的。至于为什么不能用线性回归常用的误差平方和的损失函数,可以从两个方面考虑:一是sigmod函数代入误差平方和公式中得到的函数是非凸函数,容易得到局部最小值,不利于求解;二是LR的损失函数是从极大似然估计的角度得出的。
1.5 总结

1.6 Logistics回归的梯度上升算法之Python代码实现
1.6.1 批量梯度上升算法GD
伪代码
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用$alpha$*$gradient$更新回归系数的向量
返回回归系数

1.6.2 随机梯度上升算法SGD
伪代码
每个回归系数初始化为1
重复R次:
对数据集中每个样本:
计算该样本的梯度
使用$alpha$*$gradient$更新回归系数的向量
返回回归系数

1.6.3 小批量随机梯度上升算法MSGD
关键点:加入了batch_size参数,一次对小批量的样本求平均梯度值进行迭代。代码具体实现后续。
2. 调用Python的sklearn.linear_model中的LogisticsRegression库
关键点在于正则化参数的选择,以及对应的优化方法选择、参数设置,这里不再赘述。
3. 相关资料
1. 广义线性模型GLM
一个GLM包含三个要素:
1.指数族的概率分布。
学习资料:https://blog.csdn.net/touristman5/article/details/57402762
2.一个线性预测器,如
η
=
X
∗
β
\eta =X*\beta
η=X∗β 。
3.一个连接函数
g
g
g,如sigmod函数。















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









