







鸢尾花例子
- Iris数据集包含scikit-learn的datasets模块中
from sklearn.datasets import load_iris #导入
iris_dataset=load_iris() #load_iris()返回的对象是一个Bunch对象,类似于字典,包含键和值
- 查看数据集的基本信息
输出数据中的键
DESCR键对应的值是数据集的简要说明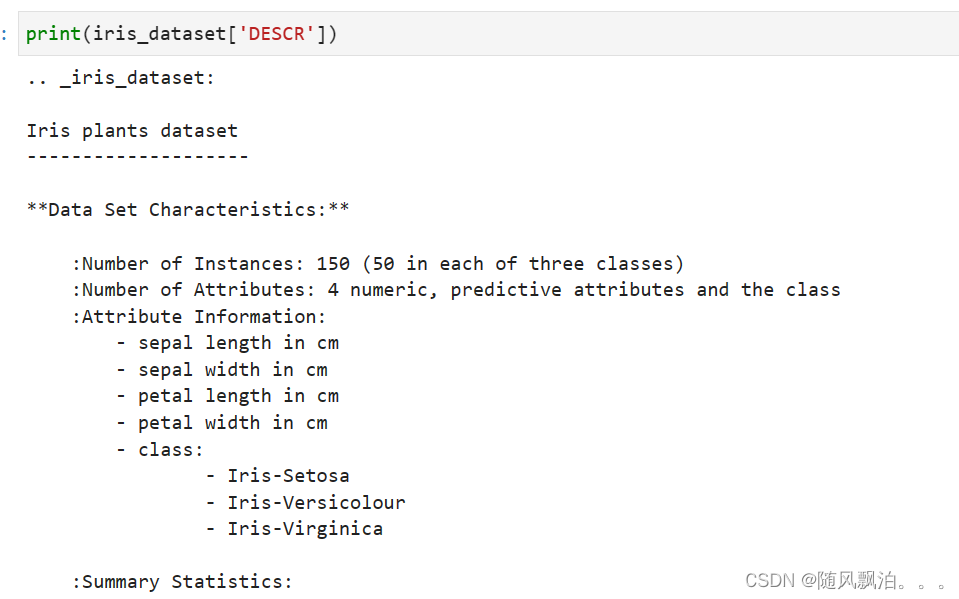
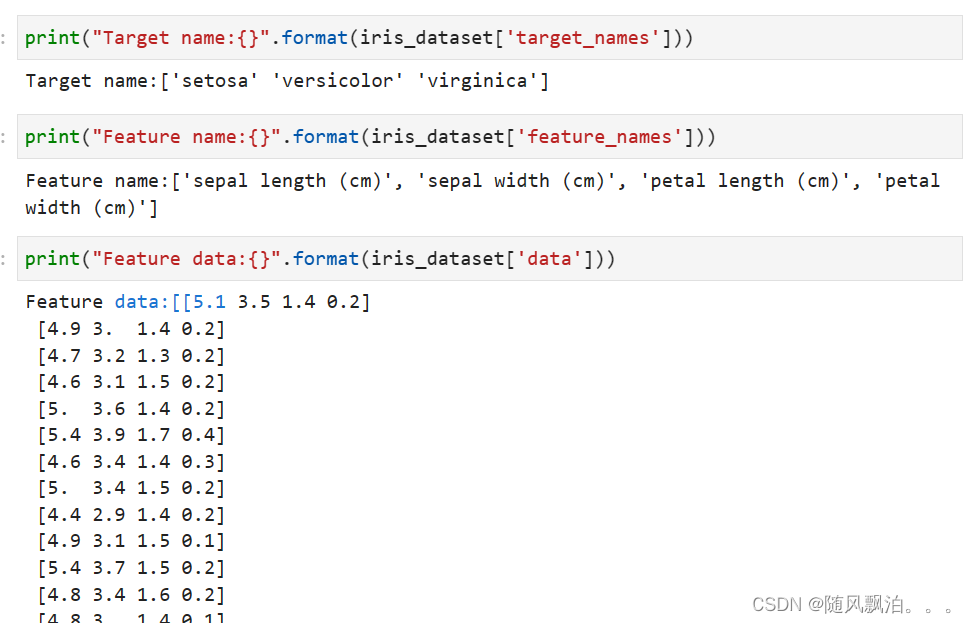
数组的形状(shape)是样本数乘以特征数
- 训练集和测试集
scikit-learn中的train-test-split 函数可以打乱数据集并进行拆分。
数据通常用大写的X,标签用小写的y表示。
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(
iris_dataset['data'],iris_dataset['target'],random_state=100)
- 构建模型
k近邻算法:需要用k近邻分类器,构建模型,需要保存训练集即可。即对一个新的数据点做出预测,算法会在训练集中寻找与这个新数据点距离最近的数据点,然后将找到的数据点的标签赋值给这个新数据点。
k近邻算法
from sklearn.neighbors import KNeighborsClassifier #
knn=KNeighborsClassifier(n_neighbors=2) #识别k个最近的点
knn.fit(X_train,y_train)
prediction=knn.predict(X_new) #做出预测
print("Prediction:{}".format(prediction))
print("Predicted target name:{}".format(
iris_dataset['target_names'][prediction]))
#评估模型
y_pred=knn.predict(X_test)
print("test set prediction:\n{}".format(y_pred))
print("Test set score:{:.2f}".format(np.mean(y_pred==y_test)))
#计算精度,即预测正确的话所占的比例
print("Test set score:{:.2f}".format(knn.score(X_test,y_test)))
#
- isinstance
isinstance是Python内置的一个函数,用于判断一个对象是否属于指定的类型。根据引用和引用的示例,可以看出isinstance函数的用法是isinstance(object, class),其中object是待判断的对象,class是指定的类型。如果对象是指定类型的实例,则返回True,否则返回False。
根据引用中的代码和输出结果,我们可以得出以下结论:
对于w这个对象,isinstance(w, Person)返回True,表示w是Person类型的实例。
由于Man是Person的子类,所以isinstance(w, Man)返回False,表示w不是Man类型的实例。
Woman是Person的子类,所以isinstance(w, Woman)返回True,表示w是Woman类型的实例。
最后,由于所有的类都是object的子类,所以isinstance(w, object)返回True,表示w是object类型的实例。
综上所述,根据继承链的类型转换,我们可以得出w的类型分别为Person、Woman、object
- print
print("Integer: %d" % myint)
http://t.csdn.cn/9zgra
https://learnpython.org/en/String_Formatting
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









